风电功率曲线异常值识别方法、装置、设备及存储介质与流程
本发明涉及风电数据异常识别,尤其涉及一种风电功率曲线异常值识别方法、装置、设备及存储介质。
背景技术:
1、在电力大数据当中,风电机组运行数据是重要的组成部分,是后续对风电功率波动特性与风电功率预测等研究的基础。但是受到弃风限电、表计误差、环境气候等因素影响,风电机组监控和数据采集系统(supervisory control and data acquisition,scada)实际采集的数据中含有大量的异常值。若直接将这些数据用于分析,后续预测结果的准确性以及分析结果的可靠性将会大打折扣。因此,通过对风电机组实测数据中的异常值进行识别,获得真实可靠的风电场相关运行数据对后续评估风电厂运行状态、风速与功率预测很有必要。
2、如今,针对无标签的风电功率数据集,异常值识别多采用非监督学习方法,如基于密度噪声应用空间聚类算法(density-based spatial clustering of applicationswith noise,dbscan)将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,将簇定义为密度相连的点的最大集合。因此dbscan对分散型异常值的识别效果较好,但对于高密度聚集型的异常值识别效果较差。
技术实现思路
1、本发明提供了一种风电功率曲线异常值识别方法、装置、设备及存储介质,用于解决高密度聚集型风电功率数据异常数据识别效果较差的技术问题。
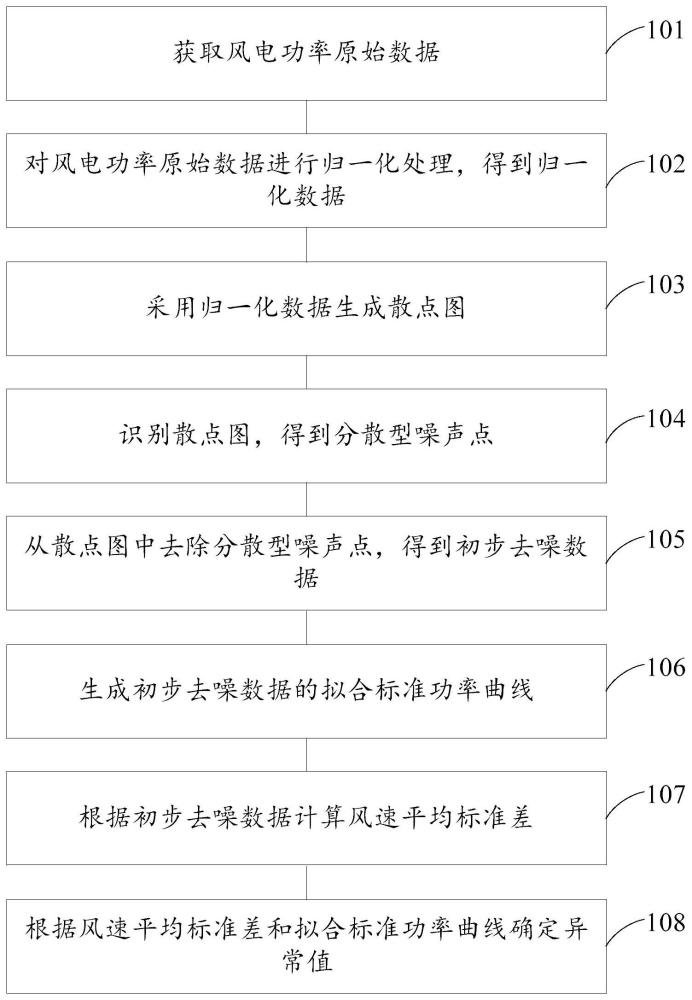
2、本发明了一种风电功率曲线异常值识别方法,包括:
3、获取风电功率原始数据;
4、对所述风电功率原始数据进行归一化处理,得到归一化数据;
5、采用所述归一化数据生成散点图;
6、识别所述散点图,得到分散型噪声点;
7、从散点图中去除所述分散型噪声点,得到初步去噪数据;
8、生成所述初步去噪数据的拟合标准功率曲线;
9、根据所述初步去噪数据计算风速平均标准差;
10、根据所述风速平均标准差和所述拟合标准功率曲线确定异常值。
11、可选地,所述对所述风电功率原始数据进行归一化处理,得到归一化数据的步骤,包括:
12、获取所述风电功率原始数据中的最大功率数据、最小功率数据、最大风速数据和最小风速数据;
13、采用所述最大功率数据、所述最小功率数据、所述最大风速数据和所述最小风速数据对所述风电功率原始数据进行归一化处理,得到归一化数据。
14、可选地,所述识别所述散点图,得到分散型噪声点的步骤,包括:
15、随机选择所述散点图中的任意未访问数据点作为已访问点;
16、按照预设半径确定所述已访问点的第一邻域,并获取所述第一邻域的第一点集;
17、统计所述第一邻域内的数据点数;
18、当所述数据点数不小于预设最小数据点数阈值时,生成所述已访问点的点簇;
19、分别将所述第一点集内的每个数据点标记为新已访问点;
20、按照预设半径确定所述新已访问点的第二邻域,并获取所述第二邻域的第二点集;
21、当所述第二邻域内的数据点数不小于所述预设最小数据点数阈值时,采用所述第二点集更新所述第一点集;
22、判断所述新已访问点是否有归属,若否,将所述新已访问点添加进所述点簇中,若是,将所述新已访问点添加进预设离群点集中;
23、当所述第一点集中的数据均完成访问时,返回随机选择所述散点图中的任意未访问数据点作为已访问点的步骤,直至所述散点图中的数据点均完成访问,输出所述离群点中的数据点作为分散型噪声点。
24、可选地,所述生成所述初步去噪数据的拟合标准功率曲线的步骤,包括:
25、将所述初步去噪数据划分为若干个功率区间;
26、计算各所述功率区间的风速均值和功率均值作为密度中点;
27、以风速为自变量、功率为目标变量,建立所述功率区间的三次多项式模型;
28、以功率残差绝对值的总和最小为目标,采用所述密度中点和所述三次多项式模型的待拟合参数生成优化模型;
29、通过梯度下降法求解所述优化模型,得到所述待拟合参数的参数值;
30、将所述参数值代入所述三次多项式模型,生成拟合标准功率曲线。
31、本发明还提供了一种风电功率曲线异常值识别装置,包括:
32、风电功率原始数据获取模块,用于获取风电功率原始数据;
33、归一化模块,用于对所述风电功率原始数据进行归一化处理,得到归一化数据;
