基于Spark-Cassandra框架的DE-DOA改进RRDBNet降水数据降尺度方法
本发明涉及气象数据处理技术,特别涉及基于spark-cassandra框架的de-doa改进rrdbnet降水数据降尺度方法。
背景技术:
1、对气象数据进行降尺度是为了将大尺度的数据转换为更小尺度的数据,即低分辨率转换为高分辨率,以提供更精细的时空分布信息,这有助于满足各种应用需求,提高预测和模拟的准确性,以及适应不同尺度的气象和气候分析。
2、传统的气象降尺度方法主要包括以下三种:动力降尺度、统计降尺度以及动力和统计相结合的降尺度方法,其中动力降尺度是建立在系统的大气热力动力学方程基础之上,基于全球气候模式提供的初始和侧边界条件,通过动力学方程之间的关系,推导得到的具有更高分辨率的气候变化情景。统计降尺度方法通过建立历史阶段气候模式的网格输出变量与站点或区域观测变量之间的统计模型,并将该统计关系应用到未来的气候模拟输出中,从而得到站点或区域尺度的未来气候要素系列,主要是转换函数法、天气分型法和天气发生器法等。动力和统计降尺度相结合的方法,是先基于全球气候模式生成侧边界条件,通过一套热力动力学方程生成区域尺度的气候变量,再使用统计降尺度技术产生站点或区域的气候变化情景,该方法在一定程度上兼顾了动力降尺度和统计降尺度的优点,但实质上只是两种方法的拼接,在气候变化评估的实际应用中存在局限。
3、传统的气象降尺度方法难以有效地捕捉气象数据包含的复杂的时空关系和非线性模式,从而限制了其预测性能,并且伴有计算效率低、过于依赖物理模型、泛化能力有限、特征工程复杂等缺点。越来越多的深度学习方法被应用于气象数据的降尺度处理,但由于降水数据的稀疏性和高度的偏斜性,现有的针对降水数据时空降尺度的深度学习方法较为单一、重建降水数据效果不佳,需要依据经验设置的超参数往往达不到模型最好的效果。
技术实现思路
1、发明目的:针对以上问题,本发明目的是提供一种基于spark-cassandra框架的de-doa改进rrdbnet降水数据降尺度方法。
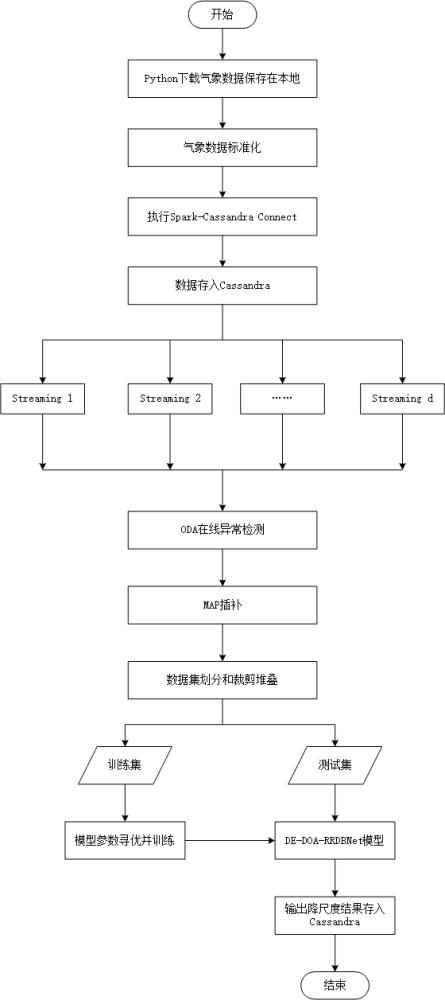
2、技术方案:本发明的基于spark-cassandra框架的de-doa改进rrdbnet降水数据降尺度方法,包括以下步骤:
3、步骤1,获取气象数据,并对气象数据进行预处理;
4、步骤2,利用oda算法检测预处理之后气象数据的异常值,并对异常值进行map插补,将插补后的气象数据划分为训练集和测试集;
5、步骤3,构建rrdbnet模型,使用de-doa算法并利用训练集优化rrdbnet模型中的超参数;
6、步骤4,利用优化后的rrdbnet模型对降水数据进行时间和空间上的降尺度。
7、进一步,步骤1具体包括:
8、在网站上下载气象数据,包括在不同压力水平、不同时间下水平和垂直风分量、位势高度、比湿度和空气温度以及降水数据;
9、利用python中的netcdf库解析下载的气象数据,将气象数据进行标准化,使用spark-cassandra connector工具将标准化后的气象数据存入cassandra数据库。
10、进一步,步骤2中利用oda算法检测预处理之后气象数据的异常值包括以下步骤:
11、步骤201,初始化计数参数 i、 j和迭代次数 r,取值分别为 i=j=1, r=0;
12、步骤202,令 r= r+1,从cassandra数据库中提取气象数据,生成离散化数据流,从离散化数据流中随机选取 n个气象数据构成一个子集其中是包含多个气象特征的数据样本,每个数据样本包括个维度,;
