目标和语义感知的图像融合模型、训练方法及使用方法
本技术涉及图像处理,具体而言,涉及一种目标和语义感知的图像融合模型、训练方法及使用方法。
背景技术:
1、多传感器集成系统在无人机精确作战和自动驾驶等智能技术中不可或缺。随着传感器制造水平的提高,综合利用多模态图像进行复杂现实世界场景分析变得越来越重要。目前广泛使用的可见光和红外传感器各有其局限性。可见光传感器难以在弱光条件下有效突出目标,而红外传感器则不受这个问题的影响,但场景分辨率低,对纹理细节的捕捉能力差。然而,多模态图像融合可以通过综合多种来源的数据来解决这些问题,弥补单模态数据的信息损失,增强人类和机器视觉的理解和感知能力。此外,图像融合有望更准确地呈现目标和场景,从而对目标检测和语义分割等下游任务产生积极影响。
2、因此,有必要寻求一种多模态图像融合方法,在融合图像中充分保留原图像的有用特征,提高图像的融合精度。
技术实现思路
1、本技术的目的在于提供一种目标和语义感知的图像融合模型、训练方法及使用方法,能够通过充分提取图像中的全局和局部信息对图像进行融合处理,在融合图像中充分保留原图像的有用特征,提高图像的融合精度。
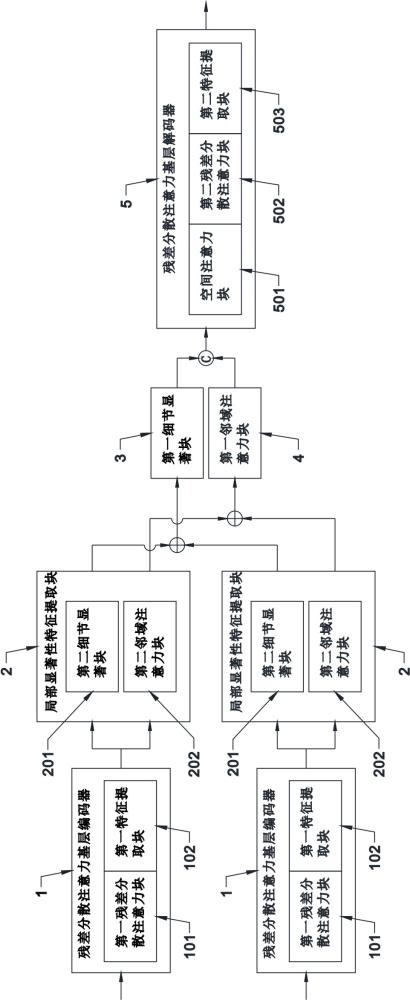
2、第一方面,本技术提供了一种目标和语义感知的图像融合模型,用于对配准的可见光图像和红外光图像进行融合处理,包括两个残差分散注意力基层编码器、两个局部显著性特征提取块、第一细节显著块、第一邻域注意力块和残差分散注意力基层解码器;
3、两个所述残差分散注意力基层编码器的输出端分别与两个所述局部显著性特征提取块的输入端连接,两个所述残差分散注意力基层编码器分别用于输入可见光图像和红外光图像,并从相应的输入图像中提取分层特征图像以输出至对应的所述局部显著性特征提取块;
4、所述局部显著性特征提取块用于从输入的所述分层特征图像中提取细节特征图和显著特征图,两个所述局部显著性特征提取块提取的所述细节特征图相加后输入所述第一细节显著块,两个所述局部显著性特征提取块提取的所述显著特征图相加后输入所述第一邻域注意力块;
5、所述第一细节显著块的输出端和所述第一邻域注意力块的输出端级联后与所述残差分散注意力基层解码器的输入端连接;所述第一细节显著块用于融合输入的两个所述显著特征图得到融合显著特征图,并输出所述融合显著特征图;所述第一邻域注意力块用于融合输入的两个所述细节特征图得到融合细节特征图,并输出所述融合细节特征图;
6、所述残差分散注意力基层解码器用于对所述融合细节特征图和所述融合显著特征图进行解码操作得到融合结果,并输出所述融合结果。
7、提取可见光图像和红外光图像的细节特征图和显著特征图后,对两个细节特征图进行融合得到融合显著特征图,并对两个显著特征图进行融合得到融合显著特征图,最后对融合细节特征图和融合显著特征图进行解码得到融合结果,从而能够通过充分提取图像中的全局和局部信息对图像进行融合处理,在融合图像中充分保留原图像的有用特征,提高图像的融合精度。
8、优选地,所述残差分散注意力基层编码器包括依次连接的第一残差分散注意力块和基于卷积的第一特征提取块。
9、把残差分散注意力块作为残差分散注意力基层编码器的一部分,可以增强残差分散注意力基层编码器促进红外光图像和可见光图像之间复杂的交叉特征交互的能力,而基于卷积的特征提取块可以进一步深化残差分散注意力基层编码器的特征提取能力。
10、优选地,所述局部显著性特征提取块包括相互独立的第二细节显著块和第二邻域注意力块,所述第二细节显著块用于从对应的所述分层特征图像中提取所述显著特征图,所述第二邻域注意力块用于从对应的所述分层特征图像中提取所述细节特征图。
11、由于不同模态图像(红外光图像和可见光图像)的细粒度特征明显不同,针对该情况,上述结构的局部显著性特征提取块能够在跨模态特征提取过程中有效地提取重要的局部信息。
12、优选地,所述第一细节显著块和所述第二细节显著块均包括输入层、第一分支、第二分支和输出层,所述第一分支和所述第二分支的输入端均与所述输入层连接,所述第一分支和所述第二分支的输出端相加后与所述输出层连接;
13、所述第一分支包括第一卷积层、最大池化层、第一平均池化层、全局平均池化层、两个全连接层和sigmoid激活函数层,所述第一卷积层的输出端分别与所述最大池化层和所述第一平均池化层连接,所述最大池化层和所述第一平均池化层的输出端相乘后与所述全局平均池化层和两个所述全连接层依次连接,所述最大池化层和所述第一平均池化层的输出端相乘后还与最后一个所述全连接层的输出端相乘后连接至所述sigmoid激活函数层;
