基于文本生成模型的优化器量化方法、装置以及控制器与流程
本技术涉及人工智能,特别涉及一种基于文本生成模型的优化器量化方法、装置以及控制器。
背景技术:
1、随着人工智能技术的迅速发展,大型深度神经网络模型在聊天机器人、图像生成、视频理解和文本生成等众多领域得到了广泛应用。当前大型深度神经网络模型的应用指数级增长,其中,文本生成模型在对话系统、推荐系统、搜索引擎中都是必不可少的,因此对文本生成模型的显存要求和量化要求也越来越高。当前在训练文本生成模型,通常需要将模型参数、模型梯度、优化器状态都存储在固定数量的可用内存中,状态优化器随着时间的推移维护梯度统计,使用了可以分配给模型参数的内存,占了整体显存的很大一部分,这极大限制了训练的大型深度神经网络模型的最大尺寸。
2、相关技术中,为了缓解文本生成模型训练过程中的显存压力,通过减少或有效分配文本生成模型参数所需的内存来实现更大的模型训练。例如,将模型参数、模型梯度、优化器状态等信息切碎然后分散到不同的显卡上,让每张显卡的显存占用被均摊,使得相同数量的卡可以训练更大的文本生成模型,这种将优化器分布在多个卡的方法虽然有效,但它只能在多张显卡情况下可用,且需要在使用数据并行性的情况下使用,另外优化器分片还可能产生大量通信开销,从而使得训练速度变慢。另外,虽然目前部分量化方法可以减少文本生成模型的内存占用,但是在量化过程中会导致文本生成模型的性能下降,使得文本生成模型的收敛度低从而导致精度降低。
技术实现思路
1、本技术旨在至少解决现有技术中存在的技术问题之一。为此,本技术实施例提供了一种基于文本生成模型的优化器量化方法、装置以及控制器,有利于降低文本生成模型中优化器的显存占用,提高显卡的利用率,从而提高了文本生成模型的性能。
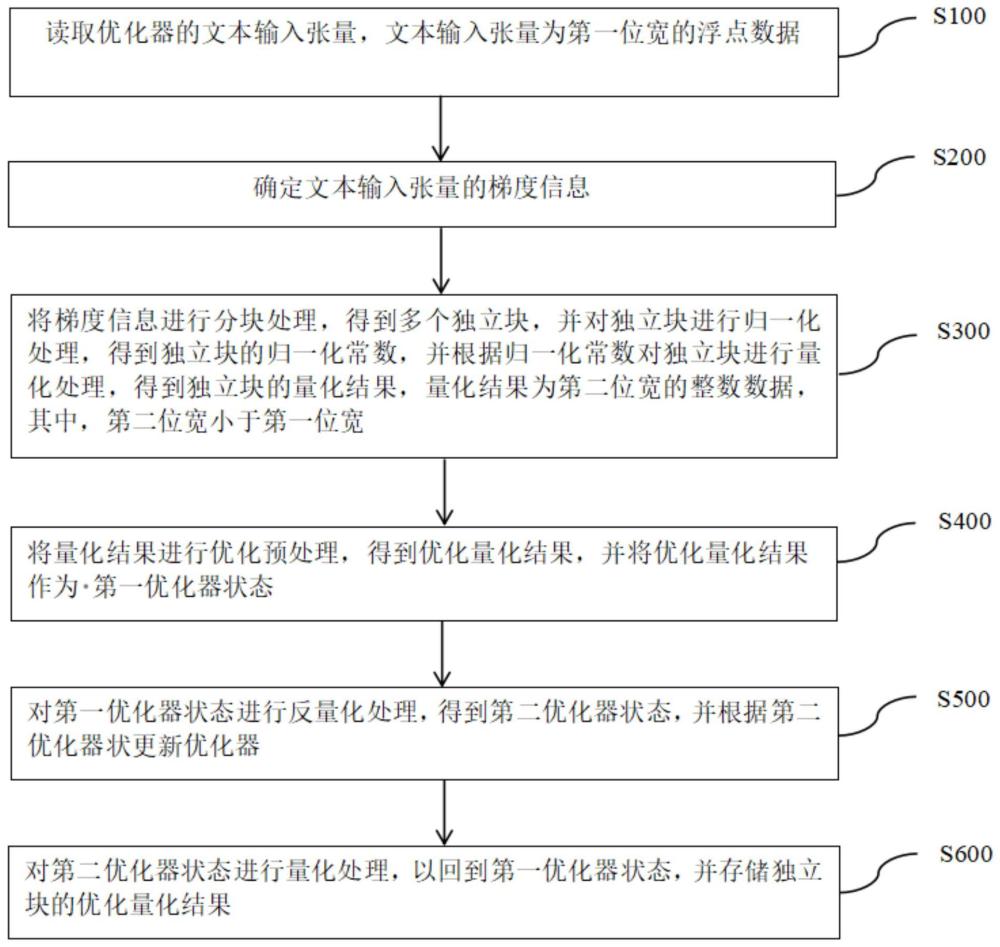
2、第一方面,本技术实施例提供了一种基于文本生成模型的优化器量化方法,包括:
3、读取优化器的文本输入张量,所述文本输入张量为第一位宽的浮点数据;
4、确定所述文本输入张量的梯度信息;
5、对将所述梯度信息进行分块处理,得到多个独立块,并对所述独立块进行归一化处理,得到所述独立块的归一化常数,并根据所述归一化常数对所述独立块进行量化处理,得到所述独立块的量化结果,所述量化结果为第二位宽的整数数据,其中,所述第二位宽小于第一位宽;
6、对所述量化结果进行优化预处理,得到优化量化结果,并将所述优化量化结果作为第一优化器状态;
7、对所述第一优化器状态进行反量化处理,得到第二优化器状态,并根据所述第二优化器状更新所述优化器;
8、对所述第二优化器状态进行量化处理,以回到所述第一优化器状态,并存储所述独立块的优化量化结果。
9、根据本技术的一些实施例,所述第二位宽的整数数据由以下数据结构定义:
10、符号位,为所述数据结构的第一位;
