基于气象主导的多因子预测未来臭氧多目标超级集成学习方法
本发明属于机器学习结合臭氧浓度预测和臭氧污染天预报的,涉及一种基于气象主导的多因子预测未来臭氧多目标超级集成学习方法。
背景技术:
1、臭氧(ozone,o3)是对流层大气中的二次污染物,由氮氧化物(nox)和挥发性有机物(vocs)等前体物在大气中发生光化学反应生成,是光化学雾霾的主要组成部分,高浓度臭氧具有强氧化性,臭氧长期暴露会对人体呼吸道和心血管系统造成损伤,增加患病和死亡的风险,还会降低植物的光合作用效率,从而影响植被正常生长,降低农作物产量。
2、本发明的意义在于发展长时间臭氧预测模型,提升臭氧预测预报准确率,为臭氧污染防治提供技术支持。
3、大气中臭氧浓度受前体物排放与气象因素的共同影响,其前体物来源可分为自然源和人为源。在人口集中的城市及周边地区,人为活动排放是臭氧生成的主要贡献之一。另一方面,包括温度、湿度、风速、风向、边界层高度等在内的气象因素也是影响臭氧生成、转化与扩散的重要因素。此外,大尺度的大气环流通过影响臭氧及其前体物的远程输送,以及局部地点前体物本身的光化学反应,对区域臭氧污染水平具有重要影响。在不同的环流形势控制下,污染物的生成、输送、积累特征及其对应的敏感气象因子均不相同。
4、利用臭氧生成机制与规律对臭氧浓度进行准确预测有助于为污染防治提供精确的支持,从而预防或减轻臭氧污染对人类健康和环境的有害影响。传统的预测方法通过建立多元线性回归等模型表征臭氧浓度与相关参数的关系,以预测不同时间段的臭氧浓度,但臭氧浓度与前体物排放和气象因素之间存在复杂的非线性关系,线性模型难以表征其复杂的变化规律。另一种预测方法是以化学传输模型(chemical transport model,ctm)为核心建立的数值模式,利用排放清单与气象场结合模拟污染物的生成、转化和运输过程预测臭氧浓度,但由于污染物高分辨排放清单的编制普遍存在时间滞后性,难以为空气质量数据的实时预测预报提供数据基础。近年来,机器学习方法由于具有被逐渐应用于臭氧预测工作中。如支持向量机(support vector machine,svm),随机森林(random forest,rf)和人工神经网络(artificial neural network,ann)在o3预测中逐渐得到一些应用。它们擅长挖掘臭氧及其影响因素之间的内在关联,以训练模型进行预测,可解决复杂的非线性问题并且计算效率高,具有处理动态、大容量以及复杂数据的能力。因此,机器学习模型相较于时间序列模型和化学传输模型更具灵活性与准确性,符合当下对臭氧浓度快速预测的需求。但是,目前一些机器学习模型构建时采用了存在时间滞后性而无法实时获取的参数,例如文献“mao w,jiao l,wang w.long time series ozone prediction in china:anoveldynamic spatiotemporal deep learning approach[j].building and environment,2022,218:109087.”应用来自于中国多尺度排放清单模型(multi-resolution emissioninventory for china,meic)中提供的氮氧化物、挥发性有机物等数据,在现实应用中无法真正实现对未来臭氧污染水平的预测。此外,不同机器学习算法都存在自身的优势和不足,一些模型受限于参数选择和算法特点,臭氧浓度预测随时长延长存在显著的性能衰减。例如发明专利“202211248805.9[p].2022.12.30”基于深度学习混合模型的大气臭氧预测方法,可有效预测未来3天臭氧浓度,但随着预测时长发展至未来5天,预测结果的误差显著上升,可靠性显著下降。
5、综上,为积极响应省市层面开展未来7-10天空气质量预报,72小时级别预报准确率达到70%以上的迫切需求,有必要发展并集成多种机器学习的方法优势,结合当下可获取的气象及环流等多种臭氧影响因素建立预测数据集,发展可实际应用的未来长时间多预测目标的臭氧水平预测预报模型。深入探究臭氧的浓度及污染水平预测方法,对于大气科学研究和环境监管都具有重要的意义和价值。
技术实现思路
