面向多采样率工业过程的数据驱动故障诊断方法及系统
本发明属于工业控制,特别涉及一种面向多采样率工业过程的数据驱动故障诊断方法及系统。
背景技术:
1、实际工业过程数据采集系统往往面临各传感器的数据采样率不一致的问题,导致采集到的过程数据具有显著的不完备与不对称特性,这给数据驱动的故障诊断带来了挑战,详见文献:丛亚,葛志强,宋执环,多采样率主元分析的过程故障检测[j],上海交通大学学报,2015,49(06):762-767。为了实现多采样率数据的实时故障诊断,一些方法将多采样率数据按照其不同时刻上的变量分布划分为不同的子数据集,并分别建立模型。chen等人提出了基于迁移学习的多采样率故障诊断模型,在对各个子数据集分别建立诊断模型后,利用迁移学习方法实现知识共享,详见文献:chen d,yang s,zhou f.transfer learningbased fault diagnosis with missing data due to multi-rate sampling.[j].sensors,2019。feng等人使用k近邻方法计算每个重组数据组的检测阈值,并分别对其进行异常检测,详见文献:feng j,li k.mrs-knn fault detection method for multiratesampling process based variable grouping threshold[j].journal of processcontrol,2020,85:149-158。li等人利用主成分分析和k-近邻法分别对青霉素发酵过程中具有多速率采样特性的异常检测问题进行建模,并将每个模型结合起来计算检测的控制限值,详见文献:li k,feng j.grouping multi-rate sampling fault detection methodfor penicillin fermentation process[j].the canadian journal of chemicalengineering,2020,98(6):1319-1327。
2、虽然这些方法可以解决传统数据驱动的故障诊断方法中模型优化低效与实时性不强等问题,但构建多个模型会使得分配到每个模型的可用训练数据急剧减少,严重影响单个模型的诊断准确率;此外,由于不同数据子集间具有相似性,分别建立模型将其看作是独立的个体往往忽视了这种相似性,降低了整体数据的利用效率。因此,建立单一模型是解决这些问题的理想方法。然而,单一模型的建立面临两个问题,一是如何使用单一模型处理不同变量组成的数据集,二是顺序学习不同数据子集时如何保证模型在训练后不会遗忘前一个数据集上学到的知识,避免灾难性遗忘。
技术实现思路
1、有鉴于此,本发明提出一种面向多采样率工业过程的数据驱动故障诊断方法及系统,其目的是为了解决背景技术中模型训练容易遗忘前面数据集学习到的知识经验,从而导致故障诊断所采用的模型准确低,单一模型无法适应多种工况的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、一方面,一种面向多采样率工业过程的数据驱动故障诊断方法,包括:
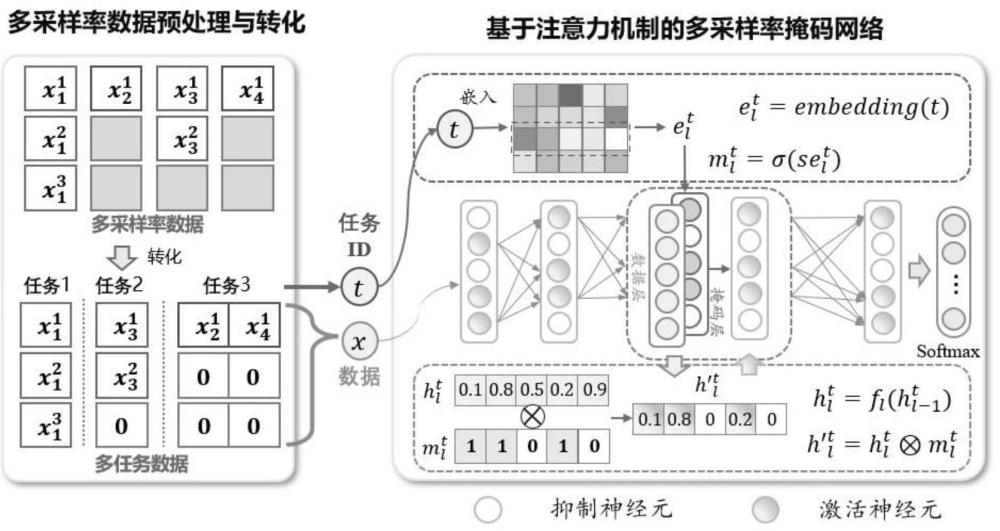