13、步骤203,利用弗里德曼-迪亚康尼斯规则估计区间宽度,统计落入每个区间的数据点数量,利用数据点数量构成对应区间的直方图;其中 l表示直方图的索引, k表示直方图的个数;
14、步骤204,从全零向量开始,随机选择个特征,根据随机生成非零项构建投影向量;
15、步骤205,令 i=1,判断 j和 n的相对大小,若,跳转至步骤206;若 j> n,判断迭代次数 r是否达到最大值,若未达到则跳转至步骤202,若达到则跳转至步骤207;
16、步骤206,令 i= i+1,计算投影值,并用投影值更新直方图,判断 i和 k的相对大小,若,则 j= j+1,跳转至步骤205;若,重复执行步骤206;
17、步骤207,计算异常得分,将得分大于最高分95%的值标记为异常值,并结束迭代;其中异常得分的计算公式如下:
18、,
19、其中,表示投影的联合概率,假设( a)是投影向量和上概率分布是独立的,;公式的含义是在假设( a)成立的情况下,。
20、进一步,步骤2中对异常值进行map插补,用插补估计值替换异常值;插补估计值的计算表达式为:
21、,
22、其中,是map插补估计值, m是在查询实例中异常缺失特征值的集合,表示由 m索引的特征,是由互补集合索引的特征,是对特征进行索引的集合。
23、进一步,步骤3中构建rrdbnet模型包括:构建个空间特征提取网络和1个时间帧插值网络,其中时间帧插值网络包括个结构相同的门控网络;
24、将个不同时间帧的气象数据点分别输入至空间特征提取网络,将空间特征提取网络的所有输出特征,记为集合;其中,;将个不同时间帧的气象数据点进行通道叠加,作为输入项输入至个门控网络;
25、将门控网络的输出项乘上空间特征提取网络的输出特征,得到中间帧的输出特征,记为集合;其中;
26、将集合和集合经通道顺序叠加后的输入至卷积层、亚像素卷积、卷积层和卷积层后,输出高分辨率降水数据。
27、进一步,构建空间特征提取网络,包括:构建浅层特征提取网络,将训练集气象数据裁剪后堆叠在一起记为输入矩阵,输入至浅层特征提取网络;其中浅层特征提取网络包括依次设置的卷积层和激活函数层,激活函数层的激活函数为:
28、,
29、其中,是激活前特征矩阵中每一元素的数值,是激活后的特征矩阵中每一元素的数值;
30、构建rrdb网络,包括三个残差密集块和一个残差边缘,各残差密集块和残差边缘之间残差连接,将浅层特征提取网络的输出特征依次输入至三个残差密集块和一个残差边缘中;其中残差密集块包括4个多尺度卷积层和5个激活函数prelu层,在每两个prelu层之间设置1个多尺度卷积层,prelu激活函数为:
31、,
32、其中,是激活函数在训练过程中自适应地从数据中学习的参数;
33、将残差边缘的输出特征再输入至两个连续的卷积层和激活函数层,最后通过全连接层输出气象数据的空间特征参数 ρ、 α和;其中,每个输出特征层网格点的输出表示如下:
34、,
35、,
36、,
37、其中,,,分别表示目标网格点 i在时间 t的三个输出值。
38、进一步,rrdbnet模型的损失函数为:
39、,
40、其中,表示在时间输入到rrdbnet模型的预测因子集合,是在时间在网格点处的实际降水;表示伯努利-伽马分布的概率密度函数,是目标网格点的总数, n是批处理时间步长;伯努利-伽马分布的概率密度函数为:
41、,
42、其中,表示伽马函数。
43、进一步,步骤3中使用de-doa算法并利用训练集优化rrdbnet模型中的超参数包括:
44、使用de-doa优化算法对rrdbnet中的残差密集块的个数、残差操作的加权系数、批次大小和学习率进行寻优。
45、进一步,步骤3中使用de-doa算法并利用训练集优化rrdbnet模型中的超参数包括如下步骤:
