模型训练的方法、对象推荐的方法、装置、设备及介质与流程
本技术属于计算机,具体而言,本技术涉及一种模型训练的方法、对象推荐的方法、装置、设备及介质。
背景技术:
1、在对象推荐的业务中,例如针对实时接口(real-time api,rta)广告业务,合作商家的数据链路出于隐私原因不会被全部地获取到,导致只能获取到点击数据,而后面的转化数据,全由商家提供。而转化数据由于量少,经常存在特征分布异常,比如某些特征的某个取值的分布异常,模型在学习过程中严重倾向该特征,导致模型泛化性能很弱。比如在某面向85后的游戏商家,年龄为85后的人群特征重要性特别高,模型会严重倾向于年龄特征,导致泛化能力弱。
2、出现这种异常的原因可能是符合业务的分布异常所导致的,因此,如何在符合业务的分布异常的情况下,模型泛化能力弱的问题。
技术实现思路
1、本技术实施例的目的旨在提供一种能够在缓解符合业务的分布异常的情况下提升模型泛化能力的模型训练的方法、对象推荐的方法、装置、设备及介质。为了实现上述目的,本技术实施例提供的技术方案如下:
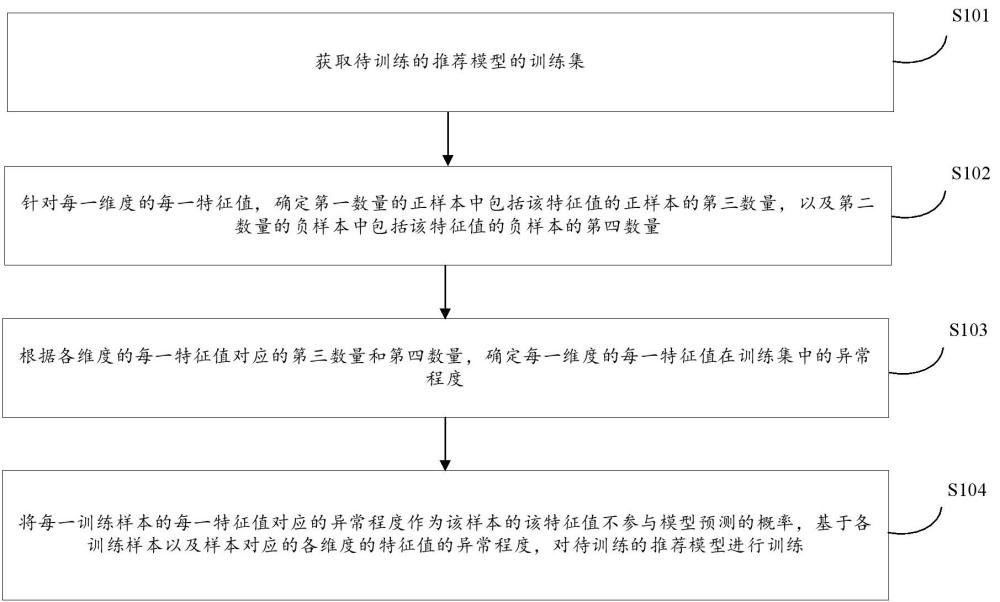
2、第一方面,提供了一种模型训练的方法,包括:
3、获取待训练的推荐模型的训练集,所述训练集包括多个训练样本,所述多个训练样本包括第一数量的正样本和第二数量的负样本,每个所述训练样本包括一个样本对象的对象特征,所述对象特征包括至少两个维度的特征值,其中,所述正样本为样本对象对被推荐对象感兴趣的样本,所述待训练的推荐模型用于预测训练样本对应的样本对象对被推荐对象感兴趣的概率;
4、针对每一维度的每一特征值,确定所述第一数量的正样本中包括该特征值的正样本的第三数量,以及所述第二数量的负样本中包括该特征值的负样本的第四数量;
5、根据各维度的每一特征值对应的第三数量和第四数量,确定每一维度的每一特征值在所述训练集中的异常程度;
6、将每一所述训练样本的每一特征值对应的异常程度作为该样本的该特征值不参与模型预测的概率,基于各所述训练样本以及样本对应的各维度的特征值的异常程度,对所述待训练的推荐模型进行训练。
7、在一种可能的实现方式中,所述根据各维度的每一特征值对应的第三数量和第四数量,确定每一维度的每一特征值在所述训练集中的异常程度,包括:
8、针对每一维度的每一特征值,根据所述第一数量和该特征值对应的第三数量,确定包含该特征值的正样本在所述训练集的正样本中的第一占比,根据所述第二数量和该特征值对应的所述第四数量,确定包含该特征值的负样本在所述训练集的负样本中的第二占比,根据所述第一占比和所述第二占比,确定该特征值的目标信息价值iv值;
9、针对每一维度的每一特征值,根据该特征值对应的第三数量和第四数量,确定包含该特征值的正样本在包含该特征值的所有样本中的第三占比;
10、获取每一维度对应的正样本占比第一参考值和正样本占比第二参考值;
11、针对每一维度的每一特征值,根据该特征值对应的第三占比和该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率目标偏移值;
12、针对每一维度的每一特征值,根据该特征值对应的iv值和该特征值的正样本率目标偏移值,确定该特征值在所述训练集中的异常程度。
13、在另一种可能的实现方式中,根据该特征值对应的第三占比和该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率目标偏移值,包括:
14、根据该特征值对应的第三占比、该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率初始偏移值;
15、获取所述推荐模型所应用的目标场景所对应的特征值的正样本率偏移阈值;
16、若该特征值的正样本率初始偏移值不小于所述正样本率偏移阈值,则将该特征值的正样本率初始偏移值确定为该特征值的正样本率目标偏移值;
