一种基于约束规则和相似度的工控异常检测数据集均衡方法与流程
本技术涉及工业控制系统安全领域,更具体地,涉及一种基于约束规则和相似度的工控异常检测数据集均衡方法。
背景技术:
1、工业控制系统异常检测是确保工业过程稳定运行的重要组成部分。异常检测系统通过监测传感器、执行器数据或其他相关信息来识别可能表明设备或过程出现问题的异常情况。训练数据集的均衡对于异常检测模型的性能至关重要,使用不平衡的数据集训练模型可能导致模型对于少数类别的异常样本学习不足。
2、目前用于工业控制系统异常检测训练数据集均衡的方法包括采样方法(如欠采样和过采样)、生成合成样本(如smote)、权重调整、交叉验证策略和特征工程。然而,这些方法存在一些不足。欠采样可能导致信息丢失,削减了正常样本的数量,影响模型对正常情况的全面理解。生成合成样本的质量成为关键问题,低质量的合成样本可能降低模型的泛化能力。过采样和生成合成样本也带来了过拟合风险,特别是在异常样本多样性较大的情况下。方法的算法复杂性增加了系统的维护难度,而一些方法对特征的依赖性高,可能导致在变化的实际场景中性能下降。
3、cn116521312a公开了一种基于深度学习模型检测非平衡工控数据异常的方法;其对工业控制流量数据进行预处理;使用基于约束的pc算法来获得工业控制系统源域和目标域网络层数据特征之间的因果图和邻接矩阵;将因果图中的节点裁剪分为三部分:高影响节点集群、中影响节点集群、低影响节点集群;对源域和目标域的工业控制网络流量特征,通过通信协议进行粗分类,获得初步的特征映射集;然而,其并没有采集及利用异常数据,故存在着速度慢、准确度低等缺陷。
4、基于上述背景,本发明提供一种基于约束规则和相似度的工控异常检测数据集均衡方法。本发明在生成随机异常样本前制定了一组符合当前工业控制系统特点的约束规则,能够快速生成与真实数据集数据分布相似的异常样本。使用真实样本训练孪生网络,通过孪生网络计算样本相似度,能够对生成的异常样本进一步筛选,符合条件的异常样本将纳入数据集。最后构成异常样本与正常样本数量相同的训练数据集,完成数据集均衡。相比于现有的方法,具有生成均衡数据集速度快,生成的异常样本符合真实异常样本数据分布,样本质量高的特点。
技术实现思路
1、本技术实施例的目的在于提供一种基于约束规则和相似度的工控异常检测数据集均衡方法,解决了工业控制系统中,异常数据少,采样的训练数据集正常样本和异常样本极度不均衡的问题。具有生成均衡数据集速度快,生成的异常样本符合真实异常样本数据分布,样本质量高的特点。
2、为实现上述目的,本技术提供如下技术方案:
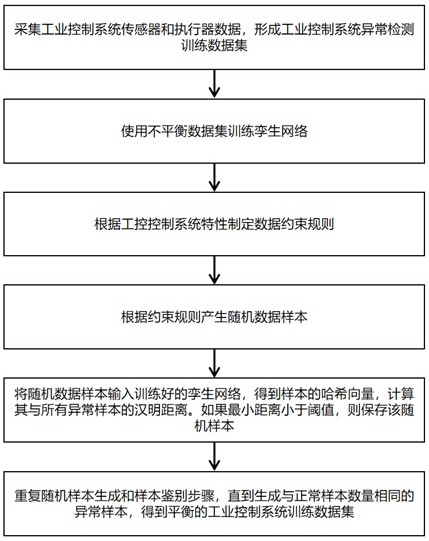
3、一种基于约束规则和相似度的工控异常检测数据集均衡方法,其特征在于包含有以下步骤:采集工业控制系统传感器和执行器数据并形成工业控制系统异常检测训练数据集的步骤;使用不平衡数据集训练孪生网络的步骤;根据工控控制系统特性制定数据约束规则的步骤;根据约束规则产生随机数据样本的步骤;将随机数据样本输入训练好的孪生网络,得到样本的哈希向量,计算其与所有异常样本的汉明距离,如果最小距离小于阈值,则保存该随机样本的步骤;重复随机样本生成和样本筛选步骤,直到生成与正常样本数量相同的异常样本,得到平衡的工业控制系统训练数据集的步骤。
4、更具体地,上述所述的一种基于约束规则和相似度的工控异常检测数据集均衡方法,其特征在于,包括以下具体步骤:
5、(1)在工控异常检测训练数据集准备阶段,根据周期t实时采集工业控制系统中的传感器和执行器数据,每个周期能够得到一个数据样本d=(x,y),其中nc为工业控制系统中的执行器和传感器的总数量。y是根据当前时刻工业控制系统的状态决定,如果工业控制系统正常,则y为0,否则为1;
