一种基于大语言模型生成的正则表达式的文本分类方法与流程
本发明涉及文本分类,具体涉及一种基于大语言模型生成的正则表达式的文本分类方法。
背景技术:
1、随着大数据和机器学习技术的飞速发展,文本分类已经成为自然语言处理领域的重要研究方向,传统的文本分类方法主要依赖于模型的训练和对关键词的提取,这通常需要海量的训练数据来确保分类的准确性,如中国专利公开的一种基于大语言模型的中文超长文本的分类方法(公开号:cn116821348a),该专利技术中以大语言模型为基础,提取关键词,并根据关键词在历史文本归类信息表中的分类信息,判定文本的分类信息,该分类方法不需要对文本进行整体解读,只需对提取的关键词进行分析处理即可,可以极大降低计算机的运算量,从而提升文本分类的速度和效率,但当遇到冷启动问题,即在某一新的领域或特定场景下,没有足够的数据支持模型的训练时,大语言模型提取关键词的效率较低,同时通过提取关键词的方法,容易导致识别到的语义与实际要表达的语义不匹配的情况出现,文本分类的准确度较低。
技术实现思路
1、本发明所要解决的技术问题:现有的文本分类方法数据依赖性强,且通过提取关键词进行分类的方法,准确度较低。
2、为解决上述技术问题,本发明采用如下技术方案:一种基于大语言模型生成的正则表达式的文本分类方法,包括以下步骤:
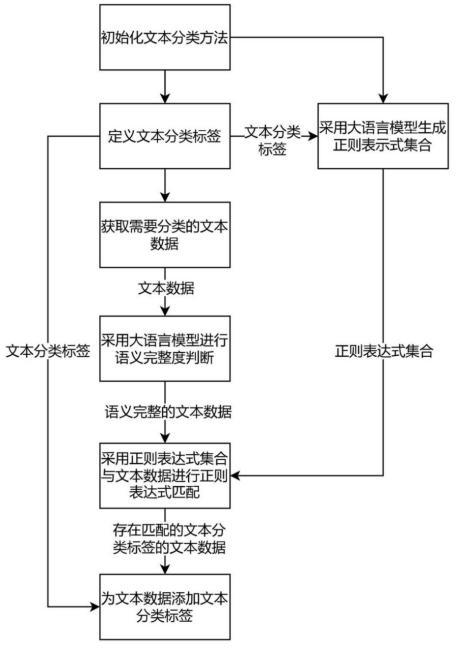
3、s1:初始化文本分类方法,定义文本分类标签,采用大语言模型生成包括若干个文本分类标签各自的正则表达式的正则表达式集合,将经审核通过的正则表达式设置为白正则表达式,然后根据白正则表达式采用大语言模型生成相对应的黑正则表达式;
4、s2:获取需要分类的文本数据;
5、s3:采用大语言模型对文本数据的语义完整度进行判断,将语义不完整的文本数据滤除;
6、s4:根据正则表达式集合中的若干个白正则表达式与文本数据进行匹配,根据正则表达式集合中的若干个黑正则表达式对与文本数据不匹配的文本分类标签进行滤除,然后为该文本数据添加匹配的文本分类标签。
7、本发明工作时,通过大语言模型生成的正则表达式集合,能够快速且准确地完成文本数据的分类,同时根据白正则表达式和黑正则表达式与文本数据进行匹配,可以将错误匹配的文本分类标签滤除,能够进一步提高分类的准确度。
8、作为优选,还包括以下步骤,获取带文本分类标签的标注数据和无文本分类标签的问答数据,每个问答数据均包括问题和答案,通过若干个预设的预处理规则对问答数据进行筛选,滤除与本次文本分类无关的问答数据。
9、本发明工作时,通过将无关的问答数据滤除,能够提高训练的速度,缩短训练周期。
10、作为优选,在所述步骤s1中,采用大语言模型生成包括若干个文本分类标签各自的正则表达式的正则表达式集合时,采用以下步骤:
11、a1:采用预设的句向量推理模型为标注数据生成语义上的向量表示;
12、a2:根据每个标注数据的向量表示召回预设的向量索引库中在语义空间中相匹配的问答数据;
13、a3:将召回的问答数据输入到大语言模型中进行二次分类判断,滤除与相对应的文本分类标签的语义不匹配的问答数据,对与相对应的文本分类标签的语义匹配的问答数据进行标注后设置为标注数据;
14、a4:通过预设的关键词词库对属于同一文本分类标签的标注数据进行分类,采用句法分析工具为标注数据生成句法树,通过每个标注数据的句法树,捕获该标注数据的句法信息和语义信息并与该标注数据一一对应地存储;
