基于加权组合的电力系统碳排放预测方法及系统与流程
本发明属于电气自动化领域,具体涉及一种基于加权组合的电力系统碳排放预测方法及系统。
背景技术:
1、随着经济技术的发展,人们对于环境问题的关注程度也越来越高;碳排放量的预测,也成为了人们关注的重点。
2、此外,碳排放量的预测,对于电力系统而言,也具有重要的作用。准确的碳排放量预测结果,能够有效帮助电力系统进行更为可靠的运行方案的制定、发电调度计划的制定,以及电力系统未来规划方案的制定。因此,保证电力系统碳排放量预测的准确性,对于电力系统而言,意义重大。
3、但是,目前常用的电力系统碳排放量预测方案,一般都是基于单个模型的预测方案;但是,单模型的预测方案,其并无法适用于各个类型的电力系统;因此,单模型预测方案存在可靠性较差、精确性较差的问题。
技术实现思路
1、本发明的目的之一在于提供一种可靠性高且精确性好的基于加权组合的电力系统碳排放预测方法。
2、本发明的目的之二在于提供一种实现所述基于加权组合的电力系统碳排放预测方法的系统。
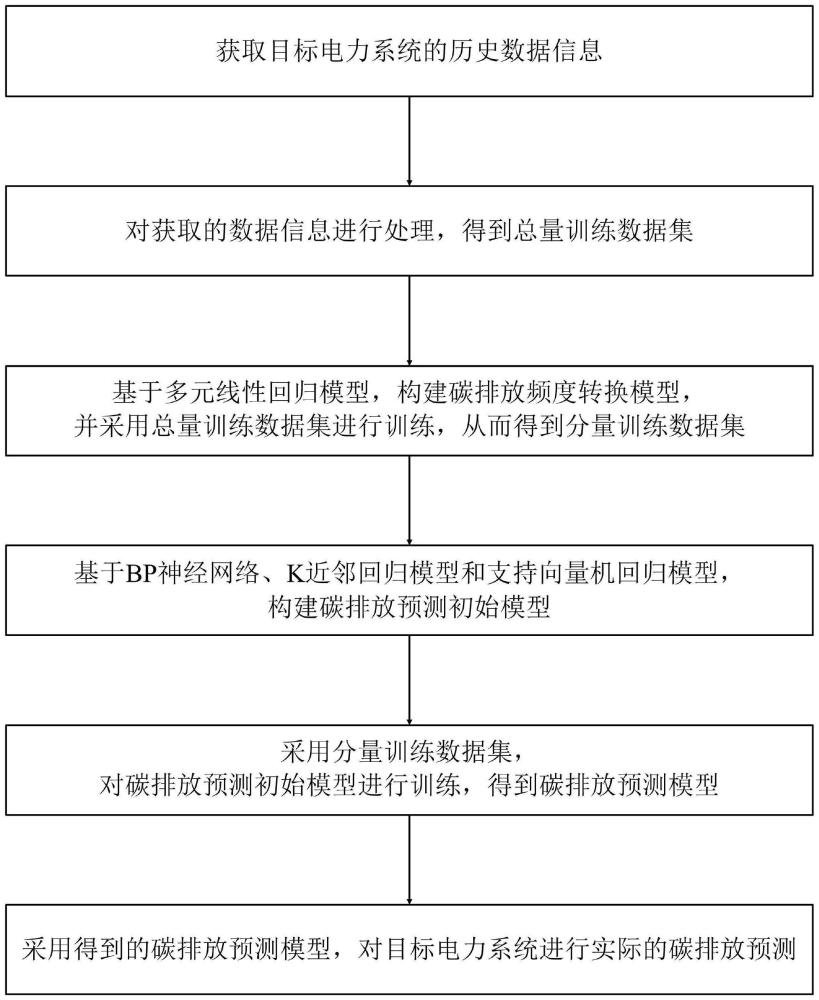
3、本发明提供的这种基于加权组合的电力系统碳排放预测方法,包括如下步骤:
4、s1.获取目标电力系统的历史数据信息;
5、s2.对步骤s1获取的数据信息进行处理,得到总量训练数据集;
6、s3.基于多元线性回归模型,构建碳排放频度转换模型,并采用步骤s2得到的总量训练数据集进行训练,从而得到分量训练数据集;
7、s4.基于bp神经网络、k近邻回归模型和支持向量机回归模型,构建碳排放预测初始模型;
8、s5.采用步骤s3得到的分量训练数据集,对步骤s4构建的碳排放预测初始模型进行训练,得到碳排放预测模型;
9、s6.采用步骤s5得到的碳排放预测模型,对目标电力系统进行实际的碳排放预测。
10、步骤s1所述的获取目标电力系统的历史数据信息,具体包括如下步骤:
11、获取目标电力系统的历史数据信息;所述的历史数据信息包括目标电力系统的月度总用电量、月度火电发电量、月度水电发电量、月度风电发电量、月度光伏发电量、月度生物质发电量和年度碳排放量。
12、步骤s2所述的对步骤s1获取的数据信息进行处理,得到总量训练数据集,具体包括如下步骤:
13、对获取的月度总用电量数据,采用如下算式进行归一化:
14、
15、式中xcons为归一化后的月度总用电量;ccons为归一化前的月度总用电量;min(ccons)为归一化前的月度总用电量的最小值;max(ccons)为归一化前的月度总用电量的最大值;
16、对获取的月度火电发电量数据,采用如下算式进行归一化:
17、
18、式中xther为归一化后的火电发电量;cther为归一化前的火电发电量;min(cther)为归一化前的火电发电量的最小值;max(cther)为归一化前的火电发电量的最大值;
19、对获取的月度水电发电量数据,采用如下算式进行归一化:
20、
21、式中xwater为归一化后的水电发电量;cwater为归一化前的水电发电量;min(cwater)为归一化前的水电发电量的最小值;max(cwater)为归一化前的水电发电量的最大值;
22、对获取的月度风电发电量数据,采用如下算式进行归一化:
23、
24、式中xwind为归一化后的风电发电量;cwind为归一化前的风电发电量;min(cwind)为归一化前的风电发电量的最小值;max(cwind)为归一化前的风电发电量的最大值;
25、对获取的月度光伏发电量数据,采用如下算式进行归一化:
26、
27、式中xpv为归一化后的光伏发电量;cpv为归一化前的光伏发电量;min(cpv)为归一化前的光伏发电量的最小值;max(cpv)为归一化前的光伏发电量的最大值;
28、对获取的月度生物质发电量数据,采用如下算式进行归一化:
29、
