一种基于开源大模型的垂直领域意图识别方法与流程
本发明属于数据处理,具体涉及一种基于开源大模型的垂直领域意图识别方法。
背景技术:
1、ic(intent classification)即意图识别,是nlp(natural languageprocessing)自然语言处理领域里面的重要任务,如何有效的进行意图识别是该领域的一个重要方向,其识别效果直接决定下游的效果,例如在对胡领域、智能客服领域。特别是在垂直领域任务中,例如线上智能销售、医疗助手、财务助手等不同领域,需要基于明确的意图结果来进行相关的处理,识别结果的准确率和召回率对于后续的处理效果影响巨大,如果识别错误会产生巨大的负面影响,如何在保障准确率的前提下逐步提升召回率是当前的一个行业痛点。
2、特别是针对网络化、口语化、地域化等场景,例如在当前如火如荼的短视频和直播领域,用户的表达方式更为随意,识别的难度在逐步加大。传统方法需要依赖大量的规则、标注数据来进行识别模型的逐步提升,其核心的本质原因在于原有模型对于现实世界的认知不足,所能容纳的语义空间有限,针对未登录内容不能很好的理解,不能很好的处理这类任务,整体的优化维护成本较高。但随着大模型(large language model,后面简称llm)的出现,为更好的进行意图识别任务提供了新的方法和可行性,由于llm对现实世界有着更为丰富的认知,模型本身蕴含的语义空间足够丰富,能够更好的解决现有模型的痛点。
3、现有技术的缺点:
4、1、模型的泛化能力较弱,过度依赖于标注数据,针对未见场景的识别能力较弱。由于现有模型一般采用bert等小规模预训练模型,其规模较小,对于现实世界的语义表达有限,无法处理和预训练数据分布差异较大的场景。导致在口语化、地域化的表达上表现较差;
5、2、迭代维护成本过高,模型能力的提升,严重依赖数据反馈,需要不断的标注badcase以及增加新的场景来提升准确率和召回率;
6、3、缺乏一定的推理能力,针对待处理内容缺乏推理理解,只能处理当前语句中的数据,无法很好的识别上下文相关内容,特别是在多轮对话中,存在反问、讽刺、跳跃等多种情况,传统基于单句的意图模型无法处理;
7、4、过度依赖算法人员的能力,模型的效果好坏与算法人员的能力正相关,对人的依赖较大;
8、5、新增意图困难,新增意图需要考虑是否和原有意图有重叠或者模糊的场景,如果和原有意图有重叠,需要针对历史意图的语料进行二次处理。
9、6、多意图支持效果不佳,在多意图的场景下表现较差,由于缺乏推理能力,在复杂场景下会导致多意图错误明显的情况,例如在闲聊和买车场景,如果仅依赖单轮对话,在对话中很多场景都会归为闲聊场景。实际上整体是买车意图。
技术实现思路
1、本发明为了解决上述现有技术中存在的缺陷和不足,提供了一种面向行业的通用的意图识别能力,支持多意图的同时识别,能够高质量、快速的支持面向行业的意图识别任务,降低意图识别的模型难度,在面向新场景中依然有较强的快速启动能力,能低成本的解决意图识别的潜在问题,为依赖的下游任务提供更精准可靠的识别结果的基于开源大模型的垂直领域意图识别方法。
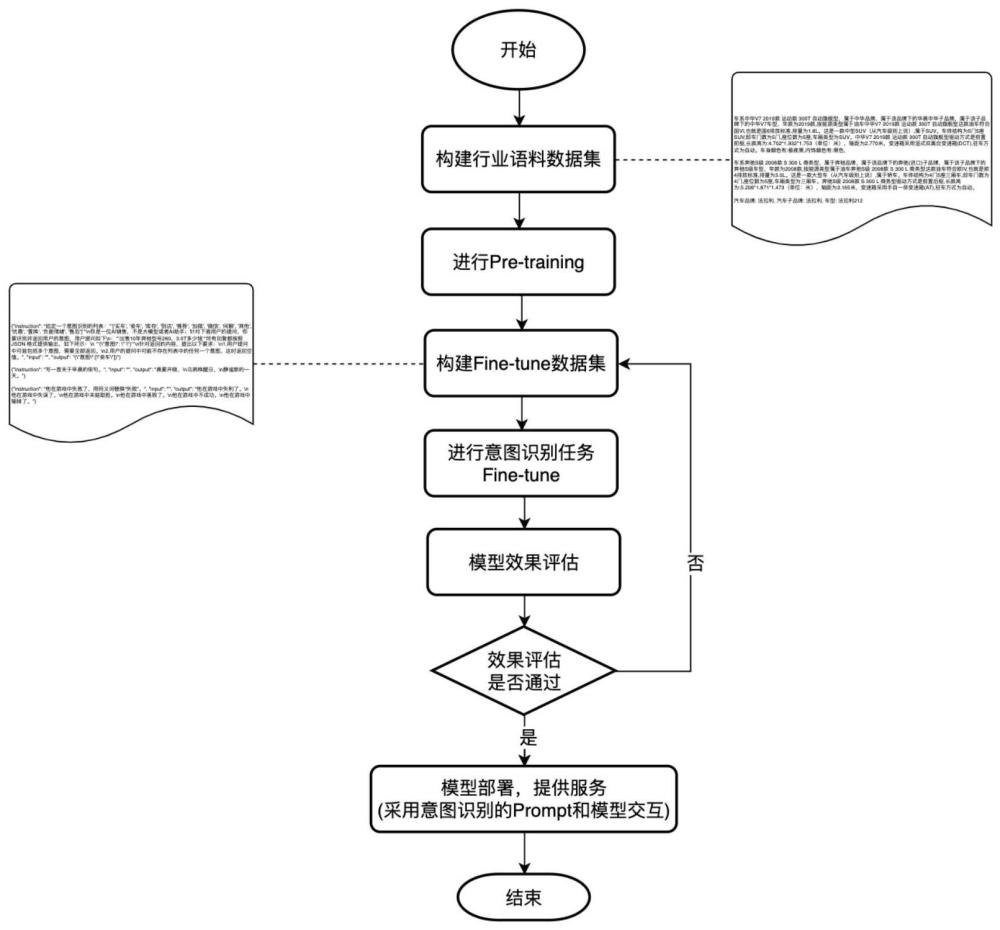
2、本发明提供如下技术方案:一种基于开源大模型的垂直领域意图识别方法,步骤如下:
3、步骤一、准备pre-training语料;
