一种基于人体轨迹预测的AGV防撞预警方法与系统与流程
本发明涉及人工智能,尤其涉及一种基于人体轨迹预测的agv防撞预警方法与系统。
背景技术:
1、在物流仓储环节的降本增效中,仓储agv发挥着至关重要的作用。仓储agv是指应用在仓储环节,可通过接受指令或系统预先设置的程序,自动执行货物转移、搬运等操作的机器装置。仓储agv作为智能仓储与智慧物流的重要组成部分,是商业配送和工业制造行业在解决高度依赖人工、业务高峰期处理货物能力有限等瓶颈问题的突破口。
2、但是大多数仓储中部署的agv主要服务于独立的结构化工作模块,难以满足非结构化的人机交互的场景需求。与agv独立工作的场景不同,人机混合的工作环境对agv的稳定性、安全性提出了更高的要求。现有的agv大多配有避障模块以躲避静态障碍物,但在人机混合的工作场景中,必然存在大量处于运动状态的行人。需要感知模块与规划模块的动态配合,实时更新环境参数,预测人类行为并规避碰撞风险,以实现高可靠的人机混合智能。现有设备难以满足这一要求,亟需一种基于人体轨迹预测的agv防撞预警方法及系统弥补这一缺口。
技术实现思路
1、本发明要克服现有技术的上述缺点,提出一种基于人体轨迹预测的agv防撞预警方法与系统。
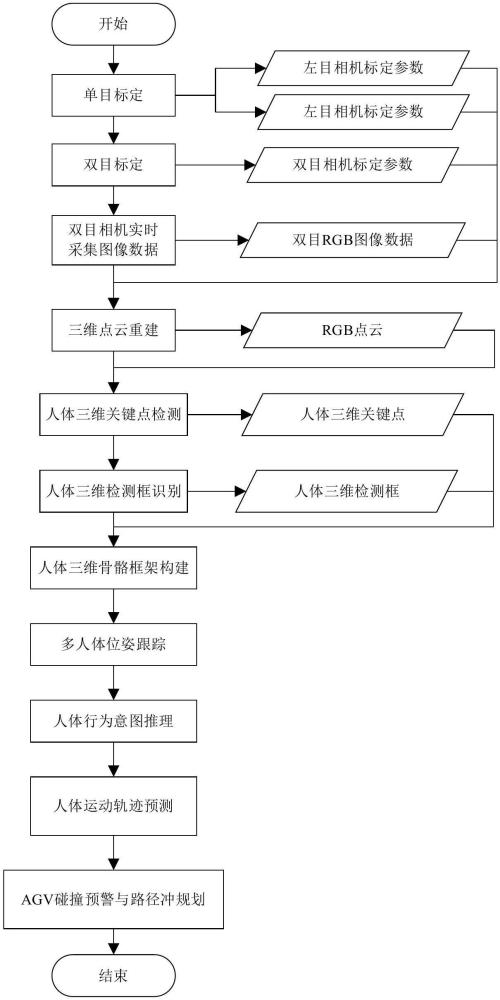
2、本发明的第一个方面涉及一种基于人体轨迹预测的agv防撞预警方法,包括以下步骤:
3、步骤一:对双目相机进行单目标定与双目标定,分别对左目相机、右目相机进行单目标定后,再计算左目相机与右目相机之间的标定参数,利用标定后的双目相机实时采集rgb图像数据;
4、步骤二:基于相机标定参数,利用实时采集到的rgb图像数据做基于双目视觉的三维场景重建,得到agv所处环境的三维点云信息;
5、步骤三:针对agv所处环境的点云信息做人体三维关键点检测,识别并定位出视域范围内所有的人体关键点;
6、步骤四:针对agv所处环境的点云信息做人体三维检测框识别,识别并定位出视域范围内所有的人体检测框;
7、步骤五:基于人体三维关键点检测结果,优化人体三维检测框的识别结果,剔除误识别的人体检测框,同时剔除无法与检测框匹配的关键点,将同一个检测框内的关键点连接成人体三维骨骼框架;
8、步骤六:基于检测框的位置变化规律和人体运动规律,给予检测框标签信息,使得同一个人在不同点云中的检测框具有相同的标签;
9、步骤七:基于人体三维骨骼框架,拆分关键身体部位,分析关健身体部位的运动规律,推理关键身体部位的行为,并推理人体整体的行为意图;
10、步骤八:基于检测框的位置变化规律拟合运动轨迹,并结合人体行为意图的推理结果,预测人体后续的运动轨迹;
11、步骤九:基于预测的人体运动轨迹及人体检测框的几何信息,结合agv自身的后续路径规划,判断是否会有碰撞风险,并给出碰撞预警,若在较短的一段时间内可能出现碰撞风险则改变agv的路径,使agv原地等待或重新规划路线。
12、其中,所述步骤一具体通过以下子步骤实现:
13、(1.1)单目标定左目相机:控制左目相机采集已知尺寸的棋盘格图像,通过角点检测,得到角点在图像坐标系、像素坐标系下的坐标值,已知角点在世界坐标系下的坐标值,可求解得到左目相机的标定参数;
14、(1.2)单目标定右目相机:控制右目相机采集已知尺寸的棋盘格图像,通过角点检测,得到角点在图像坐标系、像素坐标系下的坐标值,已知角点在世界坐标系下的坐标值,可求解得到右目相机的标定参数;