15、a5:将属于同一关键词的若干个标注数据,若干个标注数据各自的句法信息,以及预设的正则表达式范式输入给大语言模型,生成若干个正则表达式,并存储至该关键词对应的文本分类标签的正则表达式集合内。
16、本发明工作时,能够充分挖掘大语言模型生成正则表达式的小样本学习能力,基于正则表达式范式可以通过大语言模型快速且高效地生成针对特定文本的正则表达式,从而完成大语言模型的语义理解能力的转化,自由度高,分类准确度高。
17、作为优选,在所述步骤s1中,将经审核通过的正则表达式设置为白正则表达式,然后根据白正则表达式采用大语言模型生成相对应的黑正则表达式时,采用以下步骤:
18、b1:生成的若干个正则表达式经审核通过后设置为白正则表达式,存储至该文本分类标签的正则表达式集合内;
19、b2:采用文本分类标签的白正则表达式与无文本分类标签的问答数据进行正则表达式匹配;
20、b3:将匹配到的问答数据输入到大语言模型中进行二次分类判断,筛选出与相对应的文本分类标签的语义不匹配的问答数据,获取该问答数据的句法信息和预设的正则表达式范式后,输入给大语言模型,生成若干个黑正则表达式,并存储至该文本分类标签的正则表达式集合内。
21、本发明工作时,通过对正则表达式的审核,能够提高白正则表达式的鲁棒性,可以提高分类的准确度,同时通过大语言模型的二次分类判断,然后生成黑正则表达式,可以对错误匹配的文本分类标签进行滤除,进一步提高了文本分类的准确度。
22、作为优选,训练句向量推理模型时,采用以下步骤:
23、c1:将问答数据中具有相同答案或者同类答案的问题设置为正样本,将问答数据中不同答案或者不同类的问题设置为负样本;
24、c2:同一答案对应的若干个问题两两组合成正样本对,通过对比学习的方法采用正样本对和负样本微调基座模型,训练得到句向量推理模型。
25、本发明工作时,通过构造合适的训练集微调训练句向量推理模型,可以提高句向量推理模型与需要分类的文本数据的匹配度,生成语义上的向量表示时更加准确,且具有强烈的区分性,方便区分出正样本和负样本。
26、作为优选,建立向量索引库时,采用以下步骤:
27、d1:采用句向量推理模型为问答数据中的问题生成语义上的向量表示;
28、d2:采用哈希算法分别为每个问答数据中的问题生成对应的标识符;
29、d3:将若干个问题的向量表示与对应的标识符一一对应地存储为向量索引库。
30、本发明工作时,通过建立高效、可快速检索的向量索引库能够提高召回的效率,提高训练效率,能够进一步缩短训练周期。
31、作为优选,建立关键词词库时,采用以下步骤:
32、e1:采用分词工具对标注数据和问答数据进行分词,获取若干个词汇并存储为数据集;
33、e2:采用tf-idf算法对数据集进行分析,对若干个词汇进行赋值;
34、e3:将权重值大于预设的关键词阈值的词汇设置为关键词;
35、e4:采用词嵌入技术对数据集进行训练,获取每个词汇的向量表示;
36、e5:对关键词进行扩充,基于向量表示的相似性,筛选出语义上相匹配的词汇,并存储为关键词词库。
37、本发明工作时,能够实现对训练数据的分词,并提取出关键词,通过建立关键词词库能够为大语言模型生成正则表达式时提供语义线索。
38、作为优选,在所述步骤s2中,获取需要分类的文本数据后,还包括数据预处理的步骤,通过若干个预设的预处理规则对需要分类的文本数据进行筛选,滤除与本次文本分类无关的文本数据。
