一种文本抽取的方法及装置与流程
本发明涉及数据处理领域,具体而言,涉及一种文本抽取的方法及装置。
背景技术:
1、在文本抽取任务中,语义相似度计算是最重要且技术含量最高的工作之一。业务侧通常会提供一批文本和一批目标句子,要求技术人员从这批文本中抽取出与这批目标句子相似的句子。为了衡量相似度,需要使用语义相似度模型。目前,业界主要采用两种方法来计算语义相似度:交叉编码器cross-encoder和双向编码器bi-encoder。
2、cross-encoder方法在计算语义相似度时,需要将两个句子拼接在一起并输入给模型。例如,对于10000个句子两两计算相似度,需要进行约五千万次模型计算,一台机器需要执行65小时才能完成计算。因此,在工业界,bi-encoder模型在计算语义相似度方面更为常用。
3、bi-encoder模型分为有监督模型(如来自变换器的句子双向编码器表示模型(sentence-bidirectional encoder representations from transformers,简称sbert))和无监督模型(如具有共同语义提取器的语义相似度模型(semantic similarity withcommon semantic extractors,简称simcse))两种。
4、相关技术中,语义相似度模型在训练阶段使用软最大值softmax和交叉熵损失函数,在预测阶段(相似性计算阶段)则使用余弦相似度计算,在训练阶段和预测阶段的计算相似度的函数不一致的情况会对模型的最终表现效果产生负面影响。
技术实现思路
1、本发明实施例提供了一种文本抽取的方法及装置,以至少解决相关技术中在模型训练阶段和预测阶段中计算相似性方式不一致而导致抽取结果不够精准的问题。
2、根据本发明的一个实施例,提供了一种文本抽取的方法,包括:
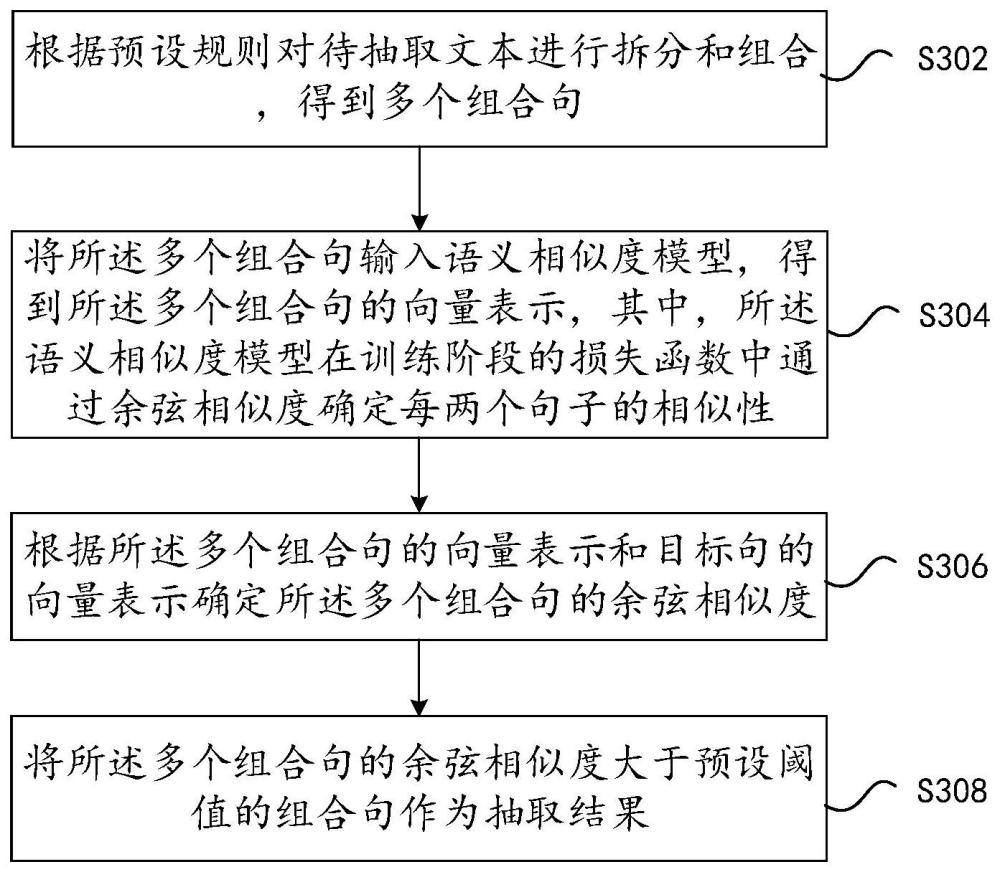
3、根据预设规则对待抽取文本进行拆分和组合,得到多个组合句;
4、将所述多个组合句输入语义相似度模型,得到所述多个组合句的向量表示,其中,所述语义相似度模型在训练阶段的损失函数中通过余弦相似度确定每两个句子的相似性;
5、根据所述多个组合句的向量表示和目标句的向量表示确定所述多个组合句的余弦相似度;
6、将所述多个组合句的余弦相似度大于预设阈值的组合句作为抽取结果。
7、根据本发明的另一个实施例,还提供了一种文本抽取的装置,包括:
8、拆分组合模块,用于根据预设规则对待抽取文本进行拆分和组合,得到多个组合句;
9、向量获取模块,用于将所述多个组合句输入语义相似度模型,得到所述多个组合句的向量表示,其中,所述语义相似度模型在训练阶段的损失函数中通过余弦相似度确定每两个句子的相似性;
10、确定模块,用于根据所述多个组合句的向量表示和目标句的向量表示确定所述多个组合句的余弦相似度;
11、结果获取模块,用于将所述多个组合句的余弦相似度大于预设阈值的组合句作为抽取结果。