17、若该特征值的正样本率初始偏移值小于所述正样本率偏移阈值,则确定该特征值的正样本率目标偏移值为0。
18、在另一种可能的实现方式中,对于每一维度,该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值是采用以下方式确定的:
19、确定各维度分别对应的第四占比,任一维度对应的第四占比为该维度的各个特征值所包含的正样本总数量在该维度的各个特征值所包含的样本总数量的第四占比;
20、将各维度分别对应的第四占比的均值确定为所述该维度对应的正样本占比第一参考值;
21、将各维度分别对应的第四占比的标准差确定为所述该维度对应的正样本占比第二参考值。
22、在另一种可能的实现方式中,根据该特征值对应的第三占比和该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率目标偏移值,包括:
23、确定所述第三占比和所述第一参考值之间的差值;
24、根据所述差值和所述第二参考值的比值,确定该特征值的正样本率目标偏移值。
25、在另一种可能的实现方式中,所述根据所述第一占比和所述第二占比,确定该特征值的目标信息价值iv值,包括:
26、确定所述第一占比和所述第二占比之间的差值;
27、根据所述差值,确定该特征值的目标iv值。
28、在另一种可能的实现方式中,所述根据所述差值,确定该特征值的目标iv值,包括:
29、根据所述差值,确定该特征值的初始iv值;
30、获取所述推荐模型所应用的目标场景所对应的特征值的iv阈值;
31、若所述初始iv值大于所述iv阈值,则将所述初始iv值确定为所述目标iv值;
32、若所述初始iv值不大于所述iv阈值,则将所述目标iv值确定为0。
33、在另一种可能的实现方式中,所述将每一所述训练样本的每一特征值对应的异常程度作为该样本的该特征值不参与模型预测的概率,基于各所述训练样本以及样本对应的各维度的特征值的异常程度,对所述待训练的推荐模型进行训练,包括:
34、计算所述每一特征值对应的嵌入特征;
35、基于所述概率断开与该特征值所属维度所对应的神经元的连接;
36、基于所述每一特征值对应的嵌入特征对断开处理后的模型进行训练。
37、第二方面,提供了一种对象推荐的方法,包括:
38、获取各个对象分别对应的对象特征;
39、基于所述各个对象分别对应的对象特征,并通过训练后的推荐模型,预测各个对象对被推荐对象的感兴趣程度;
40、基于所述各个对象对被推荐对象的感兴趣程度,确定是否为对象推荐所述被推荐对象;
41、其中,所述训练后的推荐模型是通过第一方面或者第一方面的任一种可能的实现方式所述的基于异常特征处理的模型训练方法所得到的。
42、第三方面,提供了一种模型训练的装置,包括:
43、训练集获取模块,用于获取待训练的推荐模型的训练集,所述训练集包括多个训练样本,所述多个训练样本包括第一数量的正样本和第二数量的负样本,每个所述训练样本包括一个样本对象的对象特征,所述对象特征包括至少两个维度的特征值,其中,所述正样本为样本对象对被推荐对象感兴趣的样本,所述待训练的推荐模型用于预测训练样本对应的样本对象对被推荐对象感兴趣的概率;
44、第一确定模块,用于针对每一维度的每一特征值,确定所述第一数量的正样本中包括该特征值的正样本的第三数量,以及所述第二数量的负样本中包括该特征值的负样本的第四数量;
45、第二确定模块,用于根据各维度的每一特征值对应的第三数量和第四数量,确定每一维度的每一特征值在所述训练集中的异常程度;
46、训练模块,用于将每一所述训练样本的每一特征值对应的异常程度作为该样本的该特征值不参与模型预测的概率,基于各所述训练样本以及样本对应的各维度的特征值的异常程度,对所述待训练的推荐模型进行训练。
47、在一种可能的实现方式中,所述第二确定模块在根据各维度的每一特征值对应的第三数量和第四数量,确定每一维度的每一特征值在所述训练集中的异常程度时,具体用于:
48、针对每一维度的每一特征值,根据所述第一数量和该特征值对应的第三数量,确定包含该特征值的正样本在所述训练集的正样本中的第一占比,根据所述第二数量和该特征值对应的所述第四数量,确定包含该特征值的负样本在所述训练集的负样本中的第二占比,根据所述第一占比和所述第二占比,确定该特征值的目标信息价值iv值;
49、针对每一维度的每一特征值,根据该特征值对应的第三数量和第四数量,确定包含该特征值的正样本在包含该特征值的所有样本中的第三占比;
50、获取每一维度对应的正样本占比第一参考值和正样本占比第二参考值;
51、针对每一维度的每一特征值,根据该特征值对应的第三占比和该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率目标偏移值;
52、针对每一维度的每一特征值,根据该特征值对应的iv值和该特征值的正样本率目标偏移值,确定该特征值在所述训练集中的异常程度。
53、在另一种可能的实现方式中,所述第二确定模块在根据该特征值对应的第三占比和该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率目标偏移值时,具体用于:
54、根据该特征值对应的第三占比、该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率初始偏移值;
55、获取所述推荐模型所应用的目标场景所对应的特征值的正样本率偏移阈值;
56、若该特征值的正样本率初始偏移值不小于所述正样本率偏移阈值,则将该特征值的正样本率初始偏移值确定为该特征值的正样本率目标偏移值;
57、若该特征值的正样本率初始偏移值小于所述正样本率偏移阈值,则确定该特征值的正样本率目标偏移值为0。
58、在另一种可能的实现方式中,对于每一维度,该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值是采用以下方式确定的:
59、确定各维度分别对应的第四占比,任一维度对应的第四占比为该维度的各个特征值所包含的正样本总数量在该维度的各个特征值所包含的样本总数量的第四占比;
60、将各维度分别对应的第四占比的均值确定为所述该维度对应的正样本占比第一参考值;
61、将各维度分别对应的第四占比的标准差确定为所述该维度对应的正样本占比第二参考值。
62、在另一种可能的实现方式中,所述第二确定模块在根据该特征值对应的第三占比和该维度对应的正样本占比第一参考值和该维度对应的正样本占比第二参考值,确定该特征值的正样本率目标偏移值时,具体用于:
63、确定所述第三占比和所述第一参考值之间的差值;
64、根据所述差值和所述第二参考值的比值,确定该特征值的正样本率目标偏移值。
65、在另一种可能的实现方式中,所述第二确定模块在根据所述第一占比和所述第二占比,确定该特征值的目标信息价值iv值时,具体用于:
66、确定所述第一占比和所述第二占比之间的差值;
67、根据所述差值,确定该特征值的目标iv值。
68、在另一种可能的实现方式中,所述第二确定模块在根据所述差值,确定该特征值的目标iv值时,具体用于:
69、根据所述差值,确定该特征值的初始iv值;
70、获取所述推荐模型所应用的目标场景所对应的特征值的iv阈值;
71、若所述初始iv值大于所述iv阈值,则将所述初始iv值确定为所述目标iv值;
72、若所述初始iv值不大于所述iv阈值,则将所述目标iv值确定为0。
73、在另一种可能的实现方式中,所述训练模块在所述将每一所述训练样本的每一特征值对应的异常程度作为该样本的该特征值不参与模型预测的概率,基于各所述训练样本以及样本对应的各维度的特征值的异常程度,对所述待训练的推荐模型进行训练时,具体用于:
74、计算所述每一特征值对应的嵌入特征;
75、基于所述概率断开与该特征值所属维度所对应的神经元的连接;