15、(1.3)双目标定左右目相机:控制左目相机与右目相机同时采集已知尺寸的棋盘格图像,通过角点检测,得到同一组角点分别在左目相机像素坐标系下的坐标值与右目相机像素坐标系下的坐标值,已知角点在世界坐标系下的坐标值,可求解得到右目相机相对于左目相机的标定参数;
16、(1.4)双目相机同时采集rgb图像数据:控制左目相机与右目相机同时采集连续的rgb图像数据,同一时刻采集的左目rgb图像与右目rgb图像为一组,采集多组,并记录每组数据的时间戳。
17、其中,所述步骤二具体通过以下子步骤实现:
18、(2.1)左目图像校准:针对某一个时刻采集得到的左目图像数据,根据左目相机的畸变参数对左目图像进行矫正,得到较准后的左目图像;
19、(2.2)右目图像校准:针对同一个时刻采集得到的右目图像数据,根据右目相机的畸变参数对右目图像进行矫正,得到较准后的右目图像;
20、(2.3)双目图像立体校正:将较准后的左目图像与较准后的右目图像投影到同一个虚拟平面中,得到立体校正后的左目图像和立体校正后的右目图像;
21、(2.4)双目立体匹配恢复视差图:将立体校正后的左目图像与立体校正后的右目图像进行逐像素的匹配,得到右目相机图像中的像素点在左目相机像素坐标系下的匹配点,计算右目相机图像中的像素点与匹配点坐标之间的差值,得到视差图;
22、(2.5)深度恢复:基于双目标定得到的基线长度和焦距,利用视差图得到深度图;
23、(2.6)重建三维点云:通过双目相机的内参矩阵和外参矩阵,得到rgb图像像素坐标系下的像素点投影在世界坐标系下的三维坐标值,得到投影的三维坐标,若投影的三维坐标中z方向的值与该像素点在深度图中的深度值不一致,则以深度值为准,得到像素点在世界坐标系下的三维坐标,再结合像素点在rgb图像中的rgb值,得到rgb点云信息。
24、其中,所述步骤三具体通过以下子步骤实现:
25、(3.1)位姿机预测三维关键点的位置和置信度:将rgb点云输入到位姿机中,位姿机读取点云信息并通过三维卷积神经网络将rgb点云转换为热力点云图,热力点云图中的每一个点都包含分类结果和置信度两类预测信息;
26、(3.2)根据置信度筛选关键点:设置置信度阈值,保留置信度超过阈值的关键点,将置信度不超过阈值的关键点放入误检测点集;
27、(3.3)根据空间关系筛选关键点:对于误检测点集内的关键点,若其邻域内的关键点置信度皆超过阈值,则将该点的置信度修改为邻域内关键点置信度的均值,同时保留该关键点,否则删除该关键点。
28、其中,所述步骤四具体通过以下子步骤实现:
29、(4.1)人体检测器预测人体三维检测框的位置和置信度:将rgb点云输入到人体检测器中,人体检测器读取点云信息并利用深度学习网络预测点云中的所有人体三维检测框,每一个人体三维检测框都包含位置和置信度两类预测信息;
30、(4.2)根据置信度筛选检测框:设置置信度阈值,保留置信度超过阈值的检测框,并放入候选检测框集合n,删除置信度不超过阈值的检测框;
31、(4.3)利用非极大值抑制去除重复的检测框:从候选检测框集合n中选择置信度最高的检测框m,并将其放入最终的检测框集合m,遍历候选检测框集合n中剩余的检测框n,计算检测框n与检测框m的重合度,若重合度超过阈值,则从候选检测框集合n中删除检测框n,重复以上步骤多次,直至候选检测框集合n为空。