39、作为优选,在所述步骤s3中,采用大语言模型对文本数据的语义完整度进行判断时,采用以下步骤,将预设的小样本学习语料和思维链提示词输入给大语言模型,大语言模型利用预设的思维链提示词对需要分类的文本数据的语义完整度进行判断。
40、本发明工作时,输入小样本学习语料和思维链提示词给大语言模型,可以充分发挥大语言模型的思维链能力,使得大语言模型能够全面地评估文本数据的语义完整度,准确度较高。
41、作为优选,在所述步骤s4中,根据正则表达式集合中的若干个白正则表达式与文本数据进行匹配,根据正则表达式集合中的若干个黑正则表达式对与文本数据不匹配的文本分类标签进行滤除,然后为该文本数据添加匹配的文本分类标签时,采用以下步骤:
42、f1:遍历所有文本分类标签的白正则表达式与需要分类的文本数据进行匹配,当该文本数据存在相匹配的白正则表达式时转入步骤f2,当该文本数据不存在相匹配的白正则表达式时结束文本分类;
43、f2:遍历所有与该文本数据相匹配的文本分类标签的黑正则表达式,当不存在匹配的黑正则表达式且该文本数据仅与一个文本分类标签的白正则表达式相匹配时,采用该文本分类标签为该文本数据进行标注,当不存在匹配的黑正则表达式且该文本数据与多个文本分类标签的若干个白正则表达式相匹配时,转入步骤f3,当存在匹配的黑正则表达式时转入步骤f4;
44、f3:采用预设的句向量推理模型为该文本数据生成语义上的向量表示,根据该文本数据的向量表示召回在语义空间中相匹配的标注数据,选取若干个带文本分类标签的标注数据,然后获取若干个文本分类标签的众数并将其设置为该文本数据的文本分类标签;
45、f4:将存在匹配的黑正则表达式的文本分类标签滤除后,当存在与多个文本分类标签的若干个白正则表达式相匹配时,转入步骤f3,当仅与一个文本分类标签的白正则表达式相匹配时,采用该文本分类标签为该文本数据进行标注,当不存在相匹配的文本分类标签时结束文本分类。
46、本发明的有益技术效果包括:
47、1、本发明通过大语言模型生成的正则表达式集合,能够快速且准确地完成文本数据的分类,同时根据白正则表达式和黑正则表达式与文本数据进行匹配,可以将错误匹配的文本分类标签滤除,能够进一步提高分类的准确度。
48、2、本发明能够充分挖掘大语言模型生成正则表达式的小样本学习能力,基于正则表达式范式可以通过大语言模型快速且高效地生成针对特定文本的正则表达式,从而完成大语言模型的语义理解能力的转化,自由度高,分类准确度高。
49、3、本发明通过对正则表达式的审核,能够提高白正则表达式的鲁棒性,可以提高分类的准确度,同时通过大语言模型的二次分类判断,然后生成黑正则表达式,可以对错误匹配的文本分类标签进行滤除,进一步提高了文本分类的准确度。
50、4、本发明通过构造合适的训练集微调训练句向量推理模型,可以提高句向量推理模型与需要分类的文本数据的匹配度,生成语义上的向量表示时更加准确,且具有强烈的区分性,方便区分出正样本和负样本。
51、5、本发明采用输入小样本学习语料和思维链提示词给大语言模型,可以充分发挥大语言模型的思维链能力,使得大语言模型能够全面地评估文本数据的语义完整度,准确度较高。
52、本发明的其它特点和优点将会在下面的具体实施方式、附图中详细的揭露。
- 还没有人留言评论。精彩留言会获得点赞!