30、式中xbiom为归一化后的生物质发电量;cbiom为归一化前的生物质发电量;min(cbiom)为归一化前的生物质发电量的最小值;max(cbiom)为归一化前的生物质发电量的最大值;
31、对获取的年度碳排放量数据,采用如下算式进行归一化:
32、
33、式中为归一化后的年度碳排放量;为归一化前的年度碳排放量;为归一化前的年度碳排放量最小值;为归一化后的年度碳排放量最小值。
34、步骤s3所述的基于多元线性回归模型,构建碳排放频度转换模型,并采用步骤s2得到的总量训练数据集进行训练,从而得到分量训练数据集,具体包括如下步骤:
35、以归一化后的月度总用电量、归一化后的月度火电发电量、归一化后的月度水电发电量、归一化后的月度风电发电量、归一化后的月度光伏发电量和归一化后的月度生物质发电量为自变量,以归一化后的月度碳排放量为因变量,采用如下算式构建多元线性回归模型:
36、
37、式中αcons为用电量参数;αther为火电参数;αwater为水电参数;αwind为风电参数;αpv为光伏参数;αbiom为生物质参数;αconstant为常数参数;为归一化后的月度碳排放量;
38、采用多元线性回归模型计算得到第i个月的归一化后的月度碳排放量i取值为1~12;
39、归一化前的年度碳排放量表示为:
40、
41、式中为第i个月的归一化前的月度碳排放量;
42、采用如下算式作为优化目标:
43、
44、式中为常数项且满足
45、采用步骤s2得到的总量训练数据集,对优化目标进行训练和求解,得到第i个月的归一化前的月度碳排放量从而构建得到分量训练数据集。
46、步骤s4所述的基于bp神经网络、k近邻回归模型和支持向量机回归模型,构建碳排放预测初始模型,具体包括如下步骤:
47、基于蚁群-模拟退火优化bp神经网络预测模型,构建第一预测初始模型;
48、基于k近邻回归模型,构建第二预测初始模型;
49、基于支持向量机回归模型,构建第三预测初始模型;
50、对第一预测初始模型、第二预测初始模型和第三预测初始模型进行加权求和,从而构建碳排放预测初始模型。
51、所述的基于蚁群-模拟退火优化bp神经网络预测模型,构建第一预测初始模型,具体包括如下步骤:
52、初始化网络参数,生成bp神经网络权值初始值和bp神经网络阈值初始值;
53、将bp神经网络的当前权值、阈值输入蚁群算法,并初始化蚁群规模和信息素分布;
54、构造蚂蚁搜索空间,蚂蚁移动并更新信息素浓度,对bp神经网络当前的权值和阈值进行适应度计算,并判断是否满足适应度条件:
55、若满足适应度条件,则确定为蚁群算法优化bp神经网络,计算蚁群的状态转移概率,更新信息素表,并判断是否达到最大迭代次数:若达到最大迭代次数,则蚁群算法结束,获取最优的的bp神经网络权值和阈值;若未达到最大迭代次数,则重新进行蚂蚁移动、更新信息素浓度、计算蚁群的状态转移概率,直至达到最大迭代次数;
56、若不满足适应度条件,则采用模拟退火算法优化bp神经网络,利用网络参数与激活函数,计算输出层输出及能量函数;
57、以能量函数为模拟退火算法优化目标,初始化模拟退火算法的各个参数,扰动产生新的bp神经网络权值和阈值;计算能量函数增量,判断能量函数增量是否小于0:若增量小于0,则对bp神经网络权值和阈值进行更新;若增量大于或等于0,则保持bp神经网络权值和阈值不变;再判断当前温度下是否达到设定的迭代次数:若达到迭代次数,则模拟退火算法结束,输出最优的bp神经网络的权值和阈值;若未达到迭代次数,则采用退温函数进行降温,用新的扰动产生新的bp神经网络的权值和阈值,并再次计算能量函数的增量和判断,直至达到迭代次数;
58、得到bp神经网络的最优的权值和阈值后,结合激励函数,计算输出层的输出为:
59、
60、式中y为输出层节点输出;g()为输出层激励函数;nh为隐含层节点个数;为第j个隐含层节点与输出层节点间最优权值;为第j个隐含层节点的最优阈值;hj为第j个隐含层节点的输出,且f()为隐含层激励函数,nx为输入层节点个数,为第i个输入层节点与第j个隐含层节点间的最优权值,xi为第i个输入层节点的输入;