32、其中,所述步骤五具体通过以下子步骤实现:
33、(5.1)基于人体三维关键点优化人体三维检测框:针对每一个人体三维检测框,判断框内是否有完整的人体三维关键点,若人体三维检测框内不包括完整的人体三维关键点或种类,则删除该检测框;
34、(5.2)基于人体三维检测框优化人体三维关键点:判断关键点是否至少在1个人体三维检测框内,若不在则删除该关键点;
35、(5.3)连接人体骨三维骼框架:针对每一个人体检测框,基于身体各个部分的运动学先验空间关系连接出一组人体三维骨骼框架。
36、进一步,步骤(5.1)所述的人体三维关键点包括:头顶、左眼、右眼、鼻子、左耳、右耳、颈部、左肩、右肩、左手肘、右手肘、左手腕、右手腕、骨盆、左胯、右胯、左膝盖、右膝盖、左脚踝、右脚踝、左脚大拇指、左脚小拇指、右脚大拇指、右脚小拇指。
37、进一步,步骤(5.1)所述的人体关键点的种类设为24类。
38、其中,所述步骤六具体通过以下子步骤实现:
39、(6.1)独立标记单帧三维检测框:当没有历史信息时,针对单帧点云的所有人体三维检测框,给予每一个检测框不同的标签;
40、(6.2)根据历史时序信息预测三维检测框的位置信息:当存在历史信息时,根据具有同样标签的三维检测框的历史位置信息,拟合运动轨迹,预测检测框的位置,得到预估位置信息;
41、(6.3)三维检测框跨帧匹配:当存在历史信息时,针对每一个检测框,将其位置信息与上一步骤得到的预估位置信息匹配,若检测框重合度大于阈值,则视为匹配成功,赋予两个检测框相同的标签信息,否则新增一个标签。
42、进一步,所述步骤七具体通过以下子步骤实现:
43、(7.1)拆分关键身体部位:基于人体三维骨骼框架及人体三维关键点的分类结果,拆分出对人体整体行为意图有影响的关键身体部位,分别连接各部位的三维关键点,计算关键点的最小包络得到关健身体部位的三维检测框;
44、(7.2)分析关键身体部位的运动规律:根据连续输入的序列点云,以关键身体部位三维检测框的几何中心为中点,计算中点的运动轨迹,得到关键身体部位的运动轨迹;
45、(7.3)推理关键身体部位的行为:根据身体关键部位的运动轨迹,结合身体部位的类别信息,对关键身体部位的行为进行判断,输出可能会对人体整体运动轨迹有影响的行为;
46、(7.4)推理人体整体的行为意图:以腿部、足部运动为主,头部、躯干运动为辅,并根据是否出现可能会对人体整体运动轨迹有影响的行为,推理人体整体的行为意图。
47、进一步,步骤(7.1)所述的关键身体部位包括:头部、躯干、左腿、右腿、左脚、右脚。
48、进一步,步骤(7.3)所述的关键身体部位行为包括:头部向左转、头部向右转、躯干向左转、躯干向右转、左脚转向、右脚转向。
49、其中,所述步骤八具体通过以下子步骤实现:
50、(8.1)拟合人体运动轨迹:根据连续输入的序列点云,以人体三维检测框的几何中心为中点,拟合中点的运动轨迹,得到人体历史运动轨迹信息,;
51、(8.2)预测人体运动轨迹:根据计算得到的人体历史运动轨迹信息,结合步骤七中对人体行为意图的推理结果,预测人体后续运动轨迹,得到人体预测轨迹信息。
52、其中,所述步骤九具体通过以下子步骤实现:
53、(9.1)碰撞风险判断及碰撞预警:根据人体预测轨迹信息以及人体三维检测框的几何信息,得到人体后续运动路径的安全范围,判断agv当前路径是否会与安全范围存在重合,若有重合,则判断为可能会出现碰撞风险并给出碰撞风险预警,将重合的区域记为重合点;