14、所述第二分支包括第二卷积层、第二平均池化层和relu激活函数层,所述第二卷积层的输出端与所述第二平均池化层的输入端连接,所述第二卷积层的输出端还与所述第二平均池化层的输出端相加后与所述relu激活函数层连接。
15、优选地,所述残差分散注意力基层解码器包括依次连接的空间注意力块、第二残差分散注意力块和基于卷积的第二特征提取块;所述第二残差分散注意力块与所述第一残差分散注意力块的结构相同,所述第二特征提取块与所述第一特征提取块的结构相同。
16、第二方面,本技术提供了一种如前文所述的目标和语义感知的图像融合模型的训练方法,包括:联合预设目标检测络模型和预设语义分割模型,基于以下总损失函数对所述目标和语义感知的图像融合模型进行训练:
17、;
18、其中,为所述总损失函数,为关于所述目标和语义感知的图像融合模型的融合损失,为关于所述预设目标检测络模型的检测损失,为关于所述预设语义分割模型的语义损失。
19、优选地,所述融合损失为:
20、;
21、其中,、、为可调参数;
22、为多样性损失,且,所述残差分散注意力基层解码器生成的注意力权重矩阵,m和n分别为所述注意力权重矩阵的行数和列数,为所述注意力权重矩阵的第i行第j列的值;
23、为像素级l1范数损失,且,p为图像的长,q为图像的宽,f为所述目标和语义感知的图像融合模型输出的融合结果,i为输入所述目标和语义感知的图像融合模型的红外光图像,v为输入所述目标和语义感知的图像融合模型的可见光图像;
24、为损失结果相似性指数,且,ssim为计算两张图像的结构相似度的相似度函数;
25、为关于红外光图像的均方根误差损失,且,为把对应于所述红外光图像的所述局部显著性特征提取块输出的细节特征图和显著特征图输入一个训练用编码器后得到的所述训练用编码器的输出图像;所述训练用编码器的结构与所述残差分散注意力基层解码器的结构相同;
26、为关于可见光图像的均方根误差损失,且,为把对应于所述可见光图像的所述局部显著性特征提取块输出的细节特征图和显著特征图输入所述训练用编码器后得到的所述训练用编码器的输出图像。
27、优选地,所述检测损失为:
28、;
29、其中,为把输入所述目标和语义感知的图像融合模型的红外光图像输入所述预设目标检测络模型时,所述预设目标检测络模型的检测结果与对应真值之间的检测损失;为把输入所述目标和语义感知的图像融合模型的可见光图像输入所述预设目标检测络模型时,所述预设目标检测络模型的检测结果与对应真值之间的检测损失;为把所述目标和语义感知的图像融合模型输出的融合结果输入所述预设目标检测络模型时,所述预设目标检测络模型的检测结果与对应真值之间的检测损失。
30、优选地,所述语义损失为:
31、;
32、其中,p为图像的长,q为图像的宽,为把所述目标和语义感知的图像融合模型的融合结果输入所述预设语义分割模型时,所述预设语义分割模型的输出结果中像素位置(p, q)处的真实类指数,是把所述目标和语义感知的图像融合模型的融合结果输入所述预设语义分割模型时,所述预设语义分割模型的输出结果中像素位置(p, q)上属于类别j的预测值,是把所述目标和语义感知的图像融合模型的融合结果输入所述预设语义分割模型时,所述预设语义分割模型的输出结果中像素位置(p, q)上属于类别的预测值,c为总的类别数。
33、第三方面,本技术提供了一种目标和语义感知的图像融合模型使用方法,基于前文所述的目标和语义感知的图像融合模型,包括步骤:
34、a1.获取配准的红外光图像和可见光图像;
35、a2.把所述红外光图像和所述可见光图像分别输入所述目标和语义感知的图像融合模型的两个所述残差分散注意力基层编码器,得到所述目标和语义感知的图像融合模型输出的融合结果。
36、有益效果:本技术提供的目标和语义感知的图像融合模型、训练方法及使用方法,提取可见光图像和红外光图像的细节特征图和显著特征图后,对两个细节特征图进行融合得到融合显著特征图,并对两个显著特征图进行融合得到融合显著特征图,最后对融合细节特征图和融合显著特征图进行解码得到融合结果,从而能够通过充分提取图像中的全局和局部信息对图像进行融合处理,在融合图像中充分保留原图像的有用特征,提高图像的融合精度。
- 还没有人留言评论。精彩留言会获得点赞!