6、(2)根据步骤(1)采集工业控制系统中的数据,直到标签y为1的样本数量达到nt,将采集的所有数据样本构成一个异常检测训练数据集d={d1,d2,d3…dn},完成数据集准备阶段,其中n为采集的数据样本总量。由于工业控制系统中通常故障几率小,d中仅包含少量的异常数据样本;
7、(3)在孪生网络训练阶段,使用工业控制系统异常检测训练数据集d,通过组合的方式将其中的样本进行配对,多个数据对构成孪生网络训练数据集其中n为采集的数据样本总量,c为排列运算,i代表数据对的编号;
8、(4)读取数据集dsia中的每一个数据对依次将和送入当前参数为θ的孪生网络中,孪生网络将输出样本的哈希向量和其中的孪生网络可选用卷积神经网络,循环神经网络等。使用排序损失函数计算孪生网络在数据集dsia中的损失,以优化孪生网络的参数。具体地,排序损失l的计算方式如下:
9、
10、
11、
12、其中ki代表第i个数据对中两个样本的标签一致性,如果ya=yb,则ki为1,否则ki为0。dis为和之间的汉明距离。z为数据对的总数,λ为决策边界的距离;
13、(5)根据步骤(4)计算得到的排序损失,使用梯度下降法对当前模型的参数进行更新,得到更新模型参数θnew:
14、
15、其中η为学习率;
16、(6)重复步骤(4)至步骤(5),直到训练损失l小于设定阈值,或迭代次数达到最大设定次数。得到训练好的孪生网络
17、(7)在工控异常检测数据集均衡阶段,使用随机空间产生随机样本,经过孪生网络的判断,筛选出合格样本。其目的是根据已有的数据样本特征,生成接近真实数据集数据分布的异常样本,使正常和异常样本的数量一致。优质的均衡数据集能训练出检测准确率更高的异常检测模型,使模型的性能更好;
18、(8)根据工业控制系统的特性,制定多个约束项,组成一组数据约束规则,使产生的随机样本能够符合工业控制系统真实数据集的数据分布。约束规则应该由采集的传感器和执行器在工业控制系统中的位置、作用等因素决定,每个约束项对应一个具体的传感器或执行器。具体的约束项格式如下表所示:
19、
20、(9)根据步骤(8)制定的约束规则,随机产生一组符合约束规则的数据构成随机样本nc为工业控制系统中的执行器和传感器的总数量。优质约束规则能使生成的随机样本合格率更高;
21、(10)将随机样本r送入训练好的孪生网络孪生网络将输出样本的哈希向量hr;
22、(11)从异常检测训练数据集d中抽取所有y=1的异常样本dabn={di,di(y)=1,1≤i≤n},计算hr和所有真实异常样本的汉明距离h={dhi,1≤i≤n},取其中的最小值hm=minih(i),如果hm小于设置的阈值th,则将随机样本r存入数据集dsys,否则重新开始步骤(9);
23、(12)重复步骤(9)至步骤(11),直到dabn∪dsys构成的数据集的样本数量与数据集d中的正常样本数量相同;
24、(13)合并异常检测训练数据集d和经过筛选的随机样本数据集dsys,得到正常样本和异常样本一致的训练数据集dbal。使用优质的均衡异常检测训练数据集训练工业控制系统异常检测模型,可以使模型的检测准确率更高,性能更好。
25、与现有技术相比,本发明的有益效果是:本发明在生成随机异常样本前制定了一组符合当前工业控制系统特点的约束规则,能够快速生成与真实数据集数据分布相似的异常样本。使用真实样本训练孪生网络,通过孪生网络计算样本相似度,能够对生成的异常样本进一步筛选,符合条件的异常样本将纳入数据集。最后构成异常样本与正常样本数量相同的训练数据集,完成数据集均衡。解决了工业控制系统中,异常数据少,采样的训练数据集正常样本和异常样本极度不均衡的问题。通过约束规则,加快了样本均衡过程的整体耗时。产生的均衡数据集能够训练高准确率的工控异常检测模型,提供了一种基于约束规则和相似度的工控异常检测数据集均衡方法。
- 还没有人留言评论。精彩留言会获得点赞!