一种基于大模型的安全编码规范多标融合方法及系统与流程
本发明属于人工智能,尤其涉及一种基于大模型的安全编码规范多标融合方法及系统。
背景技术:
1、在软件开发过程中,遵守众多法律法规、标准规范是一项重要的任务。安全编码需要符合许多政策法规、标准制度的要求,并且需要理解和融合众多的标准规范,以指导安全编码的开发。
2、传统的融合方法主要靠人工将每个标准编码规范逐条映射到对应的框架,如cobit、iso27001、阿里编码规范等。然而,这种传统融合方法存在以下问题:由于人工理解的不同,对编码需求的归类会产生差异;由于人工操作的局限性,对条款的映射可能会出现错误操作;由于条款众多,融合过程中难以整体把控条款的相关性和相斥性;条款和编码的映射关系缺乏对照和参考,使得映射过程不够准确和可靠。针对这些问题,需要采用一种更加高效、准确的方法来融合和映射标准规范与编码之间的关系。
技术实现思路
1、本发明提供一种基于大模型的安全编码规范多标融合方法及系统,旨在解决上述背景技术提到的问题。
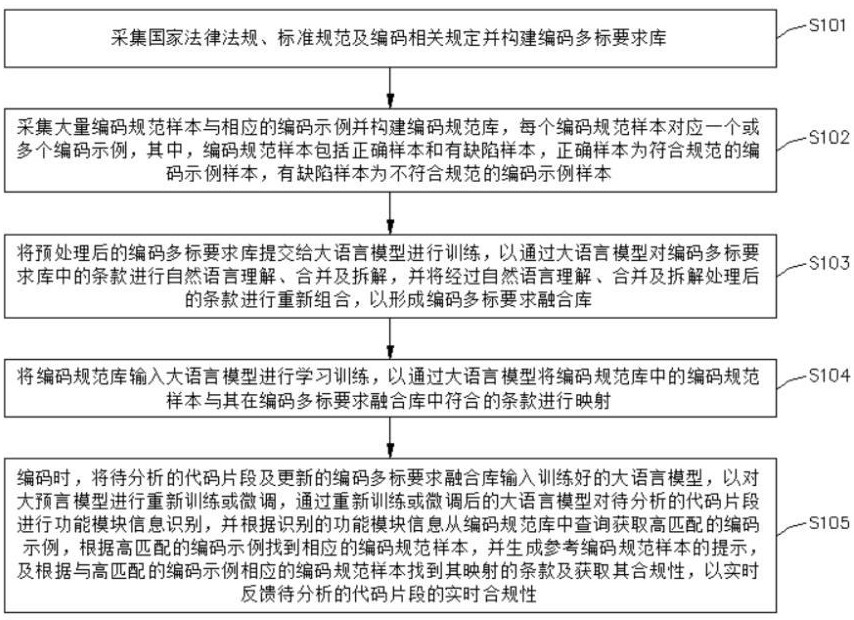
2、本发明是这样实现的,提供一种基于大模型的安全编码规范多标融合方法,步骤包括:
3、采集国家法律法规、标准规范及编码相关规定并构建编码多标要求库;
4、采集大量编码规范样本与相应的编码示例并构建编码规范库,每个编码规范样本对应一个或多个编码示例,其中,编码规范样本包括正确样本和有缺陷样本,正确样本为符合规范的编码示例样本,有缺陷样本为不符合规范的编码示例样本;
5、将预处理后的编码多标要求库提交给大语言模型进行训练,以通过大语言模型对编码多标要求库中的条款进行自然语言理解、合并及拆解,并将经过自然语言理解、合并及拆解处理后的条款进行重新组合,以形成编码多标要求融合库;
6、将编码规范库输入大语言模型进行学习训练,以通过大语言模型将编码规范库中的编码规范样本与其在编码多标要求融合库中符合的条款进行映射;
7、编码时,将待分析的代码片段及更新的编码多标要求融合库输入训练好的大语言模型,以对大预言模型进行重新训练或微调,通过重新训练或微调后的大语言模型对待分析的代码片段进行功能模块信息识别,并根据识别的功能模块信息从编码规范库中查询获取高匹配的编码示例,根据高匹配的编码示例找到相应的编码规范样本,并生成参考编码规范样本的提示,及根据与高匹配的编码示例相应的编码规范样本找到其映射的条款及获取其合规性,以实时反馈待分析的代码片段的实时合规性。
8、更进一步的,所述采集大量编码规范样本与相应的编码示例并构建编码规范库的步骤后还包括:
9、确定优化编码规范库的目标,包括提高代码质量、减少漏洞和提高可维护性;
10、确定编码规范库中编码规范样本的变化范围和组合方式,并构建一个针对编码规范库的初始的搜索空间,编码规范样本的变化范围包括编码风格、设计模式和编码规则,组合方式包括将不同的编码风格、设计模式和编码规则进行组合的方式;
11、根据目标和约束条件,构建启发式函数,并通过启发式函数评估每个编码规范样本的优劣,评估公式为:f(x)=w1* g1(x)+w2*g2(x)+...+wn*gn(x),其中,f(x)为启发式函数对编码规范样本x优劣的评估结果值,g1(x)、g2(x)、...、gn(x) 是各个评估指标的函数,用于衡量编码规范样本 x 在不同方面的表现,w1、w2、...、wn 是各个评估指标的权重,用于调整不同评估指标在评估中的重要性,评估指标包括代码质量、适应度、复杂度、可读性和安全性;
12、根据启发式搜索算法的策略及启发式函数的评估结果的当前最优解的情况,生成新的编码规范样本;
13、使用启发式函数对新的编码规范样本的优劣进行评估,并将新的编码规范样本的评估结果与当前最优解进行比较;
