一种新的用于视觉识别的CNN和Transformer混合神经网络结构方法与系统
本发明涉及计算机视觉神经网络领域,具体为一种新的用于视觉识别的cnn和transformer混合神经网络结构方法与系统。
背景技术:
1、卷积神经网络(cnns)和vision transformers(vits)是计算机视觉中的两个主流框架。cnns凭借其局部依赖特性,可以通过参数少、复杂度低的卷积有效地学习局部判别特征。另外,尽管 vits可以通过自注意力学习全局依赖特征,但由于所有tokens之间的相似性比较,它们带来了很高的计算冗余。因此,cnns的局部性和高效性以及vits的全局性和有效性等互补优势越来越受到人们的关注。
2、卷积和self-attention的结合面临一些挑战,一是多核卷积在多尺度表征学习中表现出了卓越的性能,但很少有研究以类似transformer的方式探索其基于注意力的结构;二是多头自注意力主要关注token之间的相似性比较,而忽略了头部之间的交互。
技术实现思路
1、本发明提供了一种新的用于视觉识别的cnn和transformer混合神经网络结构方法与系统,为实现上述目的,本发明一个或多个实施例提供了如下技术方案:
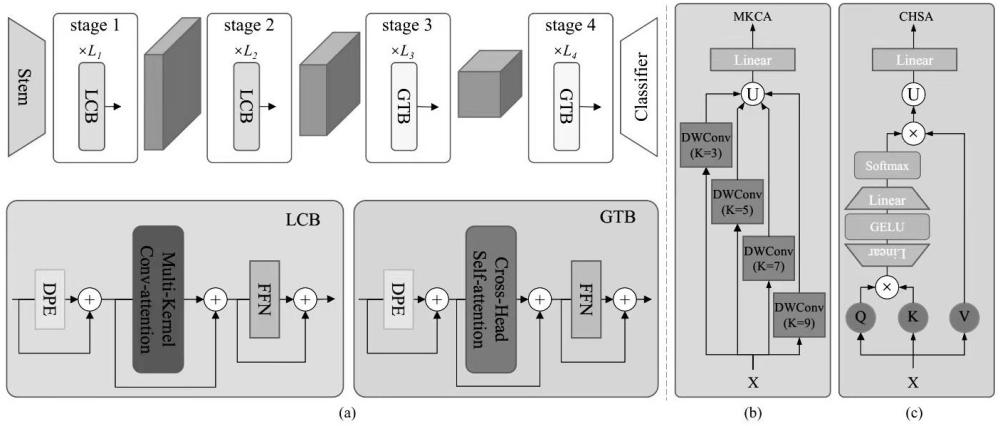
2、第一方面:一种新的用于视觉识别的cnn和transformer混合神经网络结构方法,包括:设计局部卷积块(lcb)和全局transformer块(gtb)作为混合神经网络的两个关键的构建块,实现神经网络提取图像特征时注重局部和全局信息的交互;引入了一种新的多核卷积注意力(mkca)和一种新的跨头自注意力(mhsa),它们与基本的transformer格式统一,分别构成lcb和gtb;在mkca中,我们采用不同核大小的4组卷积来有效地提取局部多尺度特征,这对于高分辨率的浅层特征图来说是资源友好的;在chsa中,我们通过两个线性变换来加强头部之间的注意力交互,从而有效地实现了全局上下文线索的协调注意力空间。第二方面:一个或多个实施例提供了一种新的用于视觉识别的cnn和transformer混合神经网络结构系统,包括:lcb模块:利用提出的transformer格式的多核卷积(mkca)来捕获不同尺度的局部判别特征;gtb模块:利用提出的跨头自注意力机制(mhsa)来学习远程依赖;堆叠多个lcb和gtb网络模块构成神经网络hybridformer,即为一种新的用于视觉识别的cnn和transformer混合神经网络结构方法;神经网络hybridformer遵循了四阶段金字塔结构的典型特征,lcb部署在神经网络浅层,将gtb部署在神经网络深层;对hybridformer进行参数优化,所得到的神经网络模型可用于图像分类、目标检测和语义分割等视觉任务的主干。
3、与现有技术相比,本申请的有益效果是:
4、1. 所提出的神经网络集成了改进的卷积和自注意力的优点,以平衡冗余和依赖性,实现有效和高效的表示学习。我们通过大量的实验来评估本神经网络,证明它在许多视觉任务上达到了最先进的(sota)性能,包括图像分类、目标检测、实例分割和语义分割;
5、2. 本申请构建了利用提出的transformer格式的多核卷积(mkca)来捕获不同尺度的局部判别特征的lcb模块,和利用提出的跨头自注意力机制(mhsa)来学习远程依赖的gtb模块,丰富了注意力神经网络的模块家族。
技术特征:
1.一种新的用于视觉识别的cnn和transformer混合神经网络结构方法与系统,其特征在于,包括:设计局部卷积块(lcb)作为混合神经网络hybridformer的关键构建块之一,实现神经网络提取图像特征时注重局部信息,设计全局transformer块(gtb)作为混合神经网络hybridformer的关键构建块之一,实现神经网络提取图像特征时注重全局信息,lcb采用transformer格式的新型多核卷积注意力(mkca)来捕获局部多尺度特征表,gtb开发了一种新的跨头自注意力(chsa)来学习全局上下文特征表示;堆叠多个lcb和gtb网络模块构成神经网络hybridformer,即为一种新的用于视觉识别的cnn和transformer混合神经网络结构方法。
