一种基于技能发现与分配的多智能体强化学习方法及装置
本发明涉及多智能体强化学习领域,更具体的涉及一种基于技能发现与分配的多智能体强化学习方法及装置。
背景技术:
1、随着机器学习方法在促进智能体行为协作领域的发展,多智能体强化学习(marl,multi-agent reinforcement learning)成为解决协同决策和协同任务的关键技术之一。在多智能体系统中,协同决策和任务分工是复杂的挑战。多智能体强化学习的兴起解决了在实际应用中智能体之间相互作用所带来的复杂性,例如协同控制、资源分配等问题。通过共同学习并优化奖励,多智能体可以实现更高效的协同行为,可以应用于自动驾驶、协作机器人、分布式系统等领域。因此,多智能体强化学习作为强化学习的自然延伸,为解决实际中的协同任务和决策问题提供了强有力的工具。
2、具体而言,在单一智能体强化学习中,每个智能体优化不同的任务奖励,而在协作型多智能体强化学习中,智能体共享一个共同的目标,每个智能体需要学习适当的行为以促进有效的协作和适应性。基于此,为了同时解决多智能体之间互相影响导致训练过程不稳定难以收敛的问题与训练多个智能体网络所需计算开销过大的问题,当前很多方法都使用共享参数的技术。在训练时采用一个神经网络来接收多个智能体的观测信息,所有智能体在全局状态下集中训练,然后在执行时采用不同的值分解方法,每个智能体根据其局部观测分散的执行策略,这种分散执行者之间的参数共享被认为是促进智能体协作并显著提高训练效率的有效技术。然而,参数共享带来的问题是,同一网络虽然能有效促进智能体的协作行为,但很容易导致智能体之间的同质行为的产生,这可能阻碍智能体在需要复杂协调的场景中的适应性。比如,图1所示的在google research football(grf)环境的复杂场景中,两名来自同一团队的玩家在竞争地追逐足球,由于共享参数的问题,导致同一团队的玩家在面对类似的观测时选择相同动作的结果,即多个智能体可能无意中会追求相同的足球。图1所示的这种同一团队的玩家面对类似的观测时选择相同动作的结果妨碍了建立球员和位置球员之间有效角色区分的可能性,从而削弱了合作团队的潜力。
3、在多智能体强化学习中,参数共享在多智能体强化学习的研究中得到了广泛应用,显著提高训练效率并促进了智能体之间协作行为的产生。但是参数共享很容易导致智能体之间的同质行为,这可能阻碍智能体在需要复杂协调的场景中的适应性。
技术实现思路
1、本发明实施例提供一种基于技能发现与分配的多智能体强化学习方法及装置,能够解决现有技术中因参数共享导致智能体之间的行为同质化的问题,增强智能体行为的多样性,从而更好的适应需要复杂协调的任务场景。
2、通过以无监督的方式为多智能体学习有意义且动态的复杂技能,使整个技能库包含多样行为能力,从而让智能体能够根据场景灵活选择。同时在下游多智能体任务中,通过对智能体的动作和状态空间探索,让智能体根据观测选择合适的技能来提高智能体适应复杂场景(如奖励稀疏的环境)的能力,进而促进智能体之间的协作行为以达到最大化团队奖励,为现实场景的智能体协作策略提供支撑。
3、本发明实施例提供一种基于技能发现与分配的多智能体强化学习方法,包括:
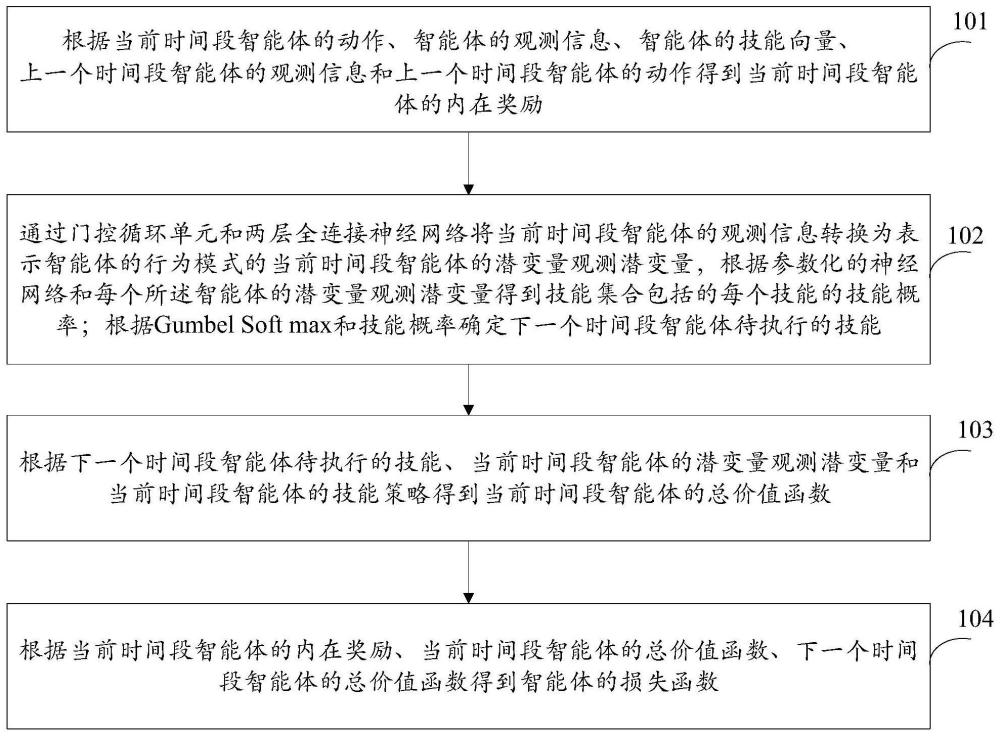
4、根据当前时间段智能体的动作、智能体的观测信息、智能体的技能向量、上一个时间段智能体的观测信息和上一个时间段智能体的动作得到当前时间段智能体的内在奖励;
