一种基于NLP的日志聚类方法和装置与流程
本申请实施例涉及但不限于自然语言处理,特别是涉及一种基于nlp的日志聚类方法和装置。
背景技术:
1、自然语言处理技术(natural language processing,nlp)是计算机科学与人工智能领域的一项重要技术,它主要是通过计算机对人类语言进行理解、分析、处理和生成,从而实现与人类语言的交互和应用。随着现阶段企业软件系统变得日益庞大和复杂,例如某个服务在短时间内产生了大量报警,同时产生了多类报错日志,而某一类的关键报错日志可能条数较少,则很容易被其他报错日志淹没。对于系统产生的海量异构日志,如何进行分类处理,以便快速的掌握日志全貌,用于后续的问题定位与异常检测,这已成为亟需解决的技术问题。
技术实现思路
1、针对现有技术中存在的上述问题,本发明提出了一种基于nlp的日志聚类方法和装置。本申请所采用的技术方案如下:
2、一种基于nlp的日志聚类方法,该方法包括:
3、步骤1、获取原始日志数据,并从数据库中获取历史的自定义模式元数据,判断是否在原始日志数据中匹配成功自定义模式元数据的表达式,若是,则跳转并执行步骤2;若否,则跳转并执行步骤3;
4、步骤2、为匹配成功的自定义模式元数据分配唯一标识,并使用jflex算法对相应的原始日志数据进行变量提取,根据提取的变量将所述相应的原始日志数据拆解成多个分词token并分别进行打标;
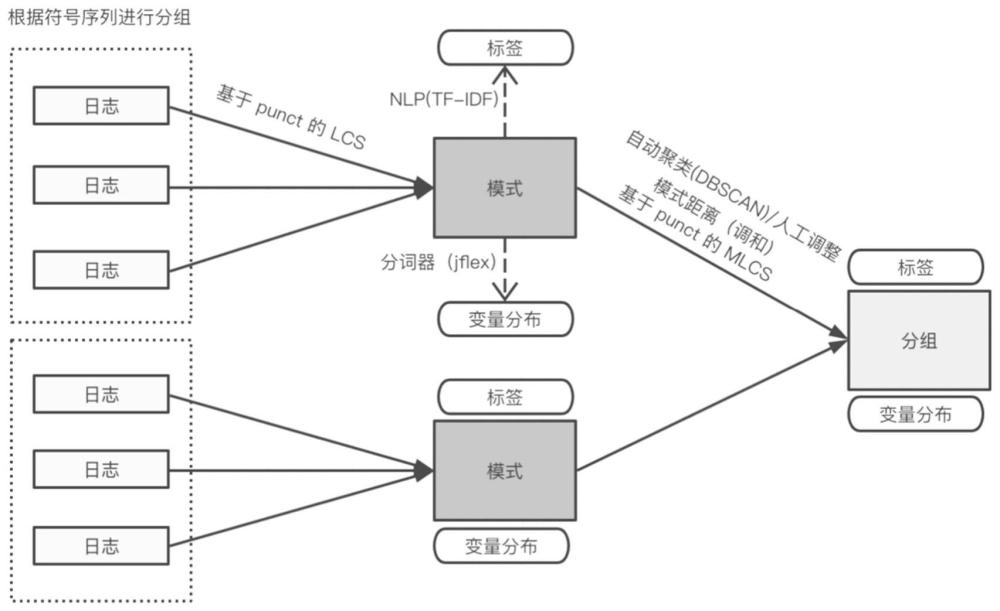
5、步骤3、对原始日志数据进行punctuation算法处理,根据原始日志数据中的标点符号类型、数量、顺序,生成日志的模式表达式;在历史模式表达式中对生成的所述日志的模式表达式进行匹配,若未匹配,则返回并执行步骤2;若已匹配,根据lcs算法对模式表达式进行分组处理,以获得日志聚类结果。
6、进一步的,在上述步骤2中,通过对拆解成的多个分词token分别进行打标,以表明分词token的类型,该类型包括时间类型、数字类型以及邮件类型。
7、进一步的,在步骤3中,若未匹配,则将未匹配的模式表达式以及相应的分词token持久化到数据库中,成为历史模式表达式的一部分。
8、进一步的,在步骤3中,根据lcs算法对模式表达式进行分组处理,具体处理包括:将多条日志的分词token和已匹配的模式表达式进行相互对比,若日志之间token的相似度大于等于80%,模式表达式中最长公共字串的相似度大于等于80%,则聚合成模式分组,并将模式分组以及模式表达式和模式分组的对应关系同步到数据库中,单个模式分组对应一个或多个模式表达式;如果新接入的日志对应的模式表达式属于模式分组则提取分组变量,并同时更新模式分组表达式所在的数据库中的数据;如果不属于,则提取模式变量并更新历史模式表达式。
9、一种基于nlp的日志聚类方法,该方法包括:
10、步骤1、获取原始日志数据,并基于标点符号类型、数量、顺序,生成日志的模式,保存这些模式的元数据到数据库进行持久化存储;
11、步骤2、基于punctuation和jflex对原始日志数据进行分词处理,将带有一组正则表达式和相应操作的规范输入词法分析器,根据输入与规范文件中的正则表达式进行匹配,并在正则表达式匹配时将匹配到的文本进行文本类型的打标处理,并将原始日志数据拆解成多个分词token;
12、步骤3、对拆解成的所述多个分词token进行变量提取,把模式表达式中相同位置出现的不同字符串提取成变量,通过lcs对最长公共字串进行迭代计算,合并模式表达式并形成模式分组;
13、步骤4、在模式表达式的基础上,采用dbscan算法进行二次聚类,智能模式分组表达式;
14、步骤5、采用tf-idf算法进行关键词提取,根据模式中匹配的日志原文,利用自然语言处理的算法,为分组之后的模式进行名称标识。
15、进一步的,在上述步骤2中,通过所述打标处理以确定文本类型,所述文本类型包括时间类型、数字类型、以及邮件类型。
16、进一步的,在步骤3中,通过lcs对最长公共字串进行迭代计算,合并模式并形成分组,具体包括:
17、步骤301、在游离模式下匹配已有分组,并根据匹配结果更新分组表达式;
18、步骤302、确定采样模式,并计算距离矩阵;根据聚类模式生成新分组,并生成分组表达式;使用新分组匹配剩下模式,更新分组表达式,并聚类新分组;