76、基于所述每一特征值对应的嵌入特征对断开处理后的模型进行训练。
77、第四方面,提供了一种对象推荐的装置,包括:
78、对象特征获取模块,用于获取各个对象分别对应的对象特征;
79、预测模块,用于基于所述各个对象分别对应的对象特征,并通过训练后的推荐模型,预测各个对象对被推荐对象的感兴趣程度;
80、对象推荐确定模块,用于基于所述各个对象对被推荐对象的感兴趣程度,确定是否为对象推荐所述被推荐对象;
81、其中,所述训练后的推荐模型是通过第三方面或者第三方面任一可能的实现方式所示的基于异常特征处理的模型训练装置所得到的。
82、第五方面,本技术实施例还提供了一种电子设备,该电子设备包括存储器和处理器,存储器中存储有计算机程序,处理器执行该计算机程序以实现第一方面任一可能的实现方式所提供的模型训练的方法。
83、第六方面,本技术实施例还提供了一种电子设备,该电子设备包括存储器和处理器,存储器中存储有计算机程序,处理器执行该计算机程序以实现第二方面任一可能的实现方式所提供的对象推荐的方法。
84、第七方面,本技术实施例还提供了一种计算机可读存储介质,该存储介质中存储有计算机程序,该计算机程序被处理器执行时实现第一方面或者第一方面任一可能的实现方式所提供的模型训练的方法。
85、第八方面,本技术实施例还提供了一种计算机可读存储介质,该存储介质中存储有计算机程序,该计算机程序被处理器执行时实现第一方面或者第二方面任一可能的实现方式所提供的对象推荐的方法。
86、第九方面,本技术实施例还提供了一种计算机程序产品,该计算机程序产品包括计算机程序,该计算机程序被处理器执行时实现第一方面或者第一方面任一可能的实现方式所提供的模型训练的方法。
87、第十方面,本技术实施例还提供了一种计算机程序产品,该计算机程序产品包括计算机程序,该计算机程序被处理器执行时实现第二方面或者第二方面任一可能的实现方式所提供的对象推荐的方法。
88、本技术实施例提供的技术方案带来的有益效果如下:
89、本技术实施例提供了一种模型训练的方法、装置、设备及介质,在本技术实施例中,在获取待训练的推荐模型包含多个训练样本的训练集后,以得到训练集中所包含正样本的第一数量和包含负样本的第二数量,并且训练样本所包含的对象特征中包括至少两个维度的特征值,从而以针对每一维度的每一特征值确定包含该特征值的正样本的第三数量和包含该特征值的负样本的第四数量,能够根据确定出的第三数量和第四数量确定出对应的每一维度的每一特征值在训练集中的异常程度,进而通过将每一训练样本的每一特征值对应的异常程度作为该样本的该特征值不参与模型预测的概率,基于各训练样本以及样本对应的各维度的特征值的异常程度,对待训练的推荐模型进行训练,能够在训练的过程中,减少模型对异常特征值的拟合程度,以增加模型的泛化能力。
90、本技术实施例提供了一种对象推荐的方法、装置、设备及介质,在本技术实施例中,在基于各个对象分别对应的对象特征预测各个对象对被推荐对象的感兴趣程度,以确定是否为对象推荐被推荐对象所依据的推荐模型是通过以下方式训练的:在获取待训练的推荐模型包含多个训练样本的训练集后,以得到训练集中所包含正样本的第一数量和包含负样本的第二数量,并且训练样本所包含的对象特征中包括至少两个维度的特征值,从而以针对每一维度的每一特征值确定包含该特征值的正样本的第三数量和包含该特征值的负样本的第四数量,能够根据确定出的第三数量和第四数量确定出对应的每一维度的每一特征值在训练集中的异常程度,进而通过将每一训练样本的每一特征值对应的异常程度作为该样本的该特征值不参与模型预测的概率,基于各训练样本以及样本对应的各维度的特征值的异常程度,对待训练的推荐模型进行训练,也即通过这种训练方式,能够在训练的过程中,减少模型对异常特征值的拟合程度,以增加模型的泛化能力,进而可以提升推荐模型进行预测的准确度。
- 还没有人留言评论。精彩留言会获得点赞!