1、本发明提供了一种包含气象参数如温度湿度、环流参数如涡度、臭氧数据、监测站点时空数据等多参数协同的可实际预测未来大气中臭氧浓度、臭氧日最大8小时滑动均值及污染水平的多种机器学习算法集成的超级集成学习方法。该方法的预测数据集选取自开源的实时可获取数据库,以保证本方法可实际应用于现实预测,且应用超级集成学习模型,集成了随机森林、极致梯度提升和类别特征提升3种预测性能优异的机器学习方法的优势。本发明可实际应用于臭氧污染水平多目标预测,输入当下小时的臭氧、土地利用及时空数据和未来5天中预测目标小时的气象、环流参数,得到未来5天内预测小时的臭氧浓度。该方法不仅能够有效预测未来5天内臭氧小时级别浓度,同时也能获得臭氧日最大8小时滑动均值。同时,实现了未来臭氧污染天水平的及时预报预警,并且该预测框架可仅凭借气象数据的可获得性发展未来14天及更长时间臭氧浓度的预测模型,也可以结合k均值方法聚类预测范围,以进一步提升区域臭氧的预测精度。本发明可保证未来长时间预测臭氧水平精度稳定、预测性能好、应用范围广泛。该方法提出的面向未来5天小时分辨的臭氧预测框架有望对臭氧的预测预报提供方法参考,并为生态环境等管理部门政策制定和污染天气应急响应提供数据及技术支持。
2、本发明的技术方案:
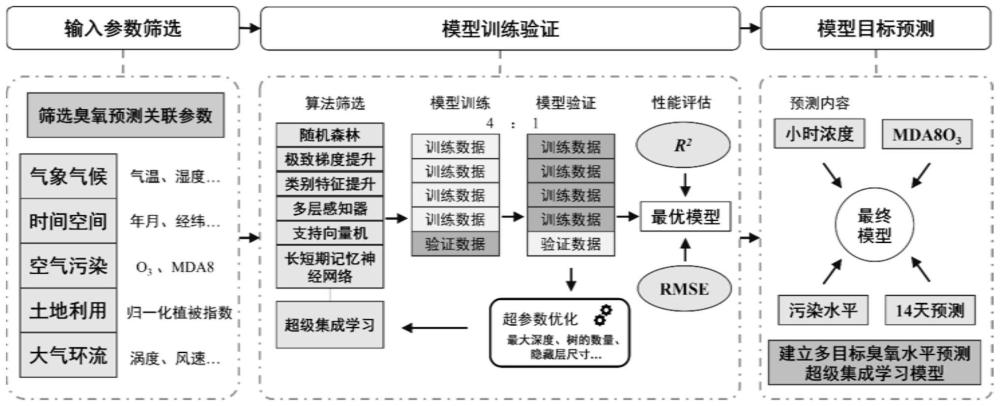
3、基于气象主导的多因子预测未来臭氧多目标超级集成学习方法,包括数据采集、数据处理、模型训练和模型预测四个步骤;
4、(1)数据采集
5、收集包括表达预测变量和预测目标物范围尺度一一对应的数据;首先通过筛选影响臭氧生成、积累、运输以及扩散的关联参数,收集来自中国国家环境监测中心(cnemc,http://www.cnemc.cn)空气质量监管站的实时小时级别o3及日最大8小时滑动均值浓度观测值作为空气污染指标数据,并且收集与站点相匹配的经度、纬度、年、月、日以及小时信息作为时间参数和空间参数输入;气象参数来自于可公开访问的全球化学输运模型数据库geos-cf(https://gmao.gsfc.nasa.gov/),该数据库可提供实时以及未来5天的小时级别分辨的气象数据,包括总云面积分数、地面气压(pa)、10m比湿度(kg/kg)、10m气温(k)、总降水量(kg/m2/s)、基于混合估算的对流层顶压(pa)、体感温度(k)、10m东/北风(m/s)、行星边界层高度(m)、海平面压力(pa)、中间层高度(m)、相对湿度(%)、臭氧柱浓度(kg/m2)。在预测模型中,这些气象参数作为时空变化的预测因子输入训练。本发明也使用了以月份为时间分辨的土地利用参数作为预测模型的二维空间变化的预测因子,即归一化差分植被指数(normalized difference vegetation index,ndvi)。
6、表1.模型输入变量及分类含义信息
7、
8、
9、为训练大气环流对臭氧的贡献并优化模型性能,本发明采用lamb-jenkinson客观环流分型方法,根据相对于目标点的16个差分格点海平面气压计算出6个环流参数。其中海平面气压数据来源与地面气象参数相同,来自于可公开访问的全球化学输运模型数据库geos-cf。环流参数包括经向地转风(meridional geostrophic wind,u)、纬向地转风(latitudinal geostrophic wind,v)、地转风速(geostrophic wind speed,v)、经向涡度(meridional vorticity,ζu)、纬向涡度(latitudinal vorticity,ζv)、涡度(vorticity,ζ)。这些参数首次作为臭氧浓度预测的输入参数加入超级集成学习模型中,可提升本模型预测精度。表1展示了本发明的预测数据集应用的全部预测参数以及数据来源,本发明所选参数皆为实时及未来可获取参数,保证本方法可实际应用于未来臭氧浓度预测中。
10、(2)数据处理是对原始数据集进行数据清洗、归一化以及数据集划分,有利于提高模型精度和训练速度。本方法将来自于geos-cf的网格化参数与来自于中国国家环境监测中心的监测站点数据就近匹配,以监测站点为空间分辨基础预测,并通过删除监测站点存在的缺失值数据作为数据清洗,再将全部数据归一化处理,以获得最终预测数据集用于模型训练。最后,将预测数据集划分为训练集、验证集以及测试集,其中训练集和验证集之比为4:1,通过训练集创建模型以验证集优化模型,最终通过分别进行1-5天臭氧浓度预测建模预测说明模型实际应用效果。
