一种基于大语言模型的文本数据清洗系统的制作方法
本发明涉及基于大语言模型的数据清洗系统领域,尤其涉及一种基于大语言模型的文本数据清洗系统。
背景技术:
1、文本数据清洗是一项重要的任务,特别是在信息从互联网等多个来源获取时。以下是一些现有的文本数据清洗技术和方法的概述:(1)拼写检查和纠正:拼写错误是文本数据中常见的问题。现有的拼写检查工具如hunspell和自然语言处理库(例如nltk和spacy)可以用来自动检测和纠正拼写错误。(2)语法和语言结构修复:一些工具可以检测和修复语法错误,包括不正确的标点符号使用、语法结构不当等。例如,语法检查器可以识别并修复句子的语法问题。(3)停用词和无效字符的移除:文本中包含大量的停用词(如“的”、“是”等)以及无效字符(如html标签),这些可以通过现有的自然语言处理库来移除。(4)文本规范化:文本数据可能包含各种格式和编码,如日期、时间、货币等。现有技术可以将这些格式标准化为一致的形式。(5)敏感信息检测:一些系统使用关键词匹配、机器学习模型或正则表达式来检测敏感信息,如个人身份信息、银行账号等,并进行相应处理以保护隐私。(6)垃圾信息过滤:垃圾信息(如垃圾邮件、广告和垃圾链接)的检测和过滤也是现有技术的一部分。这通常包括黑名单、白名单和机器学习模型的使用。(7)重复和冗余数据的识别:文本数据中可能存在重复的段落、句子或短语。现有技术可以帮助检测和去除这些冗余数据,以减小数据集的大小。
2、传统的文本数据清洗方法通常需要用户手动编写规则或提供词典来执行拼写检查、停用词移除等任务,这降低了自动化程度,增加了用户的工作量。传统的文本数据清洗方法拼写检查和语法纠正工具有时会产生误报或漏报,因此需要人工检查和干预,尤其是在处理特定行业或领域的文本时。一些现有系统难以满足特定行业或用户的个性化需求,因为现有系统的清洗规则通常是通用的,难以根据不同的领域特定的上下文进行调整。在处理大规模文本数据时,一些传统方法可能不够高效,导致处理时间较长,这不适用于需要实时或快速处理的应用场景。构建和维护复杂的规则和模型需要大量的工程资源和时间,尤其是在不断变化的数据和语言环境下。一些方法在处理多语言文本时表现不佳,因为它们的规则和模型通常是针对特定语言设计的。传统方法可能无法有效处理新兴的词汇、俚语或变体,因为它们通常基于先前的语言数据,某些现有系统可能不容易水平扩展,以适应不断增长的数据量和用户需求。
技术实现思路
1、有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是如何提供一种基于大语言模型的文本数据清洗系统,可以实现自动化的文本数据清洗和个性化和定制化清洗,同时可以实现高效处理大规模数据、可以多语言支持、具有可扩展性等。
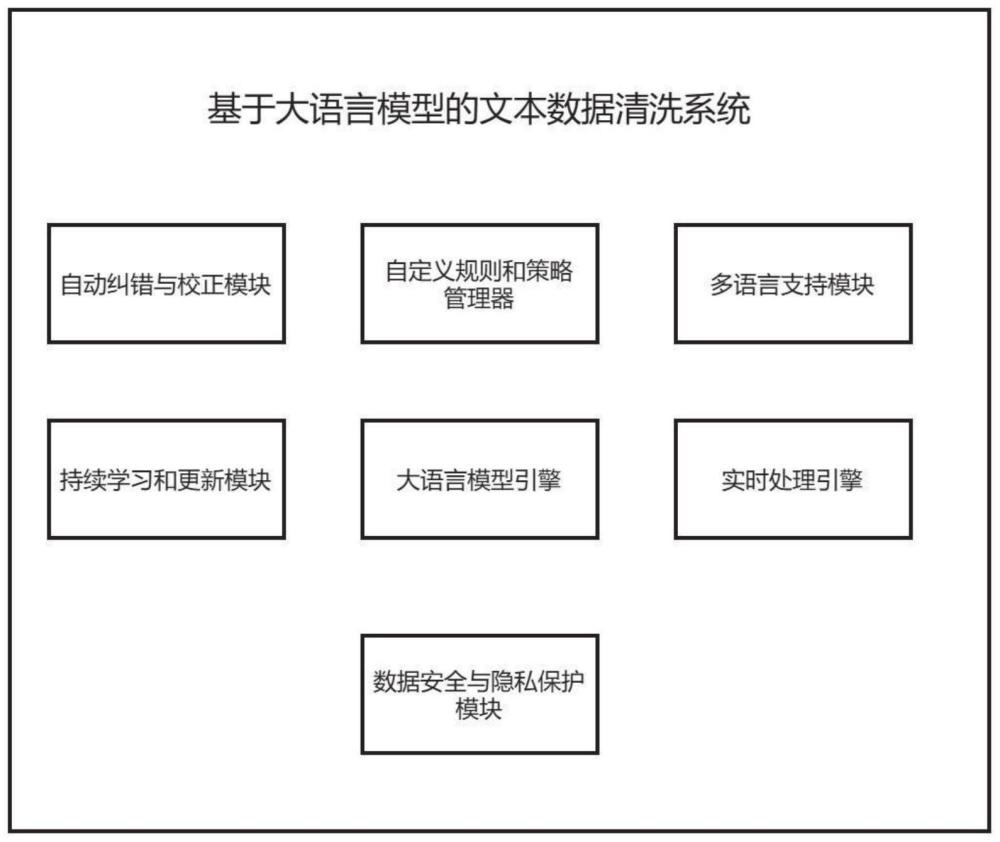
