一种基于多维特征的中文观点对象抽取方法及系统与流程
本发明涉及观点对象抽取,具体而言,涉及一种基于多维特征的中文观点对象抽取方法及系统。
背景技术:
1、观点对象抽取(opinion target extraction,ote)作为细粒度观点信息的基础任务,也是观点挖掘的关键子任务,旨在抽取出观点句子中的评价对象。目前开展ote的研究方法可以分为传统机器学习方法和神经网络方法两大类。其中,传统机器学习方法又可以分为三类:监督学习、非监督学习和半监督学习。然而,对人工标注标签、预训练规则、字典、种子词和先验领域知识的强依赖,使得传统机器学习方法的进一步推广和应用受限。近年来,随着神经网络的蓬勃发展,其在ote领域也取得了不俗的表现。在中文ote领域,也有不少代表性工作。特别是随着词嵌入技术的发展,该领域的模型性能得到新的推进。
2、尽管网络结构是抽取模型框架的关键,但是,嵌入层特征表示可以将高维稀疏数据转变为低维稠密连续向量,并抓取序列的高层次语义特征。因此,以高质量的嵌入层特征表示作为基础的网络框架更能捕获输入序列中的有用信息,从而解码出更优质的输出序列。已有研究表明,嵌入层特征表示的质量在后续网络框架解码有用信息的时候,起着至关重要的作用。特别是在中文语境中,句法、句式和语义关系相比于英文而言都更复杂多变,需要更多的上下文语义及句法分析,且嵌入层特征表示应该从汉字字符级别,词级别等多个维度来表达。然而,现有大多数中文ote工作更关注于模型的网络结构改造,对实现网络框架性能的基础,即嵌入层特征表示的关注不够充分,且嵌入层的特征表示常停留在词级别,忽视了中文中包含重要信息的汉字字符级表示,这有可能是造成目前中文ote准确率不够令人满意的原因之一。
技术实现思路
1、本发明旨在提供一种基于多维特征的中文观点对象抽取方法及系统,以解决上述存在的问题。
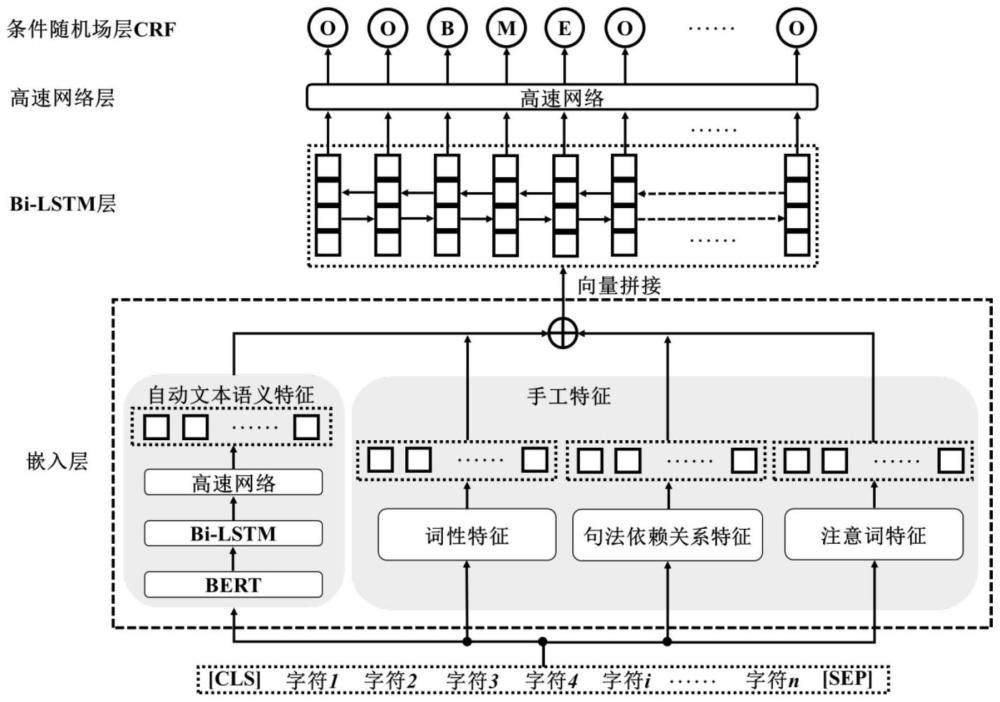
2、本发明提供的一种基于多维特征的中文观点对象抽取方法,包括如下步骤:
3、步骤s1:在自动化特征方面,输入序列依次通过bert层、第一bi-lstm层和第一高速网络层获取自动文本语义特征;
4、步骤s2:在手工特征方面,针对输入序列提取词性特征、句法依存关系特征和注意词特征;
5、步骤s3:将自动文本语义特征、词性特征、句法依存关系特征和注意词特征进行向量拼接,得到拼接向量;
6、步骤s4:拼接向量依次输入第二bi-lstm层和第二高速网络层,最后应用一个条件随机场层crf来学习标签的顺序和相互依赖关系,并以此作为最终输出。
7、进一步的,步骤s1中,输入序列经过bert层的处理包括:
8、首先,在输入序列的开始和结尾分别加上字符[cls]和[sep];
9、接着,所述输入序列所有的汉字字符通过bert层内部的一个字符嵌入层,使得将每个汉字字符转变为一个向量表示;
10、然后,bert层将这个字符嵌入与分段嵌入以及位置嵌入信息进行求和,并将求和后的向量表示输入到一个多层transformer后输出语义向量序列;
11、其中,在进行bert层的处理时,需要将bert层的参数冻结。
12、进一步的,步骤s1中,第一bi-lstm层的处理包括:
13、bert层输出的语义向量序列通过第一bi-lstm层,以学习句子的上下文特征和观点对象位置信息;在这个过程中,第一bi-lstm层根据反馈的损失来削弱非重点字符的权重,并增强有可能是观点对象字符的权重。
14、进一步的,步骤s2中,提取词性特征包括:
15、使用词性标注工具获得输入序列的词性标注;
16、采用字符表示一个词的开始、中间和结束位置信息;
17、将位置信息与词性标注相结合,再赋予每个输入序列的汉字字符,以获得输入序列基于汉字字符级词性特征。