34、散点图生成模块,用于采用所述归一化数据生成散点图;
35、分散型噪声点识别模块,用于识别所述散点图,得到分散型噪声点;
36、去噪模块,用于从散点图中去除所述分散型噪声点,得到初步去噪数据;
37、拟合标准功率曲线生成模块,用于生成所述初步去噪数据的拟合标准功率曲线;
38、风速平均标准差计算模块,用于根据所述初步去噪数据计算风速平均标准差;
39、异常值确定模块,用于根据所述风速平均标准差和所述拟合标准功率曲线确定异常值。
40、可选地,所述归一化模块,包括:
41、基准数据获取子模块,用于获取所述风电功率原始数据中的最大功率数据、最小功率数据、最大风速数据和最小风速数据;
42、归一化子模块,用于采用所述最大功率数据、所述最小功率数据、所述最大风速数据和所述最小风速数据对所述风电功率原始数据进行归一化处理,得到归一化数据。
43、可选地,所述分散型噪声点识别模块,包括:
44、已访问点选择子模块,用于随机选择所述散点图中的任意未访问数据点作为已访问点;
45、第一邻域及第一点集确定子模块,用于按照预设半径确定所述已访问点的第一邻域,并获取所述第一邻域的第一点集;
46、数据点数统计子模块,用于统计所述第一邻域内的数据点数;
47、点簇生成子模块,用于当所述数据点数不小于预设最小数据点数阈值时,生成所述已访问点的点簇;
48、新已访问点标记子模块,用于分别将所述第一点集内的每个数据点标记为新已访问点;
49、第二邻域及第二点集确定子模块,用于按照预设半径确定所述新已访问点的第二邻域,并获取所述第二邻域的第二点集;
50、更新子模块,用于当所述第二邻域内的数据点数不小于所述预设最小数据点数阈值时,采用所述第二点集更新所述第一点集;
51、判断子模块,用于判断所述新已访问点是否有归属,若否,将所述新已访问点添加进所述点簇中,若是,将所述新已访问点添加进预设离群点集中;
52、输出子模块,用于当所述第一点集中的数据均完成访问时,返回随机选择所述散点图中的任意未访问数据点作为已访问点的步骤,直至所述散点图中的数据点均完成访问,输出所述离群点中的数据点作为分散型噪声点。
53、可选地,所述拟合标准功率曲线生成模块,包括:
54、功率区间划分子模块,用于将所述初步去噪数据划分为若干个功率区间;
55、密度中点计算子模块,用于计算各所述功率区间的风速均值和功率均值作为密度中点;
56、三次多项式模型建立子模块,用于以风速为自变量、功率为目标变量,建立所述功率区间的三次多项式模型;
57、优化模型生成子模块,用于以功率残差绝对值的总和最小为目标,采用所述密度中点和所述三次多项式模型的待拟合参数生成优化模型;
58、求解子模块,用于通过梯度下降法求解所述优化模型,得到所述待拟合参数的参数值;
59、拟合标准功率曲线生成子模块,用于将所述参数值代入所述三次多项式模型生成拟合标准功率曲线。
60、本发明还提供了一种电子设备,所述设备包括处理器以及存储器:
61、所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
62、所述处理器用于根据所述程序代码中的指令执行如上任一项所述的风电功率曲线异常值识别方法。
63、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行如上任一项所述的风电功率曲线异常值识别方法。
64、从以上技术方案可以看出,本发明具有以下优点:本发明公开了一种风电功率曲线异常值识别方法,并具体公开了:获取风电功率原始数据;对风电功率原始数据进行归一化处理,得到归一化数据;采用归一化数据生成散点图;识别散点图,得到分散型噪声点;从散点图中去除分散型噪声点,得到初步去噪数据;生成初步去噪数据的拟合标准功率曲线;根据初步去噪数据计算风速平均标准差;根据风速平均标准差和拟合标准功率曲线确定异常值。本发明通过对原始风电数据进行归一化处理,消除了风速和功率不同量纲之间的影响,然后对功率曲线中分散型异常值进行滤除,再对经过分散型异常值进行滤除后的数据进行标准功率曲线建模,结合风速平均标准差来对密集型风电功率数据进行异常值识别,从而实现高密度聚集型风电功率数据异常数据的识别,提高风电数据异常识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!