面向智慧养殖问答的模型温度自适应微调方法
本发明属于智慧养殖的,具体涉及一种面向智慧养殖问答的模型温度自适应微调方法。
背景技术:
1、大型语言模型(llm)领域最近的蓬勃发展已经在许多领域引起了极大的关注。为了使llm适合特定领域(例如智慧养殖系统),需要利用领域知识进行微调。然而,在针对智慧养殖应用微调llm的过程中,出现了两个问题。首先是任务多样性的问题,现实世界的智慧养殖场景中有许多不同的任务,例如根据传感器数据调整养殖环境以提供最适宜的条件,以及基于历史数据和市场需求,进行生产计划和预测,以确保生产与市场需求的匹配等。其次是数据不平衡问题,这种多样性常常导致微调不理想。此外,微调的高昂成本可能令人望而却步,阻碍了llm的应用。
2、传统的多任务学习对多个不同任务的数据集进行启发式采样(启发式采样是一种基于经验和直觉的样本选择方法,而不是基于严格的统计或数学规则。这种采样策略通常使用领域专业知识或经验来指导样本的选择,以提高模型的性能或训练效果),通过启发式采样可以避免模型对某些任务过拟合和欠拟合。通过将采样来自不同的数据集的固定数量的样本作为一个批次传递给模型,以此达到模型在不同任务上进行学习的结果。然而该方法的一个缺点是在训练完成之后,如果需要再新增一个新的任务则需要将新任务和旧任务在预训练模型上重新进行微调。
3、模型的temperature温度参数设置中(在大语言模型中,temperature参数是一个调控生成文本随机性的参数。它用于调整模型生成的概率分布,进而影响生成文本的多样性),传统的方法是人为设定。但是针对多任务学习的环境,不同任务需要回答的创意程度不同(在多任务学习的环境中,生成文本的创意程度可能因任务的不同而有所变化。创意程度指的是生成文本时模型产生的新颖和独特的特征,以及文本中涵盖的多样性),因此针对多任务的场景,人为设置固定的温度表现不佳。
4、1、传统的多任务学习方法通常需要依赖人为选择适当的启发式抽样方法,以适应不同任务数据集的特点。这样的选择过程可能会对模型学习的效果产生影响,因为不同的抽样方法可能引入不同的偏差,从而影响模型的泛化性能。
5、2、当预训练模型在某些数据集上完成训练后,如果需要在该模型的基础上学习新的任务,传统方法可能面临灾难性遗忘的问题。重新将之前学到的知识和新知识一起在预训练模型上进行学习效率较低,限制了模型在多任务学习中的应用范围。
6、3、对预训练模型进行全参微调的过程需要较多的时间和计算资源。这是因为全参微调涉及对整个模型的参数进行调整,而对于大规模的模型,这一过程可能变得相当耗时,限制了模型的训练效率。
7、4、使用固定的温度参数可能使模型在回答问题时表现不够理想。固定的温度参数可能无法很好地适应不同任务对于文本生成的创意程度的需求,因此需要更加灵活的方法来动态调整温度参数,以提高模型生成文本的多样性和质量。
技术实现思路
1、本发明的主要目的在于克服现有技术的缺点与不足,提供一种面向智慧养殖问答的模型温度自适应微调方法,利用温度自适应模型的输出,以及使用注意力机制将多个针对单个任务的高效微调lora模块进行权重的自适应分配,提高模型在不同任务上的性能和泛化能力。
2、为了达到上述目的,本发明采用以下技术方案:
3、第一方面,本发明提供了一种面向智慧养殖问答的模型温度自适应微调方法,包括下述步骤:
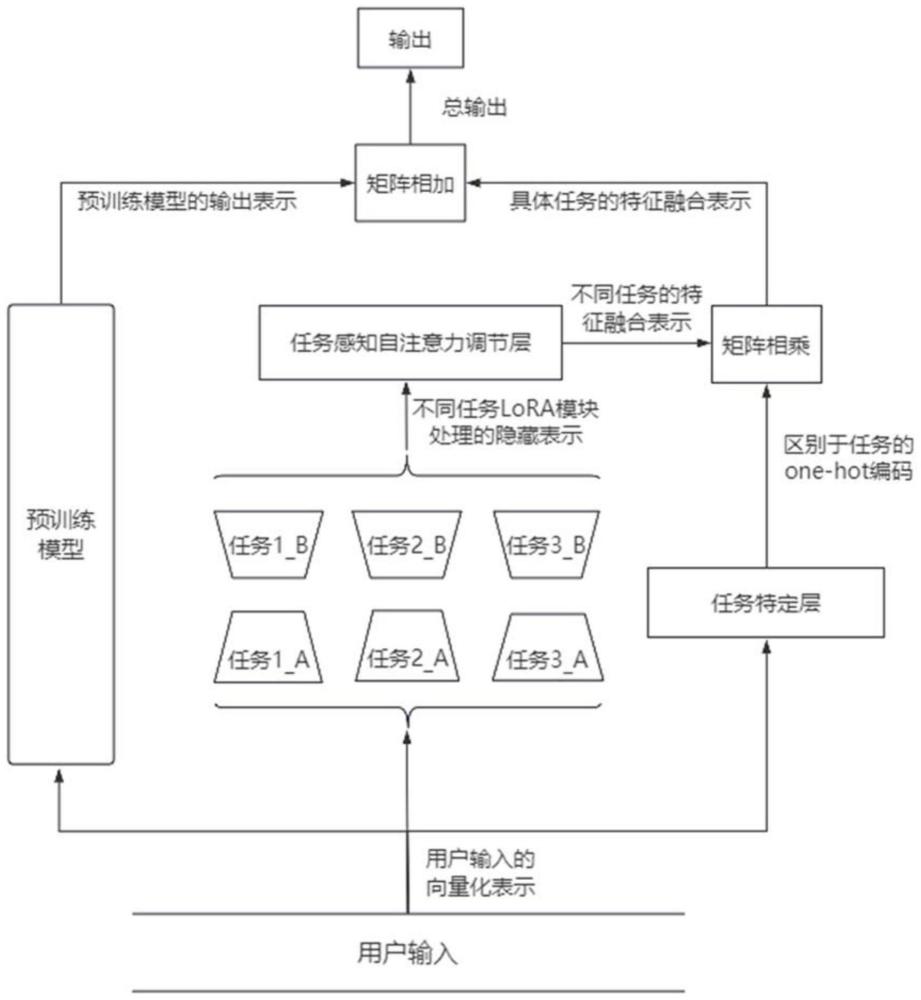