18、进一步的,步骤s2中,提取句法依存关系特征包括:
19、使用依存关系提取工具获得输入序列的依存关系;
20、采用字符表示一个词的开始、中间和结束位置信息;
21、将位置信息与依存关系相结合,获得基于汉字字符级句法依存关系特征;其中,通过依存索引标注将具有依存关系的词对主导词的位置信息赋予依存词。
22、进一步的,步骤s2中,提取注意词特征包括:
23、构建一个包含过渡意味和对比意味倾向词的注意词词库;
24、从输入序列中筛选出来作为候选观点对象;
25、创建一个基于字符的滑动窗口,基于注意词词库,在候选观点对象上下文的窗口范围内搜寻是否存在注意词,从而获得注意词编码,即注意特征。
26、进一步的,步骤s4中,第二bi-lstm层的处理包括:
27、拼接向量输入第二bi-lstm层;
28、第二bi-lstm层分别通过前向lstm和后向lstm,从输入的拼接向量中获得下文和上文的文本信息和观点对象位置信息,并将这些文本信息和观点对象位置信息存储在隐藏状态中;
29、对应前向lstm和后向lstm,所述隐藏状态包括前向隐藏状态和后向隐藏状态,将前向隐藏状态和后向隐藏状态拼接起来;
30、第二bi-lstm层输出的隐藏状态与一个映射到k维的线性层相连接,其中,k是定义的标签集中的类型数量;再通过softmax函数来计算每一个标签类型的得分,随后再连接第二高速网络层;由此,第二高速网络层的输出为输入序列中每一个汉字字符属于标签集中各个类型标签的得分。。
31、进一步的,步骤s4中,条件随机场层crf的处理包括:
32、设x={x1,x2,…,xn}是输入序列x={x1,x2,…,xn}中各个汉字字符所对应的向量序列;y={y1,y2,…,yn}是输出标签序列y={y1,y2,…,yn}对应的向量序列;由第二bi-lstm层、第二高速网络层和条件随机场层crf输出的标签序列的概率公式为:
33、
34、
35、接着,结合最大似然估计和梯度下降算法,寻求全局最优的标签序列,有:
36、
37、其中,y是真实标签向量表示,y′是预测标签向量表示,yx是输入句子x的所有输出标签向量表示;s(x,y)是根据输入句子x得到的输出标签类型y的得分;t是转换特征函数,表征的是从标签类型yi-1到yi的转换概率;e是状态特征函数,表征的是输入xi对应输出标签yi的概率。
38、本发明还提供一种基于多维特征的中文观点对象抽取系统,包括:
39、自动化特征提取模块,用于将输入序列依次通过bert层、第一bi-lstm层和第一高速网络层获取自动文本语义特征;
40、手工特征提取模块,用于针对输入序列提取词性特征、句法依存关系特征和注意词特征;
41、向量拼接模块,用于将自动文本语义特征、词性特征、句法依存关系特征和注意词特征进行向量拼接,得到拼接向量;
42、标签输出模块,用于将拼接向量依次输入第二bi-lstm层和第二高速网络层,最后应用一个条件随机场层crf来学习标签的顺序和相互依赖关系,并以此作为最终输出。
43、综上所述,由于采用了上述技术方案,本发明能够提高中文ote准确率。其中:
44、(1)本发明构建了一个汉字字符级多维特征表示,将自动文本语义特征与手工特征融合,从而从不同维度充分表达输入序列的词法、句法和语义特征。
45、(2)本发明构建了一个注意词词库及注意词特征,使得模型在捕获词法和句法特征的同时,在面对转折句和比较句这类复杂句式时,具备类似于人类关注关键词的能力。
46、(3)本发明将特征表示赋予每个汉字字符,使得每个汉字字符根据其所属的词获得一个边界,使得不相关的汉字字符互不干扰。
- 还没有人留言评论。精彩留言会获得点赞!