一种基于视觉语言大模型的图像问答数据获取方法
本发明属于人工智能,具体涉及一种基于视觉语言大模型的图像问答数据获取方法。
背景技术:
1、视觉语言大模型(large vision-language models,lvlms)在多模态视觉语言领域已经取得了巨大进展,核心思路是将视觉编码器集成到大语言模型(large languagemodels,llms)中,利用llms中卓越的语言理解能力,lvlms能够执行视觉对话、视觉定位、推理分割、图像生成和任意模态对话等任务;实现这些任务的核心技术之一是视觉指令微调,视觉指令微调主要通过创建指令跟随的问答样本来微调lvlms。
2、当前的研究中主要突出多模态视觉语言指令跟随数据的重要性,然而,人工标注大规模、高质量的多模态指令跟随数据面临着极大的挑战,利用类似gpt-4的机器生成指令跟随的样本需要较大的花费,同时,gpt-4生成指令数据依赖于图像的描述,无法创建描述中没有包含的问答数据。
3、当前已有研究者利用lvlms生成大规模、高质量的多模态指令跟随数据,这些方法主要集中在生成单轮视觉对话数据集方面,限制了生成指令数据的指令和多样性,此外,可利用的lvlms并不像llms一样具备较为完善的功能,已有的lvlms方法通常会生成不恰当的回答或者生成错误的信息,包括幻想。为了处理上述问题,视觉指令生成和修正方法vigc(visual instruction generation and correction)建立了视觉指令修正模块来重新生成回复,但是由于需要运行大语言模型两次,因此,也引入了计算负担。
4、综上所述,当前针对视觉语言大模型进行微调的大多数方法严重依赖于指令数据,大部分指令数据的构建严重依赖于图像的描述,而图像的描述限制了指令的内容范围。在基于图像的指令生成方面,现有模型存在性能较低、效率不高的问题。
技术实现思路
1、本发明的目的在于提供一种性能提升、效率增加、准确性增强的基于视觉语言大模型的图像问答数据获取方法。
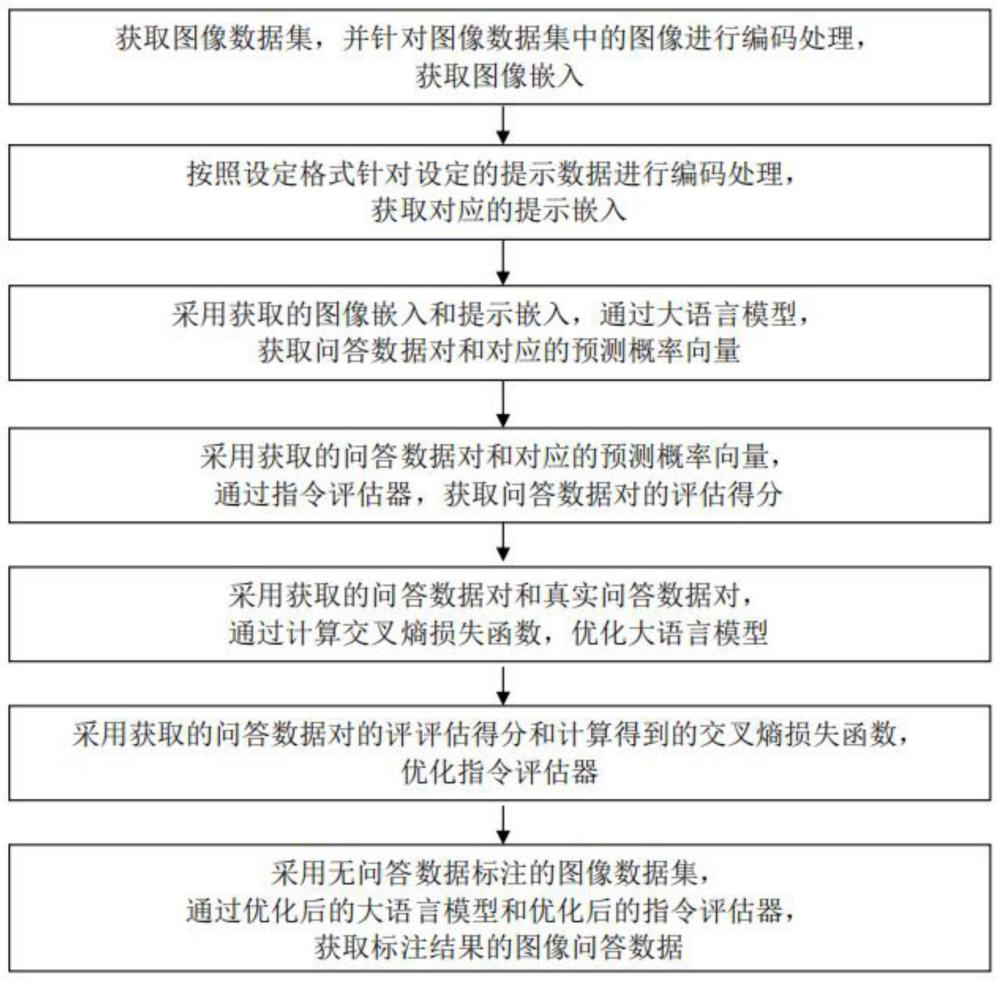
2、本发明提供的这种基于视觉语言大模型的图像问答数据获取方法,包括如下步骤:
3、s1.获取图像数据集,并针对图像数据集中的图像进行编码处理,获取图像嵌入;
4、s2.按照设定格式针对设定的提示数据进行编码处理,获取对应的提示嵌入;
5、s3.采用步骤s1获取的图像嵌入和步骤s2获取的提示嵌入,通过大语言模型,获取问答数据对和对应的预测概率向量;
6、s4.采用步骤s3获取的问答数据对和对应的预测概率向量,通过指令评估器,获取问答数据对的评估得分;
7、s5.采用步骤s3获取的问答数据对和真实问答数据对,通过计算交叉熵损失函数,优化大语言模型;
8、s6.采用步骤s4获取的问答数据对的评估得分和步骤s5计算得到的交叉熵损失函数,优化指令评估器;
9、s7.采用无问答数据标注的图像数据集,通过步骤s5中优化后的大语言模型和步骤s6中优化后的指令评估器,获取标注结果的图像问答数据;
10、步骤s1所述的获取图像数据集,并针对图像数据集中的图像进行编码处理,获取图像嵌入,具体包括:
11、图像数据集包括原始图像i和视觉指令数据t;
12、采用图像编码器模型,针对原始图像i进行编码处理,获取对应的图像嵌入xi;
13、视觉指令数据t为真实的问答数据对,用于计算交叉熵损失函数;
14、步骤s2所述的按照设定格式针对设定的提示数据进行编码处理,获取对应的提示嵌入,具体包括:
15、采用如下所示的设定提示数据:
16、“generate multiple question-answer pairs based on theimage.requirement:the answer to each question must be found within the image,and the format is as follows:question:…[\n]answer:…[\n]”;