2、为实现上述目的,本发明提供了一种基于大语言模型的文本数据清洗系统,包括大语言模型引擎、自动纠错与校正模块、自定义规则和策略管理器、多语言支持模块、实时处理引擎、持续学习和更新模块、数据安全与隐私保护模块;
3、其中,所述大语言模型引擎是整个系统的核心,为其他模块提供文本理解和生成的基础;所述自动纠错与校正模块通过与所述大语言模型引擎的交互,实现对文本错误的自动检测和修正;所述自定义规则和策略管理器与所述大语言模型引擎协同工作,用户可以通过定义规则来调整和增强系统的清洗能力;所述多语言支持模块利用所述大语言模型引擎的多语言能力,确保系统可以处理不同语言的文本数据;所述实时处理引擎确保系统能够高效处理大规模文本数据,并在分布式环境中运行;所述持续学习和更新模块通过与所述大语言模型引擎的交互,使系统能够不断学习新的文本数据并更新模型,保持对新兴文本和表达方式的敏感性;所述数据安全与隐私保护模块贯穿整个系统,确保用户数据在处理过程中得到保护。
4、优选地,所述大语言模型引擎集成了大型预训练语言模型和/或自训练的文本清洗模型,负责文本数据的理解、分析和生成。
5、优选地,所述自动纠错与校正模块利用所述大语言模型引擎提供的语言理解和生成能力,自动检测并纠正文本中的拼写错误、语法问题,在文本数据的清洗过程中,提高数据质量,降低误码率。
6、优选地,所述自定义规则和策略管理器提供用户友好的界面,允许用户定义和管理自定义的清洗规则和策略,使用户能够根据特定领域或任务的需求,创建个性化的清洗规则,增强系统的适应性。
7、优选地,所述个性化的清洗规则包括以下的一种或多种:
8、(l)术语替换规则:替换文本中的特定术语,以符合特定领域的用语;
9、(2)过滤特定内容规则:过滤或屏蔽文本中的特定类型的内容,以满足用户的特定需求;
10、(3)定制纠错规则:针对特定常见错误进行自定义的纠错操作;
11、(4)语法规范化规则:统一文本中的语法结构,使其符合特定的书写规范;
12、(5)清理html标签规则:从文本中移除html标签,以确保纯文本内容;
13、(6)语言敏感性规则:针对特定语言的文本应用不同的清洗策略;
14、(7)定制化标记规则:根据用户需求,添加或删除文本中的特定标记;
15、(8)符号替换规则:替换文本中的特定符号,以适应特定场景的需求。
16、优选地,所述多语言支持模块通过语言识别算法和/或模型来实现,能够根据文本的语言特征识别文本所属的语言。
17、优选地,所述实时处理引擎可以在分布式环境下运行,充分利用硬件资源,提供快速的数据清洗;能够高效处理大规模文本数据,支持实时处理需求。
18、优选地,所述持续学习和更新模块通过不断与新的文本数据交互,更新语言模型,以适应新兴文本和表达方式,保持对新趋势的敏感性,保持了清洗质量和效果的持续提升。