54、(9.2)agv路径重规划:若存在碰撞风险,则将重合点标记为不可通行点并重新规划路径,若不存在新的路径或新路径的代价值远高于原地等待的代价值,则选择在重合点前原地等待。
55、本发明的第二个方面涉及一种基于人体轨迹预测的agv防撞预警系统,包括:
56、双目rgb图像数据采集模块:对双目相机进行单目标定与双目标定,并利用标定后的双目相机实时采集rgb图像数据;
57、基于双目视觉的三维场景重建模块:基于双目相机的标定参数,利用实时采集到的rgb图像数据实现三维场景重建,得到agv所处环境的三维点云信息;
58、人体三位关键点检测模块:基于agv所处环境的点云信息做人体三维关键点检测,识别并定位出视域范围内所有的人体关键点;
59、人体三维检测框识别模块:基于agv所处环境的点云信息做人体三维检测框识别,识别并定位出视域范围内所有的人体检测框;
60、人体三维骨骼框架构建模块:利用人体三维关键点检测与人体三维检测框的耦合关系,优化关键点与检测框的识别结果,并将同一个检测框内的关键点连接成人体三维骨骼框架;
61、多人体位姿跟踪模块:基于检测框的位置变化规律和人体运动规律,给予检测框标签信息,使得同一个人在不同点云中的检测框具有相同的标签;
62、人体行为意图推理模块:基于人体三维骨骼框架,拆分关键身体部位,分析关健身体部位的运动规律,并根据关键身体部位的行为推理人体整体的行为意图;
63、人体运动轨迹预测模块:基于人体三维检测框的位置变化规律拟合运动轨迹,并结合人体行为意图的推理结果,预测人体后续的运动轨迹;
64、agv碰撞预警与路径重规划模块:基于预测的人体运动轨迹信息判断是否会有碰撞风险,并给出碰撞预警,使agv原地等待或重新规划路线。
65、本发明的第三方面涉及一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现本发明的基于人体轨迹预测的agv防撞预警方法。
66、本发明的第四个方面涉及一种基于人体轨迹预测的agv防撞预警装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现本发明的一种基于人体轨迹预测的agv防撞预警方法。
67、本发明可同时对出现在视域范围内的多个人体进行行为分析及轨迹预测,生成相应的agv防撞预警信息并根据威胁程度重新规划agv的路径。
68、本发明基于人体姿态关键点跟踪实现多人体轨迹预测,提前给出碰撞预警,并重新规划最优路线,提高调度系统效率。
69、本发明的创新点是:
70、(1)本发明利用感知模块与规划模块的动态配合,可实现对动态障碍物的实时避障;
71、(2)本发明可预测行人运动轨迹,提前给出碰撞预警,为规避碰撞事件提供更长的窗口期;
72、(3)本发明基于碰撞风险提前重新规划路线,避免agv原地等待。
73、本发明的有益效果是:
74、(1)本发明可预测行人运动轨迹,提前给出碰撞预警,有效降低碰撞事件发生的可能性,提高人机交互环境的安全性;
75、(2)本发明基于碰撞风险提前重新规划路线,避免agv原地等待,提高自动化工厂的调度效率。
76、(3)本发明为人机混合的仓储环境提供安全保障,以实现高可靠的人机混合智能。
- 还没有人留言评论。精彩留言会获得点赞!