11、指数位,用于由连续为零的位数指示所述整数数据的指数位的大小;
12、指示位,设置为1;
13、线性量化位,用于指示所述整数数据的线性量化值。
14、根据本技术的一些实施例,所述第二位宽的整数数据由以下数据结构定义:
15、分数的固定位,为所述数据结构的第一位;
16、指数位,用于由连续为零的位数指示所述整数数据的指数位的大小;
17、指示位,设置为1;
18、线性量化位,用于指示所述整数数据的线性量化值。
19、根据本技术的一些实施例,所述得到所述独立块的量化结果包括:
20、将所述文本输入张量转换成一维元素序列,并将所述一维元素序列分成预设区间大小的多个独立块;
21、确定所述独立块的归一化常数,并根据所述归一化常数将所述文本输入张量转换为目标量化数据类型的域的范围;
22、确定所述一维元素序列的每个元素在所述目标量化数据类型的域中的对应值;
23、存储与所述对应值所对应的索引;
24、根据所述索引得到所述独立块的量化结果。
25、根据本技术的一些实施例,在所述存储与所述对应值所对应的索引之后,还包括:
26、对所述索引执行反规范化处理;
27、确定所述一维元素序列的最大值;
28、根据经反规范化处理的索引和所述一维元素序列的最大值,通过二分法确定与所述索引对应的量化输出数据;
29、将所述通过二分法确定与所述索引对应的量化输出数据确定为所述独立块的量化结果。
30、根据本技术的一些实施例,将所述文本输入张量输入至嵌入层模块,得到嵌入向量;
31、将所述嵌入向量输入至transformer模型,并执行向前运算,以获得所述优化器的损失函数;
32、将所述损失函数执行反向传播计算,以优化所述损失函数值;
33、确定所述优化器的梯度,并根据所述损失函数和所述梯度得到所述损失函数对于所述文本生成模型的梯度;
34、对所述梯度进行量化处理。
35、根据本技术的一些实施例,在所述将所述文本输入张量输入至所述嵌入层模块之前,还包括:
36、对输入的高度不均匀分布的所述文本输入张量进行归一化处理。
37、第二方面,本技术实施例提供了一种基于文本生成模型的优化器量化装置,包括:
38、读取模块,用于读取优化器的文本输入张量,所述文本输入张量为第一位宽的浮点数据;
39、梯度计算模块,用于确定所述文本输入张量的梯度信息;
40、逐块量化模块,用于对所述梯度信息进行分块处理,得到多个独立块,还用于对所述独立块进行归一化处理,得到所述独立块的归一化常数,并根据所述归一化常数对所述独立块进行量化处理,得到所述独立块的量化结果,所述量化结果为第二位宽的整数数据,其中,所述第二位宽小于第一位宽;
41、动态量化模块,用于对所述量化结果进行优化预处理,得到优化量化结果;
42、嵌入层模块,用于对所述优化量化结果进行预处理,得到第一优化器状态;
