音频驱动三维人脸动画模型的生成方法、装置及设备与流程
本技术涉及音频处理,特别涉及一种音频驱动三维人脸动画模型的生成方法、装置及设备。
背景技术:
1、语音驱动表情技术的研究是自然人机交互领域的重要内容,具体而言,即通过语音驱使数字形象以该语音对应的面部表情阐述相应的语音内容,进而生成相应的动画。语音驱动表情技术的核心在于混合变形值(blendshapes值,简称bs值)的计算与输出。具体而言,对用户录音或者tts合成的语音进行预处理,输出bs值,基于该bs值即可用于驱动数字形象,产生与语音对应的面部表情动画,然后通过渲染技术呈现在各种显示设备上。
2、相关技术中,在动画、影视等作品制作过程中,时常需要后期修改台词,但是,由于修改台词后导致的音画不同步现象会严重降低影视作品的效果,因此,相关技术中通过重新拍摄,或通过后期制作并加以渲染等方式进行处理,但上述方式均存在代价极高的问题。为了克服前述问题,相关技术通过音频驱动三维人脸动画技术实现修改台词,也即通过修改后的台词所对应的音频驱动原形象,生成与修改后的台词对应的面部表情动画。
3、但是,上述语音驱动表情技术所输出的bs值存在诸如口型动作与语音并不对应,表情动作的自然度不佳等一系列问题,从而降低了音频驱动三维人脸动画技术的精准度。
技术实现思路
1、为了解决上述技术问题,本技术实施例提供了一种音频驱动三维人脸动画模型的生成方法、装置及设备,能够提高音频驱动三维人脸动画技术的精准度。该技术方案如下:
2、根据本技术实施例的第一方面,提供了一种音频驱动三维人脸动画模型的生成方法,该方法包括:
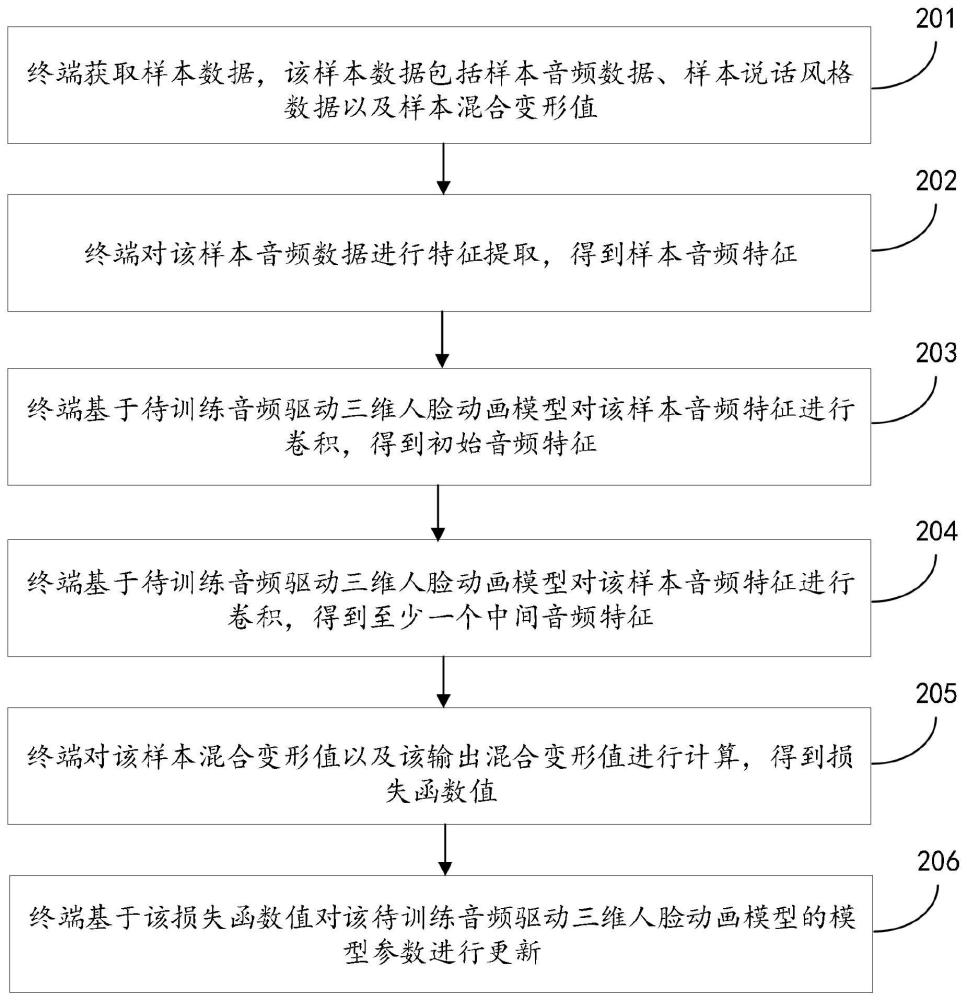
3、获取样本数据,该样本数据包括样本音频数据、样本说话风格数据以及样本混合变形值,该样本音频数据与该样本说话风格数据属于相同用户,所述样本说话风格数据用于描述用户的面部表情,该样本混合变形值是对该样本音频数据进行预处理得到的;
4、对该样本音频数据进行特征提取,得到样本音频特征;
5、基于待训练音频驱动三维人脸动画模型对该样本音频特征进行卷积,得到初始音频特征;以及基于该待训练音频驱动三维人脸动画模型对该样本说话风格数据进行编码,得到样本说话风格特征;
6、基于该待训练音频驱动三维人脸动画模型对该初始音频特征以及该样本说话风格特征进行编码,得到输出混合变形值;
7、对该样本混合变形值以及该输出混合变形值进行计算,得到损失函数值;
8、基于该损失函数值对该待训练音频驱动三维人脸动画模型的模型参数进行更新。
9、在第一方面的一种可能的实现方式中,该对该样本音频数据进行特征提取,得到样本音频特征,包括:
10、基于预设模型对该样本音频数据进行特征提取,将该预设模型的中间层的特征作为该样本音频特征。
11、在第一方面的一种可能的实现方式中,该基于待训练音频驱动三维人脸动画模型对该样本音频特征进行卷积,得到初始音频特征,包括:
12、基于待训练音频驱动三维人脸动画模型对该样本音频特征进行卷积,得到至少一个中间音频特征;
13、对该至少一个中间音频特征进行间隔计算,得到该样本音频特征。
14、在第一方面的一种可能的实现方式中,该对该至少一个中间音频特征进行间隔计算,得到该样本音频特征,包括:
15、基于该待训练音频驱动三维人脸动画模型对该至少一个中间音频特征中每两个中间音频特征进行匹配,得到与该至少一个中间音频特征中每两个中间音频特征对应的中间音频特征组;其中,该至少一个中间音频特征中每个中间音频特征对应一个卷积计算通道,该中间音频特征组对应的两个卷积计算通道的序列值不相邻;
16、基于该待训练音频驱动三维人脸动画模型对至少一个中间音频特征组中每个中间音频特征组中两个中间音频特征进行合并,得到与至少一个中间音频特征组中每个中间音频特征组对应的中间合并特征;
17、基于该待训练音频驱动三维人脸动画模型对至少一个中间合并特征中每个中间合并特征进行计算,得到该样本音频特征。
18、在第一方面的一种可能的实现方式中,该基于该待训练音频驱动三维人脸动画模型对该样本说话风格数据进行编码,得到样本说话风格特征,包括:
19、基于该待训练音频驱动三维人脸动画模型对该样本说话风格数据进行独热编码,得到该样本说话风格特征。
20、在第一方面的一种可能的实现方式中,该基于该待训练音频驱动三维人脸动画模型对该初始音频特征以及该样本说话风格特征进行编码,得到输出混合变形值,包括:
21、基于该待训练音频驱动三维人脸动画模型对该样本音频特征以及该样本说话风格特征进行叠加,得到样本叠加特征;
22、基于该待训练音频驱动三维人脸动画模型对该样本叠加特征进行编码,得到该输出混合变形值。
23、在第一方面的一种可能的实现方式中,该基于该待训练音频驱动三维人脸动画模型对该样本叠加特征进行编码,得到该输出混合变形值,包括:
24、基于该待训练音频驱动三维人脸动画模型对该样本叠加特征进行编码,得到样本编码特征;
25、基于该待训练音频驱动三维人脸动画模型对该样本编码特征进行解码,得到输出混合变形值。
26、根据本技术实施例的第二方面,提供了一种音频驱动三维人脸动画模型的生成装置,该装置包括:
27、获取模块,用于获取样本数据,该样本数据包括样本音频数据、样本说话风格数据以及样本混合变形值,该样本音频数据与该样本说话风格数据属于相同用户,所述样本说话风格数据用于描述用户的面部表情,该样本混合变形值是对该样本音频数据进行预处理得到的;
28、特征提取模块,用于对该样本音频数据进行特征提取,得到样本音频特征;
29、第一训练模块,用于基于待训练音频驱动三维人脸动画模型对该样本音频特征进行卷积,得到初始音频特征;以及基于该待训练音频驱动三维人脸动画模型对该样本说话风格数据进行编码,得到样本说话风格特征;
30、第二训练模块,用于基于该待训练音频驱动三维人脸动画模型对该初始音频特征以及该样本说话风格特征进行编码,得到输出混合变形值;
31、计算模块,用于对该样本混合变形值以及该输出混合变形值进行计算,得到损失函数值;
32、更新模块,用于基于该损失函数值对该待训练音频驱动三维人脸动画模型的模型参数进行更新。
33、在第二方面的一种可能的实现方式中,该特征提取模块,包括:
34、特征提取单元,用于基于预设模型对该样本音频数据进行特征提取,将该预设模型的中间层的特征作为该样本音频特征。
35、在第二方面的一种可能的实现方式中,该第一训练模块,包括:
36、卷积单元,用于基于待训练音频驱动三维人脸动画模型对该样本音频特征进行卷积,得到至少一个中间音频特征;
37、间隔计算单元,用于对该至少一个中间音频特征进行间隔计算,得到该样本音频特征。
38、在第二方面的一种可能的实现方式中,该间隔计算单元,包括:
39、第一匹配子单元,用于基于该待训练音频驱动三维人脸动画模型对该至少一个中间音频特征中每两个中间音频特征进行匹配,得到与该至少一个中间音频特征中每两个中间音频特征对应的中间音频特征组;其中,该至少一个中间音频特征中每个中间音频特征对应一个卷积计算通道,该中间音频特征组对应的两个卷积计算通道的序列值不相邻;
40、合并子单元,用于基于该待训练音频驱动三维人脸动画模型对至少一个中间音频特征组中每个中间音频特征组中两个中间音频特征进行合并,得到与至少一个中间音频特征组中每个中间音频特征组对应的中间合并特征;
41、计算子单元,用于基于该待训练音频驱动三维人脸动画模型对至少一个中间合并特征中每个中间合并特征进行计算,得到该样本音频特征。
42、在第二方面的一种可能的实现方式中,该第一训练模块,包括:
43、独热编码模块,用于基于该待训练音频驱动三维人脸动画模型对该样本说话风格数据进行独热编码,得到该样本说话风格特征。
44、在第二方面的一种可能的实现方式中,该第二训练模块,包括:
45、叠加单元,用于基于该待训练音频驱动三维人脸动画模型对该样本音频特征以及该样本说话风格特征进行叠加,得到样本叠加特征;
46、编码单元,用于基于该待训练音频驱动三维人脸动画模型对该样本叠加特征进行编码,得到该输出混合变形值。
47、在第二方面的一种可能的实现方式中,该编码单元,包括:
48、编码子单元,用于基于该待训练音频驱动三维人脸动画模型对该样本叠加特征进行编码,得到样本编码特征;
49、解码子单元,用于基于该待训练音频驱动三维人脸动画模型对该样本编码特征进行解码,得到输出混合变形值。
50、根据本技术实施例的第三方面,提供了一种电子设备,该电子设备包括处理器和存储器,该存储器用于存储至少一段程序,该至少一段程序由该处理器加载并执行如上述第一方面提供的音频驱动三维人脸动画模型的生成方法。
51、根据本技术实施例的第四方面,提供了一种计算机可读存储介质,其特征在于,该计算机可读存储介质中存储有至少一段程序,该至少一段程序由处理器加载并执行以实现如上述第一方面提供的音频驱动三维人脸动画模型的生成方法。
52、根据本技术实施例的第五方面,提供了一种包含计算机指令的计算机程序产品,当计算机指令在电子设备上运行时,使得电子设备实现如上述第一方面提供的音频驱动三维人脸动画模型的生成方法。
53、在本技术中,上述名称对设备或功能模块本身不构成限定,在实际实现中,这些设备或功能模块可以以其他名称出现。只要各个设备或功能模块的功能和本技术类似,属于本技术权利要求及其等同技术的范围之内。
54、本技术的这些方面或其他方面在以下的描述中会更加简明易懂。
55、在本技术实施例中,本技术实施例提供了一种音频驱动三维人脸动画模型的生成方法,获取用户的样本数据,样本数据包括样本音频数据、样本说话风格数据以及与样本音频数据对应的样本混合变形值,其中,样本说话风格数据描述用户的面部表情数据,以将用户的个性化数据与样本音频数据进行融合,且尽可能地保留了用户的个性化数据。基于样本数据对待训练音频驱动三维人脸动画模型进行训练,得到的训练好的音频驱动三维人脸动画模型,可以输出高精准度的bs值,从而提高了音频驱动三维人脸动画技术的精准度。此外,将输出的高精准度的bs值输入至预设的虚幻引擎,使得预设的虚幻引擎可以将高精度的口型和面部表情渲染至视频显示设备上,从而同时实现口型和面部表情的高精度复现,进而可以将音频驱动三维人脸动画技术广泛应用于影视作品制作等对表情精度需求较高的场景。
- 还没有人留言评论。精彩留言会获得点赞!