4、首先,对多采样率数据进行数据预处理和划分,使多采样率数据转换为多个子任务数据;
5、将多采样率故障诊断问题转化为多任务故障诊断问题;
6、其次,构造基于注意力机制的多采样率掩码网络故障诊断模型;
7、所述基于注意力机制的多采样率掩码网络故障诊断模型包括依次连接的多采样率掩码网络和softmax分类器;利用离线采集的多个子任务数据,基于注意力机制对多采样率掩码网络依次利用多个子任务数据进行反向传播训练,获得故障诊断模型;
8、利用注意力机制自适应修正反向传播中重要权重的梯度,保留过去任务中学习到的知识,避免发生灾难性遗忘;
9、最后,利用基于注意力机制自适应的多采样率掩码网络故障诊断模型对在线采集的数据进行实时故障诊断。
10、多个子任务数据的学习是顺序进行的,在使用未参与过学习的子任务进行训练时,由于网络参数的更新,容易发生对于已学习子任务的遗忘。通过引入注意力机制与掩码神经网络,可以保持先前学习到的重要参数不变,进而使网络具有对已学任务知识的记忆能力,该网络可以缓解子任务顺序训练过程中面临的灾难性遗忘问题。
11、进一步地,所述对多采样率数据进行数据预处理和划分具体过程如下:
12、首先,需要对每一时刻的n维传感器数据进行标准化;
13、使不同维度的数据都处于同一量纲。
14、其次,根据不同时刻上变量有效维度的组成部分将多采样率数据划分为不同的任务子集;
15、例如某故障诊断任务可以收集得到压力、流量两组数据,其中压力的采样率为1秒/个,流量的采样率为2秒/个,则在第1,3,…,2n-1时刻仅包含“压力”这一个有效维度,而在2,4,…,2n时刻可以采集得到“压力”与“流量”两个有效维度,则根据每一时刻数据包含有效维度的不同,可以把所有数据分为两组,其中第1,3,…,2n-1时刻数据为任务1,第2,4,…,2n时刻数据为任务2。依据数据的有效维度的组成来进行任务/数据的划分,不同的数据维度组成属于不同的任务。
16、有效维度指的是同一时刻采集的传感器数据向量中不为0的维度。
17、进一步地,采取均值-标准差归一化方法,对每一种变量的归一化公式如下:
18、
19、其中x′和x分别表示了标准化前和标准化后的某单一维度的传感器数据,mean和std分别代表x′的均值和标准差。
20、进一步地,多采样率数据掩码网络采用全连接神经网络作为主干网络,且全连接神经网络上的每一层网络隐藏层的输出对应一层线性嵌入层,线性嵌入层的输出与网络隐藏层的输出相乘作为下一层网络的输出,主干网络的最末端设置有sigmoid激活函数。
21、通过掩码激活传播有效信息的神经元,抑制传播无效信息的神经元,驱使神经网络通过嵌入掩码的学习建立不同任务数据与故障标签间的有效映射,这既有利于提升信息的传递效率,同时降低了模型的冗余度。在实际应用中,可以通过改变任务号来获得该任务独有的模型输出,确保在不改变底层网络的情况下,处理多种任务数据并获得相应的故障诊断结果。
22、进一步地,基于注意力机制对多采样率掩码网络进行反向传播训练是指训练任务t+1时,通过最大值函数计算网络累计的掩码利用累积掩码调节训练任务t+1时的模型梯度:
23、
24、
25、其中,被称为累计掩码向量,保留对任务1~t重要的注意力值,elementmax()表示按元素取最大值的算子,分别代表向量的第一个元素,第二个元素,...,第n个元素;;为第l层上第i个神经元与第l-1层上第j个神经元之间的原梯度,为经过注意力机制调整后的梯度,与分别为第l层上第i个神经元与第l-1层上第j个神经元的累计注意力,⊙代表哈德玛积。