2.如权利要求书1所述的方法,所述方法还包括:混合神经网络hybridformer可作为网络主干对输入的图像进行图像分类、目标检测、实例分割和语义分割。
3.如权利要求书1所述的方法,设计局部卷积块(lcb)作为混合神经网络hybridformer的关键构建块之一,将lcb部署在高分辨率的浅层,其核心设计是利用transformer格式的多核卷积来捕获不同尺度的局部判别特征;lcb由三个关键模块组成,即动态位置嵌入(dpe)、多核卷积注意力(mkca)和前馈神经网络(ffn);首先采用dpe将位置信息编码到所有token中,这是一种使用零填充深度卷积的可学习位置嵌入方法;然后,我们利用mkca来增强嵌入在每个token中的局部性,通过使用多核组卷积,mkca学习不同的多尺度特征并减少局部冗余;最后,将mkca的输出馈送到ffn层以实现跨通道交互;该ffn与transformer的ffn层相同,由两个线性层组成,中间添加有gelu非线性函数。
4.如权利要求书1所述的方法,全局transformer块(gtb)作为混合神经网络hybridformer的关键构建块之一,实现神经网络提取图像特征时注重全局信息,我们在深层阶段部署gtb以捕获全局特征依赖;设计的关键是利用提出的跨头自注意力机制来学习远程依赖;gtb由三个关键模块组成:动态位置嵌入(dpe),跨头自注意力(chsa)和前馈神经网络(ffn),首先使用dpe将位置信息嵌入到所有token中,这与lcb相同;然后,从全局角度来看,我们通过使用chsa使每个token与所有token交互,并实现头与头之间的注意力交互;最后,chsa的输出仍然被馈送到ffn层。
5.如权利要求书1所述的方法,lcb采用transformer格式的新型多核卷积注意力(mkca)来捕获局部多尺度特征表示, mkca模块用于学习局部表示;为了增强局域性,应用多个核大小来学习不同尺度的丰富语义,同时使用组卷积来减少参数和计算的冗余。
6.如权利要求书1所述的方法,gtb开发了一种新的跨头自注意力(chsa)来学习全局上下文特征表示,在原始mhsa的基础上,跨头自注意力被设计为学习全局依赖;与mhsa相比,chsa强化了头部之间的交互作用,从而协调了它们在所有注意子空间中的注意力。
7.如权利要求书1所述的方法,堆叠多个lcb和gtb网络模块构成神经网络hybridformer,即为一种新的用于视觉识别的cnn和transformer混合神经网络结构方法,hybridformer遵循了四阶段金字塔结构的典型特征;为了获得分层特征图,我们在模型开始时使用4×4非重叠卷积,在各个阶段之间使用下采样层来调整特征图的大小到不同的尺度;lcb部署在前两个阶级,gtb部署在最后两个阶级。
技术总结
卷积神经网络(CNNs)和Vision Transformers(ViTs)是计算机视觉领域两大主流框架。CNNs通过卷积学习局部特征,参数少、复杂度低。ViTs通过自注意机制学习全局依赖,但计算冗余问题显著。头部交互问题鲜有人关注,限制其潜力。为解决问题,提出HybridFormer,包含局部卷积块(LCB)和全局变压器块(GTB)。LCB用多核卷积注意力提取局部多尺度特征,GTB用交叉头自注意学习全局上下文。HybridFormer整合改进卷积和自注意,平衡冗余和依赖,高效表示学习。实验证明HybridFormer在多视觉任务上达最先进水平,包括图像分类、目标检测和语义分割等。
技术研发人员:郭庆北,孙奉昊,李雅其,曾祥飞,段泓冰
受保护的技术使用者:济南大学
技术研发日:
技术公布日:2024/4/7
- 还没有人留言评论。精彩留言会获得点赞!