11、(3)本发明应用超级集成学习方法进行模型训练,如图1所示,该方法由基础学习器和元学习器两部分构成,首先通过输入相同的预测数据集对目标时间臭氧浓度进行预测,通过对比预测值与实际值的误差以及臭氧浓度变化趋势的拟合程度,筛选出随机森林、极致梯度提升和类别特征提升这三类性能较优的算法,作为超级集成学习模型的基础学习器。并选择非负最小二乘回归(non-negative least squares,nnls)作为超级集成学习中的元学习器。该超级集成学习方法通过将预测数据集输入至各基础学习器中,加权集成了上述基础学习器的预测结果,并作为元学习器的输入,最终输出即为超级集成学习模型的预测结果。其预测性能可具备不同机器学习算法的优势,获得更好的模型泛化性能及稳定性。该超级集成学习方法还可以通过保留模型间的多样性来减少过度拟合的风险,最终建立针对不同预测区域表现最优的预测臭氧性能的模型。
12、本发明采用决定系数r2和均方根误差(root mean square error,rmse)评价模型预测性能。这两类参数分别代表了模型对实际值的拟合程度,以及预测值和实际值之间的偏差大小。除了以数值形式预测o3浓度外,我们还检验了模型预测o3污染类别的能力。我们根据臭氧浓度aqi值将o3污染分为优(<100μg/m3)、良好(100-160μg/m3)和污染天(>160μg/m3)。分类预测使用相同的预测因子集,预测目标为mda8o3浓度。我们采用正预测值(positive predictive value,ppv),即在预报结果为正(优、良或污染天)后,当天确实达到该特定污染水平的概率,和负预测值(negative predictive value,npv),即在预报结果为负后,当天确实没有达到该特定污染水平的概率,来评价模型预测每天臭氧污染水平的性能。
13、本发明应用超级集成学习模型,输入相同的预测数据集,通过更改预测数据集中的预测目标数据,即臭氧小时浓度和臭氧日最大8小时滑动均值浓度数据,即可实现臭氧浓度多目标预测。从小时级别臭氧浓度预测拓展至预测臭氧日最大8小时滑动均值,并结合上述空气质量指数划分污染天方法,同时预测每日臭氧污染水平。
14、本方法结合k均值方法,将监测站点通过其空间特征,即各监测站点的空间参数包括经度和纬度,将预测目标区域内的站点,聚类划分为不同的子集合,最终分别应用各子集合内的预测数据集训练超级集成学习模型,使得该方法的子集合区域预测相较于整体范围预测可达到更高的精度。由于本方法的输入参数为可预测的未来气象及环流数据主导,并包含实时的臭氧浓度、土地利用以及时空参数。因此,若假定气象数据预测时长满足需要,即可发展可实际应用的14天或更长时间多目标臭氧浓度预测模型。
15、本发明的效果和益处:同现有技术相比,本发明提供了一种由气象数据主导的可实际预测未来大气中多目标臭氧污染水平的超级集成学习方法,具有如下优点:
16、(1)本发明基于超级集成学习模型框架,集成了随机森林、极致梯度提升、类别型特征提升三类优秀基础学习器的预测优势,并选择非负最小二乘回归方法作为元学习器,加权集成基础学习器的优秀预测结果并输出,所得超级集成学习模型通过决定系数r2和均方根误差对比上述三类基础学习器性能普遍较优,如表2以2018至2022年中验证集以及2023年1至10月作为测试集预测环渤海监测站点臭氧小时浓度为例。证明超级集成学习模型预测精度高、泛化性好,易于程序化并推广至不同区域;
17、表2.不同模型预测环渤海臭氧浓度的性能比较
18、
19、
20、(2)本发明建立的预测数据集选取自开源的实时可获取的数据库,以保证可实际应用于现实预测。应用本方法可实现小时时间分辨,未来5天臭氧浓度实时预测,并可依赖气象数据实现未来14天及以上臭氧浓度预测。所得模型方法相较于现有小时级别臭氧浓度预测研究时长最长、拟合优度高,稳健性好,对臭氧污染防治防控,降低健康影响等存在重要意义;
21、(3)对比其他机器学习预测臭氧方法,本发明应用范围广泛。通过相同的预测数据集和超级集成学习模型框架,可同时用于臭氧小时级别浓度、臭氧日最大8小时滑动均值以及臭氧污染水平的多目标预测,其预测精度高、多目标预测性能稳定,可为重污染天应急预报等工作提供数据及技术支持;
22、(4)本发明可以按大气国控站点、城市、以及区域来开展预测,且可以结合k均值方法,将目标所有监测站点通过空间特征聚类划分为不同的区域,根据不同区域内监测站点特征分别预测,提升模型预测精度。
- 还没有人留言评论。精彩留言会获得点赞!