43、反量化模块,用于对所述第一优化器状态进行反量化处理,得到第二优化器状态,并将所述第二优化器状更新为所述优化器状态;对所述第二优化器状态进行量化处理,以回到所述第一优化器状态,并存储所述独立块的量化结果。
44、第三方面,本技术实施例提供了一种控制器,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行如上述第一方面的技术方案中所述的基于文本生成模型的优化器量化方法。
45、第三方面,本技术实施例提供了一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行如第一方面的技术方案中所述的基于文本生成模型的优化器量化方法。
46、本技术实施例提供的基于文本生成模型的优化器量化方法、装置以及控制器至少具备如下的优点或有益效果之一:读取优化器的文本输入张量,其中,文本输入张量为第一位宽的浮点数据;然后,计算文本输入张量的梯度信息,并对梯度信息进行分块处理,得到多个独立块;分别对各个独立块进行归一化处理,以求解每个独立块的归一化常数。对梯度信息分块处理成多个独立块,能够单独对每个独立块进行归一化处理,不需要中央处理器核心之间同步求解输入文本的梯度信息,每个独立块都跨中央处理器核心并行处理,提高了量化精度。根据独立块的归一化常数对独立块进行量化处理,得到独立块的量化结果,其中,量化结果为第二位宽的整数数据。由于每个独立块都有对应的归一化常数,使得各个独立块能够独立量化,因此各个独立块之间的异常值之间不会相互影响,独立块能够隔离其他不同独立块的异常值,从而使得量化过程更加精准,另外,通过对独立块的梯度信息进行量化处理还能够使得异常值能够更平均地分布于多个不同独立块,对于非均匀分布具有更小的绝对量化误差和相对量化误差。对独立块的量化结果进行优化预处理,能够避免量化过程中数据表示范围变窄而导致数据溢出问题,提高独立块量化结果的精准性;通过将第一优化器状态反量化为第二优化器状态并执行更新,能够保持使用第二优化器状态的性能水平,然后将第二优化器状态量化回第一优化器状态以进行存储,能够降低文本生成模型中优化器的显存占用,提高显卡的利用率。对寄存器中的各个独立块的梯度信息的量化结果执行第一优化器状态到第二优化器状态的转换,不需要将多个独立块的量化结果慢速复制到显卡内存或额外的临时内存来执行量化和反量化,进一步降低文本生成模型中优化器的显存占用,使得显卡资源利用率更高。另外,在读取优化器的输入张量之后,将输入的高度不均匀分布的文本输入张量进行归一化处理,以支持更积极的量化,避免避免极端的梯度变化,从而提高文本生成模型优化过程中的稳定性。
47、本技术的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本技术而了解。本技术的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!