5、通过门控循环单元和两层全连接神经网络将当前时间段智能体的观测信息转换为表示智能体的行为模式的当前时间段智能体的观测潜变量,根据参数化的神经网络和每个所述智能体的观测潜变量得到技能集合包括的每个技能的技能概率;根据gumbel softmax和技能概率确定下一个时间段智能体待执行的技能;
6、根据下一个时间段智能体待执行的技能、当前时间段智能体的观测潜变量和当前时间段智能体的技能策略得到当前时间段智能体的总价值函数;
7、根据当前时间段智能体的内在奖励、当前时间段智能体的总价值函数、下一个时间段智能体的总价值函数得到智能体的损失函数。
8、优选地,所述得到当前时间段智能体的内在奖励之前,还包括:
9、预设智能体所具有的不同潜在能力的技能,通过one-hot得到每个所述技能对应的编码向量,所述编码向量通过编码网络得到技能向量,根据多个不同的所述技能向量组成技能集合;
10、通过下列公式得到技能向量:
11、zj=fe(ej;θe)
12、通过下列公式对编码网络包括的初始化权重进行更新:
13、
14、其中,ej表示编码向量,θe表示初始化的权重,fe(·;θe)表示编码网络,zi和zj表示任意两个不同的技能向量,表示正则化目标。
15、优选地,所述内在奖励通过下列公式表示:
16、
17、
18、其中,ut表示在时间段t智能体的动作,o表示在时间段t智能体的观测信息,o′表示在时间段t+1,智能体采取动作ut之后智能体的观测信息,φ(o)表示时间段t智能体的观测信息o的表示函数,φ(o′)表示时间段t+1智能体的观测信息o′的表示函数,zj表示时间段t的技能向量,||·||表示欧氏距离,l表示lipschitz常数,x和y表示任意两个状态,φ(x)与φ(y)表示状态空间o中的任意两个状态的表示函数。
19、优选地,通过下列公式确定当前时间段智能体的观测潜变量:
20、
21、通过下列公式表示技能集合包括的每个技能的技能概率:
22、
23、通过下列公式对智能体包括的每个技能的技能概率进行采样:
24、
25、其中,表示经过门控循环单元编码的嵌入,θfcn表示两层全连接网络的参数,表示当前时间段智能体的观测潜变量,θw表示神经网络的参数,表示在给定当前时间段智能体的观测潜变量的条件下,智能体包括的每个技能的技能概率,zsample表示一个采样得到的技能。
26、优选地,所述根据下一个时间段智能体待执行的技能、当前时间段智能体的观测潜变量和当前时间段智能体的技能策略得到当前时间段智能体的总价值函数,包括:
27、根据下一个时间段智能体待执行的技能,当前时间段智能体的观测潜变量和当前时间段智能体的技能策略得到当前时间段智能体的评估价值;
28、当前时间段每个智能体的评估价值通过混合网络得到当前时间段智能体的总价值函数;
29、当前时间段智能体的总价值函数通过下列公式表示:
30、
31、其中,qtotal表示前时间段智能体的总价值函数,mixnet表示混合网络,表示第一个智能体的评估价值,表示第n个智能体的评估价值,θmix表示混合网络的参数。
32、优选地,所述智能体的损失函数通过下列公式表示:
33、
34、其中,表示损失函数,βd表示技能奖励的权重系数,γ表示未来奖励的折扣因子,o表示在时间段t智能体的观测信息,o′表示在时间段t+1,智能体采取动作ut之后智能体的观测信息,z表示当前时间段智能体的技能向量,z′表示下一个时间段智能体的技能向量,表示训练网络上所有智能体的总评估价值,表示目标网络上所有智能体的总评估价值。
35、本发明实施例提供一种基于技能发现与分配的多智能体强化学习装置,包括:
36、技能发现模块,用于根据当前时间段智能体的动作、智能体的观测信息、智能体的技能向量、上一个时间段智能体的观测信息和上一个时间段智能体的动作得到当前时间段智能体的内在奖励;
