基于监督学习的神经网络的健康训练数据生成方法及装置与流程
本技术涉及数据处理,尤其涉及一种基于监督学习的神经网络的健康训练数据生成方法及装置。
背景技术:
1、在健身运动健康领域,评估模型的运用已经成为了评估用户健康状况和制定个性化健康计划的重要手段。通过收集和分析用户的生理数据,包括心率、血压、血糖水平、体温等,模型可以全面评估用户的生理状况,进而为其制定出符合个人需求的健康计划。
2、然而,在构建评估模型的过程中,面临着数据私密性的问题。用户对于自身数据的隐私保护意识越来越强,这使得难以获取到足够多且具有代表性的数据来构建高精度的评估模型。此外,由于健身运动健康领域的特殊性,用户的生理数据往往存在着个体差异大、动态变化快等特点,这使得数据收集和分析的难度进一步加大。
技术实现思路
1、本技术针对现有的问题,提出了一种基于监督学习的神经网络的健康训练数据生成方法及装置,具体技术方案如下:
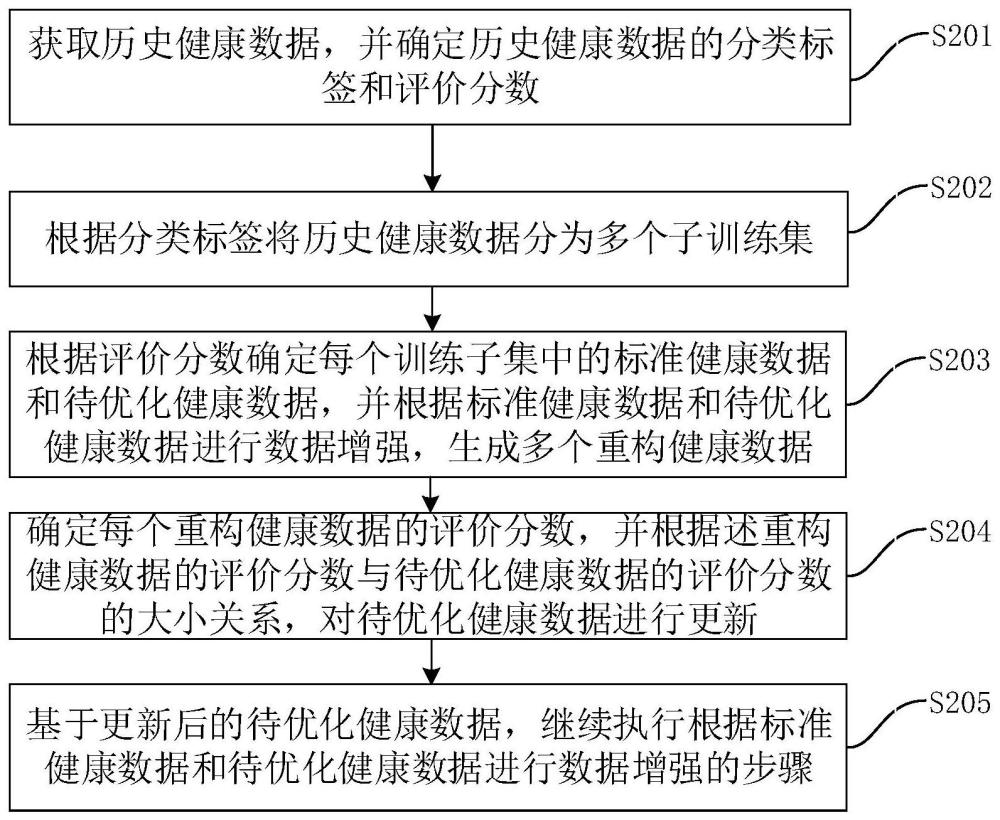
2、在本技术的第一方面,提供一种基于监督学习的神经网络的健康训练数据生成方法,方法包括:
3、获取历史健康数据,并确定历史健康数据的分类标签和评价分数,其中,分类标签用于表征历史健康数据的属性特征,评价分数用于表征历史健康数据的优劣程度;
4、根据分类标签将历史健康数据分为多个子训练集;
5、根据评价分数确定每个训练子集中的标准健康数据和待优化健康数据,并根据标准健康数据和待优化健康数据进行数据增强,生成多个重构健康数据,其中,标准健康数据的评价分数大于待优化健康数据的评价分数;
6、确定每个重构健康数据的评价分数和模版匹配度,并根据重构健康数据的评价分数、模版匹配度以及待优化健康数据的评价分数,对待优化健康数据进行更新;
7、基于更新后的待优化健康数据,继续执行根据标准健康数据和待优化健康数据进行数据增强的步骤。
8、可选地,确定历史健康数据的分类标签和评价分数,包括:
9、将历史健康数据输入第一模型,以获得历史健康数据的分类标签;
10、将历史健康数据输入第二模型,以获得历史健康数据的评价分数,其中,第一模型为分类模型,第二模型为评价模型。
11、可选地,将历史健康数据输入第二模型,以获得历史健康数据的评价分数包括:
12、获取历史健康数据的特征序列以及历史健康数据的评价标准;
13、根据特征序列与评价标准的匹配度,计算历史健康数据的评价分数。
14、可选地,根据标准健康数据和待优化健康数据进行数据增强,生成多个重构健康数据,包括:
15、确定目标重构维度,其中,目标重构维度至少包括:时序维度、数值维度、文本维度以及图像维度中的一种;
16、基于目标重构维度,以标准健康数据为重构目标,对待优化健康数据进行重构,生成多个重构健康数据。
17、可选地,基于目标重构维度,以标准健康数据为重构目标,对待优化健康数据进行重构,生成多个重构健康数据,包括:
18、将标准健康数据映射为第一向量,将待优化健康数据映射为第二向量;
19、基于目标重构维度确定第二向量相当于第一向量的调整位置;
20、基于调整位置的随机变量,生成多个第三向量;
21、基于多个第三向量,生成多个重构健康数据。
22、可选地,方法还包括:
23、在重构健康数据的评价分数大于标准健康数据的评价分数的情况下,将重构健康数据确定为目标健康数据。
24、可选地,在将重构健康数据确定为目标健康数据之后,方法还包括:
25、任意组合每个子训练集的目标健康数据,以获得至少一组用于训练神经网络的健康训练数据。
26、第二方面,本发明实施例提供了一种基于监督学习的神经网络的健康训练数据生成装置,装置包括:
27、获取模块,用于获取历史健康数据,并确定历史健康数据的分类标签和评价分数,其中,分类标签用于表征历史健康数据的属性特征,评价分数用于表征历史健康数据的优劣程度;
28、划分模块,用于根据分类标签将历史健康数据分为多个子训练集;
