基于物联网的电动车还车数据处理方法及系统与流程
本发明涉及车辆运输管理,具体涉及一种基于物联网的电动车还车数据处理方法及系统。
背景技术:
1、电动车分为交流电动车和直流电动车。通常说的电动车是以电池作为能量来源,通过控制器、电机等部件,将电能转化为机械能运动,以控制电流大小改变速度的车辆。随着共享电动车的普及,为了便于工作人员跟踪存在异常状态的电动车,需要保留物联网下各个电动车的异常还车数据。但电动车还车数据的数据量较大,若对全部还车数据进行无损压缩处理,则数据处理设备的存储空间将会不足,也就是电动车还车数据的压缩率较高;若对全部还车数据进行有损压缩处理,则无法保留异常还车数据。因此,现有的电动车还车数据处理方法无法在保证还车数据压缩效果的同时避免异常还车数据的丢失,导致电动车还车数据处理效果较差。
技术实现思路
1、为了解决上述现有的电动车还车数据处理方法无法在保证还车数据压缩效果的同时避免异常还车数据的丢失,导致电动车还车数据处理效果较差的技术问题,本发明的目的在于提供一种基于物联网的电动车还车数据处理方法及系统,所采用的技术方案具体如下:
2、本发明一个实施例提供了一种基于物联网的电动车还车数据处理方法,该方法包括以下步骤:
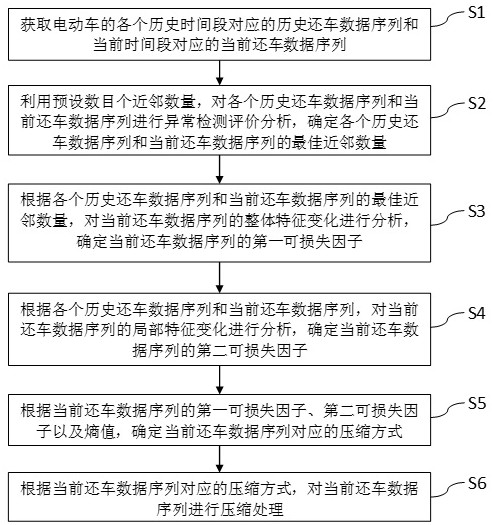
3、获取电动车的各个历史时间段对应的历史还车数据序列和当前时间段对应的当前还车数据序列;
4、利用预设数目个近邻数量,对各个历史还车数据序列和当前还车数据序列进行异常检测评价分析,确定各个历史还车数据序列和当前还车数据序列的最佳近邻数量;
5、根据各个历史还车数据序列和当前还车数据序列的最佳近邻数量,对当前还车数据序列的整体特征变化进行分析,确定当前还车数据序列的第一可损失因子;
6、根据各个历史还车数据序列和当前还车数据序列,对当前还车数据序列的局部特征变化进行分析,确定当前还车数据序列的第二可损失因子;
7、根据当前还车数据序列的第一可损失因子、第二可损失因子以及熵值,确定当前还车数据序列对应的压缩方式;其中,所述压缩方式包括有损压缩和无损压缩;
8、根据当前还车数据序列对应的压缩方式,对当前还车数据序列进行压缩处理。
9、进一步地,所述利用预设数目个近邻数量,对各个历史还车数据序列和当前还车数据序列进行异常检测评价分析,确定各个历史还车数据序列和当前还车数据序列的最佳近邻数量,包括:
10、任选一个还车数据序列为选定还车数据序列,利用预设数目个近邻数量,对选定还车数据序列进行异常检测,确定选定还车数据序列对应的各个近邻数量的密度值和离群点数量;其中,所述还车数据序列为历史还车数据序列或当前还车数据序列;
11、对各个近邻数量按照预设顺序进行排序获得近邻数量序列,在近邻数量序列中任选一个近邻数量为候选近邻数量;将候选近邻数量与其相邻的下一个近邻数量的密度值之间的差值绝对值,确定为候选近邻数量的密度波动指标;
12、根据选定还车数据序列对应的各个近邻数量的密度值、离群点数量以及密度波动指标,确定选定还车数据序列对应的各个近邻数量的评价指标;
13、将最大评价指标对应的近邻数量确定为选定还车数据序列的最佳近邻数量。
14、进一步地,所述根据选定还车数据序列对应的各个近邻数量的密度值、离群点数量以及密度波动指标,确定选定还车数据序列对应的各个近邻数量的评价指标,包括:
15、对于候选近邻数量,确定候选近邻数量的第一评价因子,所述第一评价因子与候选近邻数量的密度值为正相关且与密度波动指标为负相关;确定候选近邻数量的第二评价因子,所述第二评价因子与候选近邻数量的离群点数量呈现反比例关系;将候选近邻数量的第一评价因子和第二评价因子的乘积确定为候选近邻数量的评价指标。
16、进一步地,所述根据各个历史还车数据序列和当前还车数据序列的最佳近邻数量,对当前还车数据序列的整体特征变化进行分析,确定当前还车数据序列的第一可损失因子,包括:
17、根据各个历史还车数据序列的最佳近邻数量,对各个历史还车数据序列进行异常检测,获得各个历史还车数据序列的离群点数量,计算所有历史还车数据序列的离群点数量的平均值;
18、根据各个历史还车数据序列的离群点数量和所有历史还车数据序列的离群点数量的平均值,确定各个历史还车数据序列的标准偏差;
19、将所有历史还车数据序列中标准偏差小于偏差阈值的历史还车数据序列对应的离群点数量,确定为可信任离群点数量;
20、根据当前还车数据序列的最佳近邻数量,获得当前还车数据序列的离群点数量;