14、若新的编码规范样本的评估结果优于当前最优解,则将新的编码规范样本的评估结果加入到最优解集合中,及将相应的新的编码规范样本加入到最优编码规范集合中,最优解集合中的值与最优编码规范集合的编码规范样本一一映射,并随着搜索的进行不断更新和优化,当满足终止条件时,停止搜索并输出最终的最优解集合和最终的最优编码规范集合;
15、将最终的最优编码规范集合整理成优化后的编码规范库。
16、更进一步的,所述根据启发式搜索算法的策略及启发式函数的评估结果的当前最优解的情况,生成新的编码规范样本的步骤包括:
17、根据启发式函数的评估结果,筛选出两个或多个编码规范样本作为父代样本;
18、对筛选的父代样本进行交叉操作,生成新的子代样本,具体为:选择合适的交叉方法并确定交叉点的位置,将父代样本的基因进行组合,以生成具有新颖性和多样性的子代样本,交叉操作包括单点交叉、多点交叉或均匀交叉;
19、对生成的子代样本进行变异操作,引入新的基因变异,以生成新的编码规范样本,确保新的编码规范样本满足约束条件,若不满足约束条件,则进行调整或重新生成。
20、更进一步的,所述将待分析的代码片段及更新的编码多标要求融合库输入训练好的大语言模型的步骤后还包括:
21、大语言模型根据输入进行深度学习,并尝试从中提取和生成新的、未被考虑过的编码规范样本,设为创新性编码规范样本,其中,创新性编码规范样本满足国家法律法规、标准规范及编码相关规定,及为编码实践提供新的思路和方法;
22、将生成的创新性编码规范样本输出,以供开发者参考使用。
23、更进一步的,所述大语言模型根据输入进行深度学习,并尝试从中提取和生成新的、未被考虑过的编码规范样本的步骤包括:
24、将待分析的代码片段和编码多标要求融合库进行预处理,包括分词、去除停用词、标准化等操作,以便于大语言模型更好地理解和处理输入数据。
25、使用预处理后的输入数据对大语言模型进行训练,训练过程中,大语言模型学习到输入数据的内在结构和语义信息,并尝试从中提取有用的特征和模式;
26、在大语言模型的训练过程中,通过大语言模型自动学习到输入数据中的特征,用于后续的编码规范样本生成,特征包括语法、语义和上下文信息;
27、基于学习到的特征,使用变分自编码器技术协助大语言模型来生成新的、未被考虑过的编码规范样本;
28、对生成的编码规范样本进行评估和筛选,以确保其满足国家法律法规、标准规范及编码相关规定,并为编码实践提供新的思路和方法;
29、根据评估结果,对大语言模型进行反馈和优化,以进一步提高其生成的创新性编码规范样本的质量和多样性。
30、更进一步的,所述基于学习到的特征,使用变分自编码器技术协助大语言模型来生成新的、未被考虑过的编码规范样本的步骤包括:
31、定义编码器和解码器,其中,编码器用于接收一个真实样本作为输入及输出真实样本的潜在向量,解码器用于接收真实样本的潜在向量作为输入及输出一个与真实样本相似的重构样本;
32、训练过程中,使用真实样本初始化编码器和解码器,在每次迭代中,编码器学习将真实样本映射到潜在空间,解码器学习从潜在空间重构真实样本;
33、当带有变分自编码器技术的大语言模型训练完成后,通过编码器将学习到的特征映射到潜在空间并输出潜在向量,再通过解码器从潜在空间中采样潜在向量,并根据潜在向量生成新的、未被考虑过的编码规范样本。
34、更进一步的,所述将预处理后的编码多标要求库提交给大语言模型进行训练,以通过大语言模型对编码多标要求库中的条款进行自然语言理解、合并及拆解,并将经过自然语言理解、合并及拆解处理后的条款进行重新组合,以形成编码多标要求融合库的步骤包括:
35、对编码多标要求库中的条款进行格式化处理,包括分词、去除停用词和标准化,以适应大语言模型的需求;
36、制定合并及拆解规则,以定义如何进行合并和拆解;