29、重构模块,用于根据评价分数确定每个训练子集中的标准健康数据和待优化健康数据,并根据标准健康数据和待优化健康数据进行数据增强,生成多个重构健康数据,其中,标准健康数据的评价分数大于待优化健康数据的评价分数;
30、更新模块,用于确定每个重构健康数据的评价分数,并根据重构健康数据的评价分数与待优化健康数据的评价分数的大小关系,对待优化健康数据进行更新;
31、迭代模块,用于基于更新后的待优化健康数据,继续执行根据标准健康数据和待优化健康数据进行数据增强的步骤。
32、可选地,获取模块,包括:
33、第一输入子模块,用于将历史健康数据输入第一模型,以获得历史健康数据的分类标签;
34、第二输入子模块,用于将历史健康数据输入第二模型,以获得历史健康数据的评价分数,其中,第一模型为分类模型,第二模型为评价模型。
35、可选地,第二输入子模块包括:
36、获取单元,用于获取历史健康数据的特征序列以及历史健康数据的评价标准;
37、评价单元,用于根据特征序列与评价标准的匹配度,计算历史健康数据的评价分数。
38、可选地,重构模块,包括:
39、目标维度确定子模块,用于确定目标重构维度,其中,目标重构维度至少包括:时序维度、数值维度、文本维度以及图像维度中的一种;
40、重构子模块,用于基于目标重构维度,以标准健康数据为重构目标,对待优化健康数据进行重构,生成多个重构健康数据。
41、可选地,重构子模块,包括:
42、第一映射单元,用于将标准健康数据映射为第一向量,将待优化健康数据映射为第二向量;
43、第二映射单元,用于基于目标重构维度确定第二向量相当于第一向量的调整位置;
44、生成单元,用于基于调整位置的随机变量,生成多个第三向量;
45、重构单元,用于基于多个第三向量,生成多个重构健康数据。
46、可选地,装置还包括更新模块,用于在重构健康数据的评价分数大于标准健康数据的评价分数的情况下,将重构健康数据确定为目标健康数据。
47、可选地,装置还包括组合模块,用于任意组合每个子训练集的目标健康数据,以获得至少一组用于训练神经网络的健康训练数据。
48、本发明实施例第三方面提出一种电子设备,电子设备包括:
49、至少一个处理器;以及,与至少一个处理器通信连接的存储器;其中,
50、存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够执行本发明实施例第一方面提出方法步骤。
51、本发明实施例第四方面提出一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本发明实施例第一方面提出方法。
52、本技术具有以下有益效果:
53、在本技术的方案中,通过获取历史健康数据并确定分类标签和评价分数,可以对数据进行有效分类和评估。这样可以充分利用有限的历史健康数据,将其转化为具有属性特征和优劣程度的信息,从而更好地理解和利用这些数据。将历史健康数据根据分类标签分为多个子训练集,能够保留不同属性特征的数据样本,并使每个子训练集都具有一定的代表性。这样可以提高数据样本的多样性,使得模型能够学习到更全面和广泛的健康数据特征。根据评价分数确定每个训练子集中的标准健康数据和待优化健康数据,并进行数据增强,生成多个重构健康数据。这样可以通过扩充数据量,增加训练样本的数量,提供更多的数据样本供模型学习和训练,从而提高模型的泛化能力和准确性。通过确定每个重构健康数据的评价分数,并与待优化健康数据的评价分数进行比较,可以进一步优化待优化数据。根据评价分数的大小关系,对待优化健康数据进行更新,使其更接近标准健康数据,从而提高模型的效果和性能。基于更新后的待优化健康数据,继续执行数据增强的步骤,可以生成更多、更具多样性的健康数据样本。这样可以不断优化模型,改进模型的训练效果,并在有限的历史健康数据基础上,获取更多有效数据,提高模型的预测准确性和可靠性。
- 还没有人留言评论。精彩留言会获得点赞!