一种基于联邦集成的分布式网络流量分类方法
本发明涉及网络安全,具体一种基于联邦集成的分布式流量分类方法。
背景技术:
1、随着网络中持续创新的服务和应用的涌现,以及众多各式各样的终端设备不断接入互联网,网络边缘的流量数据正在经历前所未有的爆发式增长。因此,当前面临的一个重要挑战是如何在保持网络流量数据分散的前提下,有效地运用深度学习技术进行网络流量分类任务,同时确保用户的隐私得到充分保护。为了应对上述问题,联邦学习被引入作为一种有效的分布式学习框架,但传统的联邦学习着重于单一架构的设计,其客户端和中央服务器采用单一的模型框架,因此预测能力往往受到所选模型的限制。此外,私有数据的异质性质可能导致部分客户端分类性能下降,进一步影响融合模型的表现。
技术实现思路
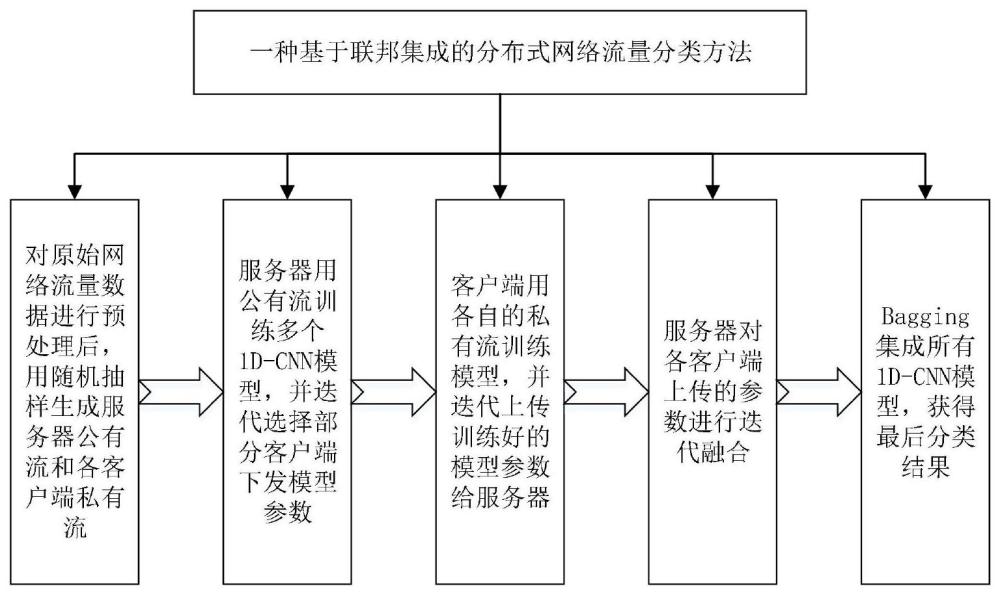
1、针对现有技术的上述不足,本发明的目的在于提供一种分类精度高的基于联邦学习和集成学习的分布式网络流量分类研究方法。首先,对原始网络流量进行必要的预处理步骤。接下来,通过随机抽样的方式生成非独立同分布的服务器公共流量和客户端私人流量。随后,服务器利用公共流量数据来训练多个1d-cnn模型。客户端将接受到的模型进行进一步的训练与更新,并传回优化后的模型参数给服务器。服务器在收集到所有客户端上传的模型参数后,会进行模型参数的融合和整合,以此来更新和优化模型。在模型收敛后,采用bagging集成学习方法,将各个1d-cnn模型的分类结果进行整合,最终得出网络流量的类别判断。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于联邦集成学习的分布式网络流量分类方法,包括步骤:
4、s1:特征映射:获取待转换字符型特征各自种类数n,对每个属性值进行0,1,2,...,n-1的编号映射处理;
5、对映射后的数据集进行空缺值替换,然后根据公式(1)进行z-score标准化处理;
6、
7、其中,n表示映射后的样本数据的维度,x(i)表示特征i所对应的映射后的样本数据,表示特征i所对应映射后的样本数据均值,stdi表示特征i所对应映射后的样本数据标准差,xi为对特征i标准化之后的样本数据。
8、对标准化之后的数据集进行特征选择。为此,我们先对数据集进行初始特征剔除,再从剩余的特征集合中进行进一步的选择。
9、s2:采用随机抽样的方法来模拟服务器与各客户端的网络流量数据异质性,使用随机数控制网络流量数据总量以及各类别的占比,从而使得服务器公有流量数据或各客户端私有数据都是异质的;
10、s3:服务器用公有流量数据训练多个1d-cnn学习模型,并随机选取部分客户端分发已经训练好的模型参数;
11、s4:客户端接收到服务器分发的模型参数后,将其作为本地模型的初始设置,然后使用各自的私有流量数据进行进一步的训练和更新。之后,客户端将训练后的模型参数回传给服务器;
12、s5:服务器将客户端传回的模型参数进行融合,将模型参数更新为融合后的参数;
13、s6:重复s3、s4和s5,直到模型收敛;
14、s7:用bagging集成所有1d-cnn模型,获得最终网络流量分类结果。
15、步骤s3包括:
16、s301:将步骤s2生成的服务器公有流量数据,采用随机抽样方法生成多份样本子集;
17、s302:步骤s301的输出作为s302的输入,为多份样本子集训练多个1d-cnn模型,1d-cnn模型的前两层都是卷积核大小为3*1的一维卷积层;
18、s303:步骤s302的输出作为s303的输入,1d-cnn模型的第三层是卷积核为2*1的最大池化层,第四层线性层;
19、s304:步骤s303的输出作为s304的输入,第五层是dropout层,失活率设为0.4,它随机删除一些神经元,从而降低神经网络的复杂度和参数,能有效避免过拟合;