61、最后,将输出层的输出作为第一预测初始模型的预测输出。
62、所述的基于k近邻回归模型,构建第二预测初始模型,具体包括如下步骤:
63、确定距离度量,以特征空间中两个实例点的距离反映实例点间的相似程度,针对n维向量空间rn,任意两点xi=(xi,1,xi,2,…,xi,n)t和xj=(xj,1,xj,2,…,xj,n)t,计算欧式距离l(xi,xj)为:
64、
65、选定参数k;
66、将输入数据划分为测试集和训练集;计算测试集与训练集数据间的距离并排序,选择距离最近的k个训练样本为
67、以选定的k个点的碳排放量均值为回归预测结果,表示为
68、
69、式中为第ii个测试点的碳排放量预测值;为第ii个点的碳排放量。
70、所述的基于支持向量机回归模型,构建第三预测初始模型,具体包括如下步骤:
71、将数据映射到高维特征空间,并将支持向量机转换为对偶函数,表示为:
72、
73、
74、式中ωsvm为权重值;αpunish为惩罚因子;ntrain为样本数;χi为第一松弛因子;为第二松弛因子;yi为第i个输出样本;gg()为映射函数;xi为第i个输入样本;θsvm为阈值;ξ为不敏感损失函数;
75、对约束条件进行转换,得到:
76、
77、式中f(xtrain)为碳排放量预测值;nsvm为支持向量机个数;βi为第一拉格朗日乘子;为第二拉格朗日乘子;k()为核函数;xtrain为输入样本。
78、所述的对第一预测初始模型、第二预测初始模型和第三预测初始模型进行加权求和,从而构建碳排放预测初始模型,具体包括如下步骤:
79、构建的碳排放预测初始模型表示为:
80、
81、式中为第i个输入数据的碳排放量组合预测值;为第一预测初始模型的预测输出值;为第二预测初始模型的预测输出值;为第三预测初始模型的预测输出值;ωaco-sa-bp为第一预测模型权重值,ωknn为第二预测模型权重值,ωsvm为第三预测模型权重值,且ωaco-sa-bp+ωknn+ωsvm=1,0≤ωaco-sa-bp≤1,0≤ωknn≤1,0≤ωsvm≤1。
82、步骤s5所述的训练,具体包括如下步骤:
83、采用如下算式作为训练的优化目标:
84、
85、式中为第i个输入数据的拟合精度,且
86、本发明还公开了一种实现所述基于加权组合的电力系统碳排放预测方法的系统,包括数据获取模块、数据处理模块、分量处理模块、模型构建模块、模型训练模块和碳排放预测模块;数据获取模块、数据处理模块、分量处理模块、模型构建模块、模型训练模块和碳排放预测模块依次串接;数据获取模块用于获取目标电力系统的历史数据信息,并将数据信息上传数据处理模块;数据处理模块用于根据接收到的数据信息,对获取的数据信息进行处理,得到总量训练数据集,并将数据信息上传分量处理模块;分量处理模块用于根据接收到的数据信息,基于多元线性回归模型,构建碳排放频度转换模型,并采用总量训练数据集进行训练,从而得到分量训练数据集,并将数据信息上传模型构建模块;模型构建模块用于根据接收到的数据信息,基于bp神经网络、k近邻回归模型和支持向量机回归模型,构建碳排放预测初始模型,并将数据信息上传模型训练模块;模型训练模块用于根据接收到的数据信息,采用得到的分量训练数据集,对步骤s4构建的碳排放预测初始模型进行训练,得到碳排放预测模型,并将数据信息上传碳排放预测模块;碳排放预测模块用于根据接收到的数据信息,采用得到的碳排放预测模型,对目标电力系统进行实际的碳排放预测。
87、本发明提供的这种基于加权组合的电力系统碳排放预测方法及系统,通过利用边际成本低、时间颗粒度小的长期电力数据进行转换,而且采用3种预测方法进行综合的碳排放预测,因此本发明不仅实现了对时间颗粒度高的短期碳排放数据进行预测,而且可靠性更高,精确性更好。
- 还没有人留言评论。精彩留言会获得点赞!