19、步骤303、根据所述聚类新分组计算距离矩阵,聚类分组生成新分组,生成分组表达式,并匹配已有分组,更新分组表达式,返回更新后的分组。
20、进一步的,在上述步骤5中,所采用的词频-逆文档频次算法tf-idf的算法公式如下:
21、
22、tfij表示词i在文本j中出现的频率,idfi表示词i的逆文本频率,nij表示词i在j文本中出现的次数;nkj表示在j文本中的总词数,di表示包含该词i的文档数量。
23、一种基于nlp的日志聚类装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种方法。
24、一种基于nlp的日志聚类装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述另一种方法。
25、通过本申请实施例,可以获得如下技术效果:本申请将punctuation、dbscan、lcs、jflex等多种算法相互结合进行数据处理加工日志文本得到日志聚类结果,将相似度高的日志聚集在一起,有利于发现日志中的规律和共性问题,方便从海量日志中排查问题,定位故障;海量日志仅需少量日志模式表示,提取共性部分保留独立信息,减少存储成本。
26、本申请的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本申请而了解。本申请的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
技术特征:
1.一种基于nlp的日志聚类方法,其特征在于,该方法包括:
2.根据权利要求1所述的方法,其特征在于,在上述步骤2中,通过对拆解成的多个分词token分别进行打标,以表明分词token的类型,该类型包括时间类型、数字类型以及邮件类型。
3.根据权利要求1所述的方法,其特征在于,在步骤3中,若未匹配,则将未匹配的模式表达式以及相应的分词token持久化到数据库中,成为历史模式表达式的一部分。
4.根据权利要求1所述的方法,其特征在于,在步骤3中,根据lcs算法对模式表达式进行分组处理,具体处理包括:将多条日志的分词token和已匹配的模式表达式进行相互对比,若日志之间token的相似度大于等于80%,模式表达式中最长公共字串的相似度大于等于80%,则聚合成模式分组,并将模式分组以及模式表达式和模式分组的对应关系同步到数据库中,单个模式分组对应一个或多个模式表达式;如果新接入的日志对应的模式表达式属于模式分组则提取分组变量,并同时更新模式分组表达式所在的数据库中的数据;如果不属于,则提取模式变量并更新历史模式表达式。
5.一种基于nlp的日志聚类方法,其特征在于,该方法包括:
6.根据权利要求5所述的方法,其特征在于,在上述步骤2中,通过所述打标处理以确定文本类型,所述文本类型包括时间类型、数字类型、以及邮件类型。
7.根据权利要求5所述的方法,其特征在于,在步骤3中,通过lcs对最长公共字串进行迭代计算,合并模式并形成分组,具体包括:
8.根据权利要求5所述的方法,其特征在于,在上述步骤5中,所采用的词频-逆文档频次算法tf-idf的算法公式如下:
9.一种基于nlp的日志聚类装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至4中任意一项所述的方法。
10.一种基于nlp的日志聚类装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求5至8中任意一项所述的方法。
技术总结
本申请提供了一种基于NLP的日志聚类方法和装置,通过将Punctuation、DBSCAN、LCS、JFLEX多种算法相互结合进行数据处理加工日志文本得到日志聚类结果,将相似度高的日志聚集在一起,提取共同的日志PATTERN,有利于发现日志中的规律和共性问题,方便从海量日志中排查问题、定位故障,仅需少量日志模式表示,提取共性部分保留独立信息,减少存储成本。
技术研发人员:岳孟言
受保护的技术使用者:中电信数智科技有限公司
技术研发日:
技术公布日:2024/4/24
- 还没有人留言评论。精彩留言会获得点赞!