4、基于预设的大语言模型对原始问答数据集进行处理,获取每个样本的创意程度评估值;基于每个样本的问句及其对应的创意程度评估值构建新的数据集;
5、采用bert模型对问句进行表示,采用新的数据集对温度模型进行训练,以及对任务特定层进行训练;所述温度模型的目标是通过监督学习,使用处理后的数据集训练,使得温度模型能够通过学习数据中的模式,对文本进行创意性的评估;所述任务特定层在多个任务特定的lora模块经过任务感知自注意力调节后,根据问句选择其中一个神经元的输出;
6、对不同任务下的新数据集进行lora参数微调,分别得到不同的任务的lora模块;
7、使用任务感知自注意力调节层,将各个任务特定lora模块的输出进行特征融合。
8、作为优选的技术方案,所述基于预设的大语言模型对原始问答数据集进行处理,获取每个样本的创意程度,具体为:
9、基于预设的大语言模型对原始问答数据集中每一个样本进行分析,使用设定的提示词对大语言模型进行提问,得到大语言模型认为该样本的创意和保守程度。
10、作为优选的技术方案,所述创意程度评估值代表了大语言模型认为样本的创意和保守程度的评估,取值范围在0到1之间,其中0表示最保守的程度,1表示最具创意性的程度,中间的数值则表示介于创意和保守之间的某个权衡程度。
11、作为优选的技术方案,所述采用bert模型对问句进行表示,具体为:
12、当处理用户输入的文字时,使用bert模型对文本中的每个token进行表示,所述token是指文本被切分成的最小单位,bert模型通过学习文本上下文,为每个token生成一个上下文相关的嵌入向量;所述最小单位为一个单词、子词或者是一个字符。
13、作为优选的技术方案,所述对任务特定层进行训练,具体为:
14、为每个任务针对其对应lora模块的顺序分配一个独有的one-hot编码;
15、将原始数据集中每个样本的问句与该样本对应任务的one-hot编码进行组合,形成一个新的数据集;
16、使用这个新数据集对任务特定层进行有监督训练。
17、作为优选的技术方案,所述对不同任务下的新数据集进行lora参数微调,分别得到不同的任务特定lora模块,具体为:
18、对于预训练的权重矩阵w0∈rd×k,d表示权重矩阵w0的行数量,k表示权重矩阵w0的列数量,rd×k表示矩阵的维度,即d行k列,通过用低秩分解w0+δw=w0+ba表示更新,a和b均为低秩矩阵,其中b∈rd×r,a∈rr×k,并且秩r<<min(d,k),训练期间,w0被冻结,不接收梯度更新,而a和b包含可训练参数;同时,w0和δw=ba都接受相同的输入,并将它们各自的输出向量按位置求和;
19、通过优化交叉熵损失函数,使得这两个低秩矩阵能够适应下游任务的需求,在微调过程中,原始模型的权重矩阵被冻结,只有低秩矩阵a和b需要训练。
20、作为优选的技术方案,所述使用任务感知自注意力调节层,将各个任务特定lora模块的输出进行特征融合,具体为:
21、在训练之前,将针对不同任务lora模块的顺序与任务特定层针对不同任务的one-hot编码相对应;