17、按照设定格式针对设定的提示数据进行编码处理,获取提示嵌入xprompt;
18、步骤s3所述的采用步骤s1获取的图像嵌入和步骤s2获取的提示嵌入,通过大语言模型,获取问答数据对和对应的预测概率向量,具体包括:
19、针对图像嵌入xi和提示嵌入xprompt进行拼接处理,通过大语言模型φl进行大语言分析处理,获取预测问答数据对和对应的预测概率向量;
20、采用下述公式表示输出的每个问答数据对中提示对应的预测概率向量v:
21、[xc,v]=φl([xi,xprompt])
22、其中,xc表示生成的问题和对应问题的答案的对话数据;
23、步骤s4所述的采用步骤s3获取的问答数据对和对应的预测概率向量,通过指令评估器,获取问答数据对的评估得分,具体包括:
24、选择预测概率向量v,通过指令评估器ψ,获取问答数据对对应的评估得分,采用下述公式表示评估处理过程:
25、s=ψ(v)
26、其中,s表示指令评估器的输出为问答数据对的评估得分;
27、指令评估器ψ为一个全连接的线性层,直接添加在大语言模型φl的输出层后,同时大语言模型φl的输出结果作为指令评估器ψ的输入;
28、全连接的线性层为一层的全连接网络(fully connected network);
29、步骤s5所述的采用步骤s3获取的问答数据对和真实问答数据对,通过计算交叉熵损失函数,优化大语言模型,具体包括:
30、采用步骤s3获取的预测问答数据对和真实的问答数据对计算交叉熵损失函数;
31、其中,真实的问答数据对为步骤s1获取的视觉指令数据t;
32、在模型训练过程中,根据输出问答数据与真实的问答数据计算损失,并根据损失结果对模型进行优化;
33、采用下述公式表示生成目标对话数据xc的概率:
34、
35、其中,p(xc|xi,xprompt)表示大语言模型生成的对话数据对应的所有提示的概率乘积;pθ(·)表示大语言模型生成的其中一个提示的概率;xi表示模型执行过程中实时预测的提示;l表示输出问答对话内容的长度;θ表示可训练参数;xc,<i表示xi之前所有的对话提示;
36、采用生成目标对话数据xc的概率p(xc|xi,xprompt),确定预测数据的标签lm;同时,生成目标对话数据xc的概率p(xc|xi,xprompt)也作为指令评估器的输入;
37、通过计算大语言模型预测的对话数据提示的标签与真实对话数据提示的标签ln之间的交叉熵损失,完成模型的优化处理;
38、采用下述公式计算交叉熵损失:
39、
40、其中,lmt-vcg表示交叉熵损失;表示大语言模型预测的第i个token对应的真实标签的概率;表示第i个token对应的真实标签;l表示模型预测结果和真实结果之间的交叉熵损失值;
41、在大语言模型的训练过程中,通过计算每个预测结果对应的交叉熵损失lmt-vcg,和反向传播,更新大语言模型φl的参数,直至满足设定条件,获取最优模型;
42、步骤s6所述的采用步骤s4获取的问答数据对的评估得分和步骤s5计算得到的交叉熵损失函数,优化指令评估器,具体包括:
43、采用下述公式表示指令评估器的损失:
44、lvise=l1(tanh(lmt-vcg),1-s)
45、其中,lvise表示指令评估器的损失值;l1表示绝对值损失函数,计算公式如下所示:
46、l1=|lmt-vcg-(1-s)|
47、tanh(lmt-vcg)表示输出的每一对问答数据对在使用tanh(·)函数激活后的自回归损失值;
48、基于计算得到的lvise实现反向传播处理;
49、计算lvise对于评估得分s的导数值,并通过计算的导数值更新评估器的参数,进而降低损失lvise的值;
50、步骤s7所述的采用无问答数据标注的图像数据集,通过步骤s5中优化后的大语言模型和步骤s6中优化后的指令评估器,获取标注结果的图像问答数据,具体包括:
