一种高性能的分布式海量向量相似检索系统及方法与流程
本发明属于向量检索,特别涉及一种高性能的分布式海量向量相似检索系统及方法。
背景技术:
1、随着深度学习的使用,在图像检索、人脸对比、导航推荐等应用场景的系统的架构变成了如dssm(deep structured semantic model,深层结构语音模型,又称双塔模型)等架构,通过dnn(deep neural network,深度神经网络)将用户特征映射到用户特征向量,特征向量可以基于embedding技术生成,用于表示深层特征信息。如推荐系统中,将用户和物品映射到同一向量空间,然后采用相似度计算的方式进行向量索引召回距离最近的若干个向量,即去物品向量库里查找特征(embedding)最相似的物品,从而为用户推荐其兴趣偏好的物品。
2、faiss是一个开源的ai相似性搜索工具,针对聚类和相似性搜索,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前较为成熟的近似近邻搜索库,能使开发者快速搜索相似多媒体文件。公开号为cn109711298a的中国发明专利公开了一种基于faiss的高效人脸特征值检索的方法和系统,基于faiss开源的ai相似性搜索工具,开发出人脸检索模块,从人脸特征值存储模块中检索出与待比对人脸特征值相似度比对分值最高的脸部图像的唯一标识、以及对应的比对分值,再执行检索结果判断,以加快人脸特征值的检索速度;同时,在检索过程中,不断优化人脸特征值库,减少其中重复度较高的人脸图像,挑选出最具有典型性的人脸图像。
3、该方法使用faiss工具可以高效的实现向量特征的相似计算,为人脸比对提供帮助。但由于faiss工具是基于内存的,该方法不支持横向扩展;若大量数据的推荐场景下,向量库的规模将是海量的,且向量维度一般可以达到512、1024,甚至更大,仅仅依靠该方法中所涉及的操作无法满足快速的相似向量检索服务。
技术实现思路
1、本发明提供一种高性能的分布式海量向量相似检索系统及方法,旨在解决现有技术不支持横向扩展及在海量向量库的情况下性能不足的问题。
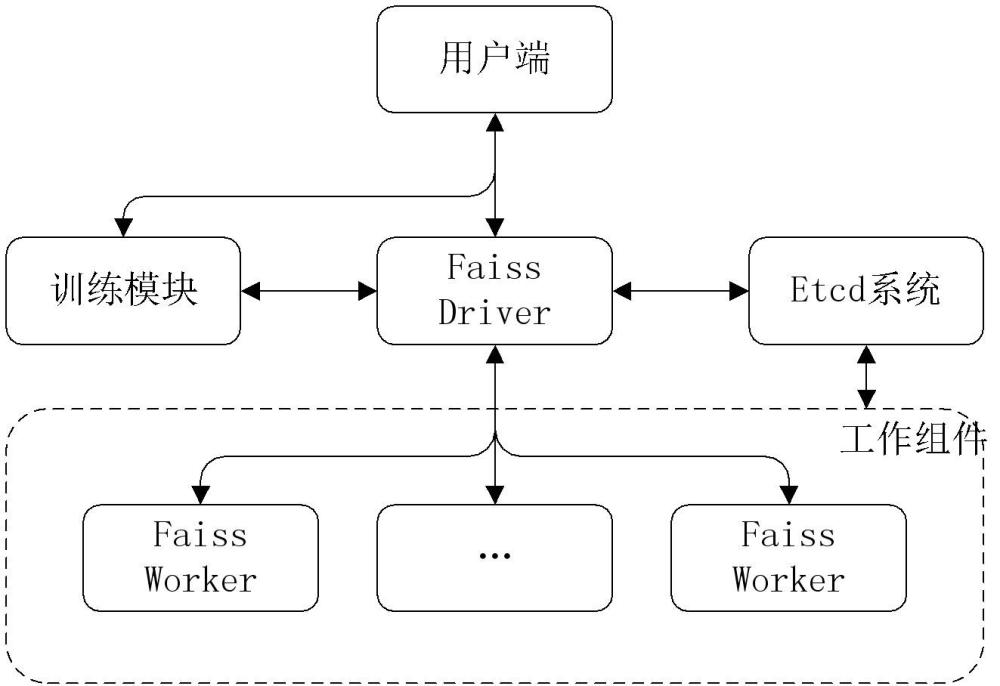
2、为解决上述技术问题,本发明提出的检索系统基于faiss数据库,包括faissdriver、若干faiss worker及etcd系统;
3、所述faiss driver用于接收用户端的查询请求,并将所述查询请求进行代理转发至选定的faiss worker,被配置为执行加载配置etcd监听、退出前置处理、服务发现及主从选举任务;
4、所述faiss worker为检索系统中执行查询计算的单元,被配置为执行含配置管理、停机处理、定时任务、加载索引及查询计算任务,用于计算相似向量检索及更新在线或离线索引文件;
5、所述etcd系统用于保存faiss worker列表、faiss worker的主从状态、faissworker的健康状态、索引文件的外部存储模块地址及索引文件列表。
6、优选地,所述检索系统还包括训练模块,所述训练模块为faiss trainer,用于进行向量检索模型的训练,将训练好的索引文件供faiss worker使用。
7、优选地,所述加载配置etcd监听具体为:faiss driver加载etcd服务地址,监听etcd中faiss worker的主从变化及生存状态;
8、所述退出前置处理具体为:当由于人为因素或服务器资源问题导致服务失败而关闭或重启时,faiss driver对faiss worker触发通知;
9、所述服务发现具体为:faiss driver监听faiss worker的状态并对检索的请求进行转发;
10、所述主从选举操作具体为:faiss driver根据faiss worker集群的状态选举主节点,并将主节点进行注册操作,将faiss worker主从节点地址更新至etcd中。