19、优选地,所述持续学习和更新模块的实现流程为:
20、(1)数据收集和存储
21、实现数据收集器,从各种数据源中收集新的文本数据,并将其存储在系统指定的数据存储中;同时在线上服务中收集清洗前后的数据对,作为用于优化模型的训练数据;
22、(2)在线学习算法、增量式训练
23、使用在线学习算法,允许模型在运行时从新数据中学习;针对在线学习场景,选择适当的算法,确保模型能够有效地利用新数据进行更新,而无需重新训练整个模型;
24、(3)模型更新策略
25、定期对模型进行评估,比较新模型与旧模型在一组标准任务上的性能,并根据评估结果决定是否更新模型。
26、优选地,所述数据安全与隐私保护模块实施数据加密、权限控制和匿名化,确保用户数据的隐私和安全,保障系统在处理敏感信息时符合相关法规,防范潜在的数据泄露和滥用。
27、本发明还提供了一种基于大语言模型的文本数据清洗方法,包括以下步骤:
28、输入待清洗文本,系统预设的规则和策略管理器选择自定义清洗方法,根据选择的方法处理待清洗文本,输出为模板化的模型输入文本;
29、模型输入文本将经过大语言模型引擎处理后,输出清洗后的格式规范化文本;
30、安全与隐私模块将通过自然语言处理算法,识别格式规范化文本的数据中存在的安全和隐私文本,保证输出文本的安全性;
31、最终输出清洗后的文本。
32、本发明还提供了一种基于大语言模型的文本数据清洗系统的大数据语言模型更新方法,大语言模型引擎的更新是通过持续学习和更新模块进行训练和微调,更新将基于外部训练数据构建清洗模型数据集,根据需求定期更新大语言模型引擎。
33、本发明的技术效果:
34、(1)更高的自动化程度:相对于传统的文本数据清洗方法,本系统利用大语言模型的能力,能够更自动化地检测和纠正拼写错误、语法问题等,减少了用户的手动干预需求,提高了操作效率。
35、(2)更准确的清洗:由于语言模型能够理解上下文,提供更准确的修复建议,因此可以显著降低误码率,改善了数据的质量。
36、(3)个性化和定制化:本系统允许用户根据特定领域的需求创建自定义清洗规则和策略,从而提供了更高度个性化的文本清洗能力,满足了不同用户和应用场景的需求。
37、(4)多语言支持:与传统方法相比,系统能够处理多种语言的文本数据,扩展了应用范围,使其更适用于国际化和多语言环境。
38、(5)实时处理和高效性:本系统被设计为能够高效处理大规模文本数据,支持实时处理需求,提高了处理速度和效率。
39、(6)持续学习和更新:通过与新的文本数据交互,系统能够不断学习和适应新兴文本和表达方式,保持了清洗质量和效果的持续提升。
40、以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
- 还没有人留言评论。精彩留言会获得点赞!