37、技能分配模块,用于通过门控循环单元和两层全连接神经网络将当前时间段智能体的观测信息转换为表示智能体的行为模式的当前时间段智能体的观测潜变量,根据参数化的神经网络和每个所述智能体的观测潜变量得到技能集合包括的每个技能的技能概率;根据gumbel soft max和技能概率确定下一个时间段智能体待执行的技能;根据下一个时间段智能体待执行的技能、当前时间段智能体的观测潜变量和当前时间段智能体的技能策略得到当前时间段智能体的总价值函数;
38、技能学习模块,用于根据当前时间段智能体的内在奖励、当前时间段智能体的总价值函数、下一个时间段智能体的总价值函数得到智能体的损失函数。
39、优选地,还包括技能编码模块,所述技能编码模块用于:
40、预设智能体所具有的不同潜在能力的技能,通过one-hot得到每个所述技能对应的编码向量,所述编码向量通过编码网络得到技能向量,根据多个不同的所述技能向量组成技能集合;
41、通过下列公式得到技能向量:
42、zj=fe(ej;θe)
43、通过下列公式对编码网络包括的初始化权重进行更新:
44、
45、其中,ej表示编码向量,θe表示初始化的权重,fe(·;θe)表示编码网络,zi和zj表示任意两个不同的技能向量,表示正则化目标。
46、本发明实施例提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行上述任意一项所述的基于技能发现与分配的多智能体强化学习方法。
47、本发明实施例提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述任意一项所述的基于技能发现与分配的多智能体强化学习方法。
48、综上所述,本发明实施例提供一种基于技能发现与分配的多智能体强化学习方法及装置,该方法包括:根据当前时间段智能体的动作、智能体的观测信息、智能体的技能向量、上一个时间段智能体的观测信息和上一个时间段智能体的动作得到当前时间段智能体的内在奖励;通过门控循环单元和两层全连接神经网络将当前时间段智能体的观测信息转换为表示智能体的行为模式的当前时间段智能体的观测潜变量,根据参数化的神经网络和每个所述智能体的观测潜变量得到技能集合包括的每个技能的技能概率;根据gumbelsoft max和技能概率确定下一个时间段智能体待执行的技能;根据下一个时间段智能体待执行的技能、当前时间段智能体的观测潜变量和当前时间段智能体的技能策略得到当前时间段智能体的总价值函数;根据当前时间段智能体的内在奖励、当前时间段智能体的总价值函数、下一个时间段智能体的总价值函数得到智能体的损失函数。该方法通过利普希兹约束技术对观测潜变量进行优化,为了使智能体能够迅速适应不断变化的观测并实时选择适当的技能,根据当前的部分观测潜变量为每个智能体分配合适的技能,提高了多智能体强化学习模型对于智能体行为多样性的学习与协作能力;通过考虑时间段之间智能体观测的相似性来调整技能切换频率,使智能体能够根据其局部观察,动态地为每个智能体分配适当的技能组合,从而能够进行分工协作完成复杂的任务目标;在将技能动态分配给智能体之后,利用通过技能发现获得的技能潜变量来引导每种技能策略的优化过程,可以使智能体学习到多样的、适应各种场景的能力,并进行有效协作达到最大化团队奖励。能够解决现有技术中因参数共享导致智能体之间的行为同质化的问题,增强智能体行为的多样性,从而更好的适应需要复杂协调的任务场景。
- 还没有人留言评论。精彩留言会获得点赞!