4、步骤二、基于构建好的行业语料库进行pre-training,将行业语料数据作为新的语料进行训练,让模型融合行业数据;
5、步骤三、基于自身的对话数据构造标注数据;
6、步骤四、基于构造好的标注数据进行fine-tune;
7、步骤五、基于原有的开源模型的评估数据集和自身构建的评估数据集进行模型效果的评估;
8、步骤六、启动fine-tune后的模型,将意图识别任务的模板固化,针对输入的对话采用实体识别的prompt模板来和模型交互,输出格式化的json数据,得到模型的结果。
9、优选地,步骤一具体是指针对当前的行业准备这个行业相关实体和对话的语料,尽可能的提供更多的语料,但需要确保语料不重复、语料的正确性。
10、优选地,步骤二中需要考虑要处理的场景,如果是中文场景,需要并基于中文模型基座,选择的是chinese-llama-alpaca-2。
11、优选地,步骤三中以对话数据进行改造,不以单句输入作为标注数据,每次以对话数据作为待标注数据,基于对话进行标注,即一个n轮的对话可以拆分成n个标注数据,都已当轮加历史对话数据作为输入,标注出到目前为止用户所表达的意图到底是什么,能够解决原有意图识别模型无法做多轮的推理问题。
12、优选地,步骤四中数据量不得少于2000条,且需要和原有模型的fine-tune数据集一起使用,确保模型在获得新的能力的同时保留原有能力。
13、优选地,步骤二中采用的是chinese-llama-alpaca-2的7b版本,在算力允许的情况下可以选择参数量更大的chinese-llama-alpaca-2的13b版本,或者可以选择通义千问的开源版本或者百川的开源版本。
14、优选地,步骤二中采用的是v100 4卡32g的机器进行训练或者根据不同情况选择不同配置的机器进行训练。
15、优选地,步骤一中选择的是汽车行业的数据或者选择其他行业的数据。
16、优选地,考虑多轮对话场景,在数据构造的时候采用多轮对话作为fine-tune语料,如果不存在多轮的场景,可以使用单句语料进行标注,降低标注难度。例如问答场景。
17、本发明的有益效果如下:
18、1、泛化能力增强,能够更好的处理长尾问题,例如输入的不规范、输入的错别字、口语化的表达等。由于大模型在预训练期间有了足够多的现实世界的语料,所以模型本身蕴含了对于现实世界的理解,针对长尾问题相比原有模型,其覆盖能力明显增加;
19、2、扩展能力增强,能够更方便的增加新的意图,例如原来识别20个意图,现在需要增加1个意图。在原有模型的处理流程中,需要针对历史的标注输入进行清洗,把和新增意图有冲突的语料进行纠正。但采用llm方案不需要对历史数据做过多干预,只需增加新的数据即可,模型的能力可以实现叠加;
20、3、在多轮对话中表现良好,传统算法一般都是基于单句进行识别,在多轮对话中会失效,即如果出现上下文中推理问题,意图转折、跳转等情况,模型不能很好的处理。但基于llm进行处理,能够有效的解决这列上下文推理问题;
21、4、能够有效的支持多意图的识别,充分利用llm本身的推理能力,让多意图识别更为精准。
技术特征:
1.一种基于开源大模型的垂直领域意图识别方法,其特征在于,步骤如下:
2.根据权利要求1所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:步骤一具体是指针对当前的行业准备这个行业相关实体和对话的语料,尽可能的提供更多的语料,但需要确保语料不重复、语料的正确性。
3.根据权利要求1所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:步骤二中需要考虑要处理的场景,如果是中文场景,需要并基于中文模型基座,选择的是chinese-llama-alpaca-2。
4.根据权利要求1所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:步骤三中以对话数据进行改造,不以单句输入作为标注数据,每次以对话数据作为待标注数据,基于对话进行标注,即一个n轮的对话可以拆分成n个标注数据,都已当轮加历史对话数据作为输入,标注出到目前为止用户所表达的意图到底是什么,能够解决原有意图识别模型无法做多轮的推理问题。
5.根据权利要求1所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:步骤四中数据量不得少于2000条,且需要和原有模型的fine-tune数据集一起使用,确保模型在获得新的能力的同时保留原有能力。
6.根据权利要求3所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:步骤二中采用的是chinese-llama-alpaca-2的7b版本,在算力允许的情况下可以选择参数量更大的chinese-llama-alpaca-2的13b版本,或者可以选择通义千问的开源版本或者百川的开源版本。
7.根据权利要求1所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:步骤二中采用的是v100 4卡32g的机器进行训练或者根据不同情况选择不同配置的机器进行训练。
8.根据权利要求2所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:步骤一中选择的是汽车行业的数据或者选择其他行业的数据。
9.根据权利要求1所述的一种基于开源大模型的垂直领域意图识别方法,其特征在于:考虑多轮对话场景,在数据构造的时候采用多轮对话作为fine-tune语料,如果不存在多轮的场景,可以使用单句语料进行标注,降低标注难度。
技术总结
本发明公开了一种基于开源大模型的垂直领域意图识别方法,步骤如下:准备Pre‑training语料;基于构建好的行业语料库进行Pre‑training;基于自身的对话数据构造标注数据;基于构造好的标注数据进行Fine‑tune;基于原有的开源模型的评估数据集和自身构建的评估数据集进行模型效果的评估;启动Fine‑tune后的模型,将意图识别任务的模板固化,针对输入的对话采用实体识别的Prompt模板来和模型交互,输出格式化的JSON数据,得到模型的结果。本发明面向行业的通用的意图识别能力,支持多意图的同时识别,能够高质量、快速的支持面向行业的意图识别任务,降低意图识别的模型难度,能低成本的解决意图识别的潜在问题。
技术研发人员:刘广兴
受保护的技术使用者:杭州百聆科技有限公司
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!