46、步骤301,初始化寻优目标,包括:计算佳点值,其中 ,,表示第 i个个体, s是种群所在的空间维度, m为种群数量;构造种群数量 m的佳点集,记为,;将映射到种群所在的可行域上,,其中为当前寻优个体,和分别表示的上界和下界,为迭代次数;
47、步骤302,计算适应度函数值,计算公式如下:
48、,
49、其中,是训练集中的样本数量,是第 i个样本的真实值,是rrdbnet模型输出的预测值;
50、步骤303,定义种群的三种狩猎策略:
51、策略一为群体攻击策略,计算公式如下:
52、,
53、其中,表示寻优目标的新位置,是在间的逆序中生成的随机整数, sizepop是寻优个体的规模;为进行群体攻击寻优个体的子集,,为随机生成的寻优个体;是上一代最佳寻优个体;是在[-2,2]内均匀生成的随机数,表示比例因子,用以改变野狗轨迹的大小;
54、策略二为迫害策略,计算公式如下:
55、,
56、其中,是在区间内均匀产生的随机数,是在1到最大野狗种群大小的间隔内生成的随机数;是随机选择的第个野狗种群,;
57、策略三为食腐策略,计算公式如下:
58、,
59、其中,是随机生成的二进制数,;
60、步骤304,按照如下规则选择种群中个体执行的狩猎策略:
61、当时执行群体攻击策略;
62、当时执行迫害策略;
63、当时执行食腐策略;
64、其中,和是[0,1]之间均匀生成的随机数,和为野狗种群执行相应策略的概率值,,为野狗优化算法中的迭代次数;
65、步骤305,计算野狗的存活率,计算表达式为:
66、,
67、其中,表示第 i个野狗的存活率,表示第i个野狗种群当前的适应度函数值,和分别表示适应度函数的最大值和最小值;
68、步骤306,根据野狗的存活率决定接下来的策略,不同存活率对应的策略公式如下:
69、,
70、,
71、其中,是生成的变异向量,是[1, np]区间内的随机数;为自适应缩放因子, cr为随机范围的交叉算子,, np为变异的种群规模,计算公式分别如下:
72、,
73、其中,是(0,1)之间的随机数,为解空间的维数;
74、步骤307,对变异后的个体和经过生存策略的个体进行交叉,交叉后寻优目标的新位置计算表达为:
75、,
76、步骤308,采用贪婪选择策略,选择较优的个体作为下一代的个体进入迭代,迭代后寻优目标的新位置计算表达为:
77、,
78、步骤309,重复步骤302至步骤308,直至达到最大迭代次数,将de-doa算法寻优结果即寻找到的最优超参数组合应用到rrdbnet模型。
79、有益效果:本发明与现有技术相比,其显著优点是:
80、本发明中使用spark-cassandra大数据框架处理气象数据,处理数据效率更高;本发明中使用最大后验概率map对数据异常值和缺失值进行插补,避免了忽略缺失数据或者简单地使用均值或中位数进行估计的不足;本发明在时间帧插值网络中采用独特巧妙简单的门控网络实现时间帧插值,代替了常用的lstm网络,能够获得更好的效果;为了更好的实现降水数据的降尺度处理,本发明中利用伯努利-伽马分布设计损失函数,提高rrdbnet模型的收敛速度;本发明中rrdbnet模型的超参数有很多,利用de-doa优化算法自动的选择rrdbnet模型的最优超参数组合节省资源和时间,找到更优的超参数组合;本发明中提出的doa算法基于野狗的狩猎策略,解决了由于动物优化算法容易陷入局部最优解的问题,采取了差分优化算法的思想能够有效的使doa算法跳出局部最优;此外,本发明还在de-doa算法中改变了种群初始化方法,以提高算法在解空间上的遍历能力;针对超参数寻优问题,优化算法中引入自适应参数,以提高算法的鲁棒性,加快算法的收敛速度。
- 还没有人留言评论。精彩留言会获得点赞!