26、由于某掩码的某一元素为1意味着第l层对应位置的神经元在任务t中扮演着重要角色,因此,通过按位取最大值来计算在第l层神经元上任务1~t上最大掩码,可以充分衡量对应神经元在任务t的累计重要程度,与现有方法相比,引入掩码机制可以为梯度修正阶段传递信息,确保重要权重不被更新,从而保持先前任务学习到的知识。
27、进一步地,采用带有正比例系数s的sigmoid函数来计算掩码向量;
28、在训练过程中正比例系数的值的设定如下:
29、
30、其中,b代表了当前批次的编号,b=1,2,...,b,b代表了一个迭代内的总批次数;当训练第一个批次的数据时,掩码初始化为1/2,则此时所有单元都是同等活跃的;随着训练的进行,当训练最后一个批次的数据时,s=smax;smax是一个超参数,经过实验获得的最优参数。
31、由于smax是一个远大于1的数,此时原本的sigmoid激活函数就相当于一个阶跃函数,从而实现选择性激活或抑制神经元的作用。
32、第二方面,一种应用上述一种面向多采样率工业过程的数据驱动故障诊断方法的面向多采样率工业过程的数据驱动故障诊断系统,包括:
33、预处理与划分模块,对多采样率数据进行数据预处理和划分,使多采样率数据转换为多个子任务数据;
34、将多采样率故障诊断问题转化为多任务故障诊断问题;
35、模型构建模块,构造基于注意力机制的多采样率掩码网络故障诊断模型;
36、所述基于注意力机制的多采样率掩码网络故障诊断模型包括依次连接的多采样率掩码网络和softmax分类器;利用离线采集的多个子任务数据,基于注意力机制对多采样率掩码网络依次利用多个子任务数据进行反向传播训练,获得故障诊断模型;
37、利用注意力机制自适应修正反向传播中重要权重的梯度,保留过去任务中学习到的知识,避免发生灾难性遗忘;
38、实时诊断模块,利用基于注意力机制自适应的多采样率掩码网络故障诊断模型对在线采集的数据进行实时故障诊断。
39、第三方面,一种电子终端,至少包含:
40、一个或多个处理器;
41、存储了一个或多个计算机程序的存储器;
42、所述处理器调用所述计算机程序以执行:
43、上述一种面向多采样率工业过程的数据驱动故障诊断方法的步骤。
44、第四方面,一种计算机可读存储介质,存储了计算机程序,所述计算机程序被处理器调用以执行:
45、上述一种面向多采样率工业过程的数据驱动故障诊断方法的步骤。
46、有益效果
47、与现有技术相比,本发明具有以下有益效果:
48、本发明技术方案提出的一种面向多采样率工业过程的数据驱动故障诊断方法及系统,创新性的将多采样率数据转化为多任务数据,利用单一模型进行顺序学习。通过梯度注意力机制与掩码网络,缓解了顺序学习中的灾难性遗忘问题,并使网络具有处理维度不一致的多任务数据的能力,提升了有效信息的传递效率。
49、在三相流公开数据集上的实验表明,相较于传统方法,本发明技术方案所提方法取得了1%~10%不等的精度提升,表现出更可靠的故障诊断性能,可进一步推广至其他流程工业具有多采样率数据特性下的故障诊断系统,在未来进行测试与应用。
- 还没有人留言评论。精彩留言会获得点赞!