21、根据当前还车数据序列的离群点数量和各个可信任离群点数量,确定当前还车数据序列的第一可损失因子。
22、进一步地,所述根据当前还车数据序列的离群点数量和各个可信任离群点数量,确定当前还车数据序列的第一可损失因子,包括:
23、计算所有可信任离群点数量的平均值;将当前还车数据序列的离群点数量与所有可信任离群点数量的平均值之间的差值绝对值,确定为当前还车数据序列的初始第一可损失因子;将反比例归一化处理后的初始第一可损失因子确定为当前还车数据序列的第一可损失因子。
24、进一步地,所述根据各个历史还车数据序列和当前还车数据序列,对当前还车数据序列的局部特征变化进行分析,确定当前还车数据序列的第二可损失因子,包括:
25、对于选定还车数据序列,根据选定还车数据序列中每个时间点的还车数据进行曲线拟合,获得选定还车数据曲线;确定选定还车数据曲线中的突变点,将所述突变点确定为选定还车数据曲线的数据分段点;利用各个数据分段点对选定还车数据序列进行分段处理,获得各个选定数据段;其中,所述选定数据段为历史数据段或当前数据段;
26、根据各个历史数据段和各个当前数据段,确定当前还车数据序列的第二可损失因子。
27、进一步地,所述根据各个历史数据段和各个当前数据段,确定当前还车数据序列的第二可损失因子,包括:
28、计算各个历史数据段和各个当前数据段的标准差;对于任意一个当前数据段,将当前数据段的标准差与所有数据段对应的标准差均值之间的差值绝对值,确定为当前数据段的初始标准差变化量;对所述初始标准差变化量进行归一化处理,将归一化处理后的初始标准差变化量确定为标准差变化量;其中,所述所有数据段包括各个历史数据段和各个当前数据段;
29、统计标准差变化量大于变化量阈值的当前数据段个数;将标准差变化量大于变化量阈值的当前数据段个数与所有当前数据段个数的比值,确定为当前还车数据序列的初始第二可损失因子;将反比例归一化处理后的初始第二可损失因子确定为当前还车数据序列的第二可损失因子。
30、进一步地,所述根据当前还车数据序列的第一可损失因子、第二可损失因子以及熵值,确定当前还车数据序列对应的压缩方式,包括:
31、根据当前还车数据序列的第一可损失因子、第二可损失因子以及熵值,确定当前还车数据序列的可损失率;
32、若当前还车数据序列的可损失率大于可损失率阈值,则判定当前还车数据序列对应的压缩方式为有损压缩,否则,判定当前还车数据序列对应的压缩方式为无损压缩。
33、进一步地,所述根据当前还车数据序列的第一可损失因子、第二可损失因子以及熵值,确定当前还车数据序列的可损失率,包括:
34、计算当前还车数据序列的熵值,将反比例归一化处理后的熵值确定为第三可损失因子;将当前还车数据序列的第一可损失因子、第二可损失因子以及第三可损失因子的乘积,确定为当前还车数据序列的可损失率。
35、本发明的一个实施例还提供了一种基于物联网的电动车还车数据处理系统,包括处理器和存储器,所述处理器用于处理存储在所述存储器中的指令,以实现如所述的一种基于物联网的电动车还车数据处理方法。
36、本发明具有如下有益效果:
37、本发明提供了一种基于物联网的电动车还车数据处理方法及系统,通过车辆运输管理技术,分析当前还车数据序列的可损失率,由可损失率确定当前还车数据序列的压缩方式,选取合适的压缩方式对当前还车数据序列进行处理,其在保证压缩效果的同时确保了异常数据特征的保留,增强了电动车还车数据处理效果,主要应用于还车数据管理领域。相比仅获取一个历史还车数据序列,获取电动车的多个历史还车数据序列,有助于提高后续在进行数据计算时的准确性;确定每个还车数据序列的最佳近邻数量,是为了减小或消除因为异常检测算法本身可变值选取不当造成的误差,其能够尽量准确地过滤噪声点和正常点,同时也是为了便于后续进行离群点数量变化的整体分析;基于最佳近邻数量确定的第一可损失因子的精确度较高,第一可损失因子可以被用于表征还车数据序列的整体数据特征的异常程度,对当前还车数据序列的局部特征变化进行分析,可以确定当前还车数据序列的第二可损失因子,第二可损失因子可以被用于表征还车数据序列的局部数据特征的异常程度;从三个角度确定的可损失率的参考价值更高,有助于为当前还车数据序列选择合适的压缩方式,避免出现异常特征还车数据的丢失或压缩率过高的情况,使得压缩后的结果能够有效地保留数据特征,方便电动车还车数据的进一步分析。
- 还没有人留言评论。精彩留言会获得点赞!