11、优选地,所述主从选举采用的算法为raft算法。
12、优选地,所述faiss driver还被配置为执行日志初始化操作,具体为:faissdriver在服务启动时初始化日志文件,用于记录faiss driver请求相关的信息和请求操作。
13、优选地,所述配置管理具体为:faiss worker加载或更新配置文件,以获取当前集群索引文件的存储地址、索引文件列表及索引文件;
14、所述停机处理具体为:faiss worker接受到faiss driver发出的停机信号时,触发停机处理操作并保存索引文件;
15、所述定时任务具体为:faiss worker定时向faiss driver汇报状态;
16、所述加载索引具体为:faiss worker在启动执行查询计算任务时,首先加载索引文件。
17、优选地,所述配置管理任务中加载或更新的配置文件保存于etcd系统。
18、优选地,所述定时任务的心跳时间设置为3秒。
19、相应的,本发明还提出一种高性能的分布式海量向量相似检索方法,所述方法使用上述的检索系统,包括以下步骤:
20、s1:客户端指定待检索的向量库名称及向量维度,通过faiss driver提供的接口向faiss driver发起查询请求;
21、s2:所述faiss driver根据etcd系统中保存的faiss worker状态,将查询任务发送至选定的faiss worker进行向量检索计算;
22、s3:接收任务faiss worker加载索引文件,将向量检索计算的结果返回faissdriver,由faiss driver转发至客户端。
23、优选地,所述步骤s2中选择faiss worker的因素包括:
24、服务发现机制,所述服务发现机制基于etcd或consul的服务注册表,使得faissdriver可以动态地发现当前可用的faiss worker节点;
25、负载均衡策略,faiss driver基于faiss worker节点的当前负载情况及性能指标将查询请求分散到不同的faiss worker上;
26、节点健康状态,faiss driver在选择faiss worker之前,进行节点的健康检查,包括faiss worker是否在线、是否能够正常响应查询请求,将出现故障的节点排除在负载均衡的选择范围之外;
27、查询路由策略,根据设定的路由策略将特定的查询任务指派到特定的faissworker。
28、与现有技术相比,本发明具有以下技术效果:
29、1.本发明提出的海量向量相似检索系统引入代理转发服务机制以及主从节点注册机制,faiss driver为faiss server的proxy代理服务,faiss driver不负责实际的向量相似计算以及在线和离线索引文件的更新同步操作,faiss driver实际对外主要负责query请求的代理转发工作。通过faiss driver转发查询计算请求,由分布式的多个faissworker执行具体的查询计算工作,可高效地处理向量的查询计算任务,适用于海量向量相似检索,高效地处理向量特征的query查询计算请求。不仅限于cv图像处理、nlp自然语言处理、推荐算法等业务场景,并提供横向扩展能力。
30、2.本发明提出的向量相似检索系统使用faiss driver选择faiss worker的因素包括服务发现机制、负载均衡策略、节点健康状态及查询路由策略,可灵活匹配适合的faiss worker执行检索计算,即使在个别faiss worker因为故障宕机的情况下,也能保障相似向量检索服务,提高整个系统的可靠性。
31、3.本发明提出的向量相似检索系统在faiss worker上配置停机处理任务,在某个faiss worker服务不可用时或意外停机退出时进行处理操作,保证提供准确可靠的检索服务,提高检索系统的容错性。
- 还没有人留言评论。精彩留言会获得点赞!