51、采用步骤s5中优化后的大语言模型和步骤s6中优化后的指令评估器,构建图像问答数据获取模型;
52、无问答数据标注的图像数据集输入到步骤s5中优化后的大语言模型中,同时输出对话数据和对应的概率向量;输出的概率向量输入到步骤s6中优化后的指令评估器中,同时输出对话数据的评分;
53、通过构建的图像问答数据获取模型,采用无问答数据标注的图像数据集,完成图像问答数据获取处理,获取标注结果的图像问答数据;
54、标注结果的图像问答数据包括优化后的大语言模型输出的对话数据和优化后的指令评估器输出的评分;
55、本发明方法还包括如下步骤:
56、1)获取开源llava多模态大语言模型,并针对开源llava多模态大语言模型进行微调处理;
57、2)针对步骤1)中微调处理后的开源llava多模态大语言模型进行优化处理,获取最终的llava多模态大语言模型;
58、3)采用步骤2)中获取的最终的llava多模态大语言模型,针对图像进行问答测试,完成图像问答数据获取模型有效性的验证;
59、步骤1)所述的获取开源llava多模态大语言模型,并针对开源llava多模态大语言模型进行微调处理,具体包括:
60、微调包括开源llava多模态大语言模型中图像编码器和大语言模型之间的全连接层、开源llava多模态大语言模型中的大语言模型;
61、微调参数包括全连接层和大语言模型中的全部参数;
62、开源llava多模态大语言模型中图像编码器用于对图像进行编码处理;
63、图像编码器和大语言模型通过一层全连接层网络连接;
64、在微调的过程中,开源llava多模态大语言模型的输入数据为图像对应的提示编码和问题对应的提示编码,输出数据为对应问题的回答;
65、步骤2)所述的针对步骤1)中微调处理后的开源llava多模态大语言模型进行优化处理,获取最终的llava多模态大语言模型,具体包括:
66、优化包括开源llava多模态大语言模型中图像编码器和大语言模型之间的全连接层、开源llava多模态大语言模型中的大语言模型;
67、优化参数包括全连接层和大语言模型中的全部参数;
68、采用步骤1)中的输出数据和步骤s7中获取的标注结果的图像问答数据,计算损失函数,根据损失函数优化开源llava多模态大语言模型;
69、损失函数的计算公式如下所示:
70、
71、其中,lca-vit表示置信度得分加权的损失值;n表示多轮对话的对话数量;si表示每个对话的置信度得分,si∈s;li表示llm的输出与监督答案之前的交叉熵损失,计算公式如下所示:
72、
73、其中,表示大语言模型预测的第j个提示对应的真实标签的概率;表示第j个提示对应的真实标签;
74、基于计算得到的lca-vit实现反向传播处理;计算lca-vit对于评估得分ym的导数值,并通过计算的导数值更新开源llava多模态大语言模型的参数,进而降低损失lca-vit的值;
75、步骤3)所述的采用步骤2)中获取的最终的llava多模态大语言模型,针对图像进行问答测试,完成图像问答数据获取模型有效性的验证,具体包括:
76、通过最终的llava多模态大语言模型,针对图像完成问答测试,验证通过图像问答数据获取模型获取的标注结果的图像问答数据的有效性;
77、如果使用获取的标注结果的图像问答数据,通过最终的llava多模态大语言模型,能够正确回答实际对话中的问题,表示通过图像问答数据获取模型获取的标注结果的图像问答数据有效;如果使用获取的标注结果的图像问答数据,通过最终的llava多模态大语言模型,不能够正确回答实际对话中的问题,表示通过图像问答数据获取模型获取的标注结果的图像问答数据无效;
78、本发明提供的这种多轮视觉对话和自评估大模型方法,通过结合图像编码器和大语言模型,能够实现以图像作为输入,输出基于图像内容的多轮对话数据,同时输出的数据进一步用于微调多模态问答大模型,从而实验多模态问答任务;本发明方法的性能提升、效率增加、准确性增强。
- 还没有人留言评论。精彩留言会获得点赞!