12、根据本发明的又一个实施例,还提供了一种计算机可读的存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被处理器运行时执行上述任一项方法实施例中的步骤。
13、根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
14、解决了相关技术中在模型训练阶段和预测阶段中计算相似性方式不一致而导致抽取结果不够精准的问题,本发明让模型直接学习句子表示,更具泛化性,模型在训练阶段和预测阶段都使用了余弦相似度计算两个句子的相似性,能够提高结果的准确性。
技术特征:
1.一种文本抽取的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述语义相似度模型在训练阶段通过以下步骤对模型进行训练:
3.根据权利要求1所述的方法,其特征在于,根据预设规则对待抽取文本进行拆分和组合,得到多个组合句包括:
4.根据权利要求3所述的方法,其特征在于,根据第一预设字符对所述待抽取文本进行拆分得到多个最小句包括:
5.根据权利要求4所述的方法,其特征在于,根据第二预设字符对待抽取文本的段落进行拆分,得到一个或多个所述原始句之前,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,所述语义相似度模型在训练阶段通过以下步骤确定损失函数的损失值:
7.根据权利要求6所述的方法,其特征在于,所述损失函数的表达式为
8.根据权利要求7所述的方法,其特征在于,对于当前训练轮次中正负样本集合,通过动量负样本队列使所述正负样本集合中的正样本和负样本的数量相等,包括:
9.一种文本抽取的装置,其特征在于,包括:
10.一种计算机可读的存储介质,其特征在于,所述存储介质中存储有计算机程序,其中,所述计算机程序被处理器运行时执行所述权利要求1至8任一项中所述的方法。
11.一种电子装置,包括存储器和处理器,其特征在于,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行所述权利要求1至8中任一项所述的方法。
技术总结
本发明提供了一种文本抽取的方法和装置,其中,该方法包括:根据预设规则对待抽取文本进行拆分和组合,得到多个组合句;将所述多个组合句输入语义相似度模型,得到所述多个组合句的向量表示,其中,所述语义相似度模型在训练阶段的损失函数中通过余弦相似度确定每两个句子的相似性;根据所述多个组合句的向量表示和目标句的向量表示确定所述多个组合句的余弦相似度;将所述多个组合句的余弦相似度大于预设阈值的组合句作为抽取结果,解决了相关技术中在模型训练阶段和预测阶段中计算相似性方式不一致而导致抽取结果不够精准的问题。
技术研发人员:石聪,张彬,黄彪,王田利,贾亚璐,张高伟
受保护的技术使用者:中国光大银行股份有限公司
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!