22、为每个encoder层使用一组独立的线性投影矩阵wq,wk,wv,这些矩阵用于将各个lora模块的输出作为输入x映射到三个不同的子空间,从而得到多组针对特定lora模块的查询、键和值向量;在自注意力机制中,给定查询、键和值向量,计算注意力分数,并利用这些分数对值进行加权求和;使得模型为每个lora模块学习不同的关注度,以更有效地捕捉各自的特征;最终,通过对多组注意力机制的输出进行加权求和,得到了对多个lora模块输出的综合关注表示;所述综合关注表示通过与任务特定的权重矩阵相乘,选择特定任务的融合特征,使得模型在应对不同任务时能够更灵活地关注相关的语义信息,给定一个查询向量q、键向量k和值向量v,缩放点积注意力的计算过程为:
23、
24、其中·表示点积操作,dk是查询和键的维度;
25、通过训练任务特定层,使任务特定层能够接受用户输入问句的向量表示,并输出针对特定任务的独热编码,在此过程中,用户输入问句的向量表示分别经过了任务感知自注意力调节层和任务特定层;通过将任务感知自注意力调节层的输出特征融合表示和任务特定层针对任务的one-hot编码相乘,得到针对当前任务的特征融合表示。
26、第二方面,本发明提供了一种面向智慧养殖问答的模型温度自适应微调系统,应用于所述的面向智慧养殖问答的模型温度自适应微调方法,包括创意程度评估模块、模型训练模块、参数微调模块和特征融合模块;
27、所述创意程度评估模块,用于基于预设的大语言模型对原始问答数据集进行处理,获取每个样本的创意程度评估值;基于每个样本的问句及其对应的创意程度评估值构建新的数据集;
28、所述模型训练模块,用于采用bert模型对问句进行表示,采用新的数据集对温度模型进行训练,以及对任务特定层进行训练;所述温度模型的目标是通过监督学习,使用处理后的数据集训练,使得温度模型能够通过学习数据中的模式,对文本进行创意性的评估;所述任务特定层在多个任务特定的lora模块经过任务感知自注意力调节后,根据问句选择其中一个神经元的输出;
29、所述参数微调模块,用于对不同任务下的新数据集进行lora参数微调,分别得到不同的任务的lora模块;
30、所述特征融合模块,用于使用任务感知自注意力调节层,将各个任务特定lora模块的输出进行特征融合。
31、第三方面,本发明提供了一种电子设备,所述电子设备包括:
32、至少一个处理器;以及,
33、与所述至少一个处理器通信连接的存储器;其中,
34、所述存储器存储有可被所述至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的面向智慧养殖问答的模型温度自适应微调方法。
35、第四方面,本发明提供了一种计算机可读存储介质,存储有程序,所述程序被处理器执行时,实现所述的面向智慧养殖问答的模型温度自适应微调方法。
36、本发明与现有技术相比,具有如下优点和有益效果:
37、1.本发明通过lora微调的方式,利用养殖领域不同任务的数据集对大语言模型进行微调,更加节省时间和计算资源。
38、2.本发明利用任务感知自注意力调节层对不同任务的lora模块进行特征融合,利用其他任务lora模块的权重来提高当前任务的回答质量,可以促使模型学习到一些任务之间的相关性,从而提高性能;并且使用任务特定层对特定任务特征融合表示进行选择。
39、3.本发明获取温度模型针对用户输入的温度预测,让大模型能够根据不同的问题的创意程度生成令用户更满意的答案。
40、4.本发明通过单个任务数据集训练单个lora模块的方式能够避免传统多任务学习中灾难性遗忘的问题,同时可以免去研究人员考虑启发式采样的策略。
- 还没有人留言评论。精彩留言会获得点赞!