37、将编码多标要求库提交给大语言模型进行学习训练;
38、利用大语言模型对编码多标要求库进行自然语言理解,以理解编码多标要求库中的每个条款的语义和含义;
39、根据预定义的合并及拆解规则,对自然语言理解的结果进行合并或拆解处理;
40、将合并或拆解处理后的要求条款进行重新组合,以形成编码多标要求融合库;
41、对融合库进行验证,以确保合并或拆解的处理过程中没有引入错误或失去重要信息。
42、更进一步的,所述对大预言模型进行重新训练或微调的步骤包括:
43、编码时,若编码多标要求库更新了条款,则对更新的编码多标要求库进行格式化处理以得到新数据集;
44、根据新数据集与原数据集之间的差异程度对大语言模型进行调整,其中,原数据集为经过格式化处理的更新前的编码多标要求库;
45、若新数据集与原数据集之间的差异度超过预设差异阈值,则对大语言模型重新训练;
46、若新数据集与原数据集之间的差异度不超过预设差异阈值,则对大语言模型进行微调,微调过程中,对大语言模型的预训练层进行冻结,并对其顶层进行更新,及对训练学习率进行调小,多次进行迭代训练,每次迭代只更新一小部分参数,并使用梯度下降的优化算法来最小化损失函数。
47、更进一步的,所述根据识别的功能模块信息从编码规范库中查询获取高匹配的编码示例的步骤包括:
48、对待分析的代码中的功能模块信息与编码规范库中各个编码示例的功能模块信息之间的匹配度进行计算,其中,功能模块信息包括函数、变量和条件语句;
49、找到匹配度最高的编码示例,并判断其匹配度是否超过预设匹配度阈值;
50、若超过预设匹配度阈值,则匹配度最高的编码示例定为高匹配的编码示例。
51、本发明还提供一种基于大模型的安全编码规范多标融合系统,用于执行基于大模型的安全编码规范多标融合方法,包括:
52、第一构建模块:用于采集国家法律法规、标准规范及编码相关规定并构建编码多标要求库;
53、第二构建模块:用于采集大量编码规范样本与相应的编码示例并构建编码规范库,每个编码规范样本对应一个或多个编码示例,其中,编码规范样本包括正确样本和有缺陷样本,正确样本为符合规范的编码示例样本,有缺陷样本为不符合规范的编码示例样本;
54、第一训练模块:用于将预处理后的编码多标要求库提交给大语言模型进行训练,以通过大语言模型对编码多标要求库中的条款进行自然语言理解、合并及拆解,并将经过自然语言理解、合并及拆解处理后的条款进行重新组合,以形成编码多标要求融合库;
55、第二训练模块:用于将编码规范库输入大语言模型进行学习训练,以通过大语言模型将编码规范库中的编码规范样本与其在编码多标要求融合库中符合的条款进行映射;
56、代码分析模块:用于编码时,将待分析的代码片段及更新的编码多标要求融合库输入训练好的大语言模型,以对大预言模型进行重新训练或微调,通过重新训练或微调后的大语言模型对待分析的代码片段进行功能模块信息识别,并根据识别的功能模块信息从编码规范库中查询获取高匹配的编码示例,根据高匹配的编码示例找到相应的编码规范样本,并生成参考编码规范样本的提示,及根据与高匹配的编码示例相应的编码规范样本找到其映射的条款及获取其合规性,以实时反馈待分析的代码片段的实时合规性。
57、本发明的有益效果在于,与现有技术相比,本发明的基于大模型的安全编码规范多标融合方法及系统,主要用于在实现自动化和智能化的安全编码指导,通过采集相关法律法规和编码规范,构建了编码多标要求库和编码规范库。利用大语言模型对这些库进行理解和映射,实现了条款的自然语言理解、合并及拆解,以及编码规范样本与条款的准确映射。且在编码过程中,方案能实时反馈代码片段的合规性,为开发人员提供高匹配的编码示例和参考规范样本,能够有效地指导安全编码的开发,提高代码质量和安全性。
- 还没有人留言评论。精彩留言会获得点赞!