20、s305:步骤s304的输出作为s305的输入,第六层是softmax层,它将输出整合成数值为0到1之间的6维向量用于分类;
21、s306:服务器端多个1d-cnn模型训练完成后,随机选择部分客户端下发模型参数。
22、步骤s4包括:
23、s401:客户端接收到服务器分发的模型参数后,将其作为本地模型的初始设置,然后使用各自的私有流量数据进行进一步的训练和更新;
24、s402:待客户端的模型收敛后,上传训练好的模型参数给服务器。
25、步骤s5包括:
26、s501:在服务器接收到来自各客户端上传的模型参数后,它会根据每个客户端的损失来分配各模型的权重,其中损失较大的模型将会被赋予较低的权重。接着,服务器会对这些模型参数进行融合;
27、s502:在模型参数融合之后,服务器会利用其自身的公共流量数据,对更新后的1d-cnn模型进行再次训练和优化。
28、步骤s7包括:
29、s701:将网络流量输入训练好的多个1d-cnn模型中进行分类;
30、s702:获取每个1d-cnn模型的损失,根据损失大小确定每个模型的权重,损失大的将被赋予较低的权重;
31、s703:bagging集成所有模型的分类结果,得出最终网络流量类别。
32、本发明一种实施方式的有益效果:
33、对原始数据及进行预处理与特征选择,以便模型能够更好地拟合数据并提高精度;采用随机抽样生成非独立同分布的服务器公有流和客户端私有流,能模拟现实中分散设备中的流量特性;采用bagging方法对多个1d-cnn集成,能综合多个深度学习算法的优势,使得模型之间相互矫正,克服单一模型的局限性,从而提高联邦学习分布式网络流量分类精度,具有很高的实用价值。
技术特征:
1.一种基于联邦集成的分布式网络流量分类研究方法,其特征在于,包括步骤:
2.根据权利要求1所述的基于联邦集成的分布式网络流量分类研究方法,其特征在于,所述数据集为2019年发布的公共数据集ddos2019,我们仅使用udp、syn、ntp、ldap及dns五种攻击流量和良性流量,来构造客户端私有流量及服务器共有流量。
3.根据权利要求1所述的基于联邦集成的分布式网络流量分类研究方法,其特征在于,运用集成学习稳定性的优势,提高联邦学习分类准确率。
4.根据权利要求1-3任意一项所述的基于联邦集成的分布式网络流量分类研究方法,其特征在于,步骤s3包括:
5.根据权利要求1-3任意一项所述的基于联邦集成的分布式网络流量分类研究方法,其特征在于,步骤s4包括:
6.根据权利要求1-3任意一项所述的基于联邦集成的分布式网络流量分类研究方法,其特征在于,步骤s5包括:
7.根据权利要求1-3任意一项所述的基于联邦集成的分布式网络流量分类研究方法,其特征在于,步骤s7包括:
技术总结
本发明公开了一种基于联邦集成学习的分布式流量分类研究方法,该方法借助联邦学习架构解决分布式网络流量分类问题,并考虑用集成学习提高联邦学习分类精度。对原始数据集进行预处理后,用随机抽样生成非独立同分布的服务器端公有流和各客户端私有流,各客户端需要对服务器所有的1D‑CNN模型进行学习更新并上传更新后的模型参数,服务器需要选择客户端下发1D‑CNN模型参数并对客户端上传的参数进行融合更新,最后用Bagging集成所有的1D‑CNN模型获得最终分类结果。该方法用集成学习综合多个学习模型的知识,克服了单一模型学习能力较弱的不足,提高了分布式网络流量分类精度,具有很高的实用价值。
技术研发人员:廖年冬,邓秋霞
受保护的技术使用者:长沙理工大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!