一种基于主题增强的中文社交媒体少样本立场检测方法
本发明涉及网络安全,具体为一种基于主题增强的中文社交媒体少样本立场检测方法。
背景技术:
1、随着社交媒体的快速发展,人们对于不同目标发表的观点日益增长。立场检测是一项能够从观点文本中自动判断发表者对于给定目标态度的任务。这些态度通常为:支持、反对或中立。与情感分析领域对文本中的方面或实体的情绪进行检测不同,立场分析旨在挖掘人们对于特定目标的基本观点,该目标可能不会明确出现在文本中。通过立场检测研究,能够获取到公众对热门话题的立场倾向。
2、早期的立场检测工作主要集中于在线辩论,其检测方法包括基于手工特征的机器学习方法和基于主题特征的方法。而后,人们对在社交媒体上进行立场检测研究越来越感兴趣。近期的研究通常采用深度学习方法来对博文文本和立场目标进行建模。他们通常使用lstm(long short-term memory)、cnn(convolutional neural networks)、gru(gaterecurrent unit)和注意力网络来深度挖掘文本和目标的语义内容,并建立两者的联系。
3、同时,传统的立场检测任务都是针对中等大小的样本数据进行处理。然而,由于立场目标涉及的领域十分广泛,且随着时间的变化,新的目标层出不穷,为每个目标提供足够规模的标记数据是不现实的。最近的研究将提示学习应用于立场检测任务中来解决样本不足的问题以提高检测性能。同时大多数的研究都是针对英文社交媒体,而对中文社交媒体上的研究较少。因此,亟需一个能在少样本场景下自动化判定面向中文社交媒体文本的立场检测模型。
技术实现思路
1、针对上述问题,本发明的目的在于提供一种基于主题增强的中文社交媒体少样本立场检测方法,在少样本场景能够更有效检测文本立场,且在样本量较少的时候有优秀的性能提升能力和泛化能力。技术方案如下:
2、一种基于主题增强的中文社交媒体少样本立场检测方法,包括以下步骤:
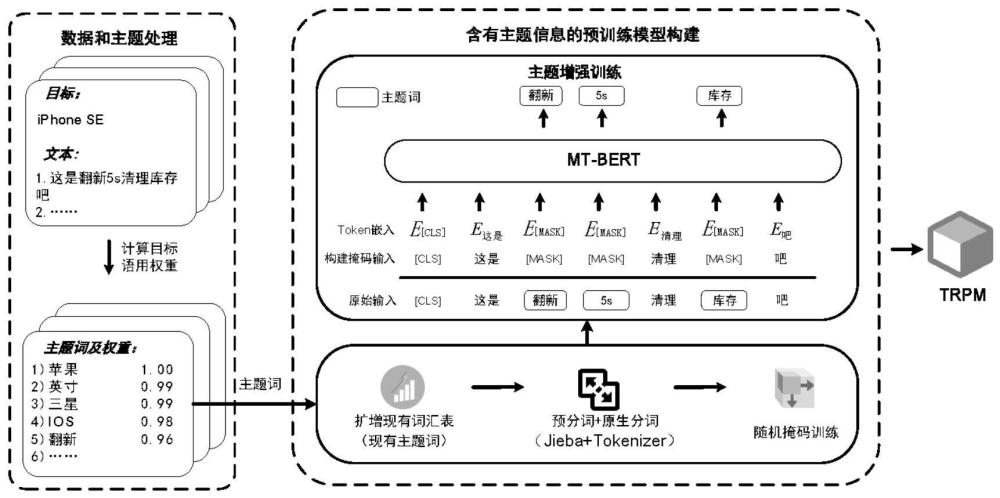
3、步骤1:对大规模语料进行清洗与预处理,通过目标语用权重算法提取出与目标高度相关的主题词;
4、步骤2:将主题词添加到分词器词典中进行汉语分词,再通过随机掩码预训练来构建基于词的多目标语料的预训练语言模型mt-bert(multi-target bert多目标bert);
5、步骤3:进行主题词增强预训练,来加强模型对目标的感知能力,得到主题增强预训练模型;
6、步骤4:针对立场任务和情感任务构建不同的提示模板输入:将原始文本与提示模板后缀按照nsp(next sentence prediction下一句预测)任务的输入格式分为上下句,通过主题增强预训练模型获得立场信息嵌入向量和情感信息嵌入向量;
7、步骤5:通过基于提示学习的多任务立场检测模型,进行立场检测为主,情感分析为辅的分类任务,具体为:将立场信息嵌入向量和情感信息嵌入向量生成两个具有上下文关系的词向量,再两个词向量进行拼接,通过全连接层进行变换后提取出立场掩码向量,再通过点乘来衡量该掩码向量与不同立场标签向量之间的距离,最后利用softmax函数获得标签预测值。
8、进一步的,所述步骤1具体包括:
9、步骤1.1:将未标注语料与训练语料作为模型预训练的最终语料c,对语料c进行预处理,包括过滤人名、繁体中文转换为简体和删除网页链接操作;
10、步骤1.2:从语料c中识别一系列指向目标的关键主题词,所述主题词为在特定目标的立场表达中占据主导地位的词;
11、基于每个词w在当前目标语料库和其他目标语料库中出现的次数,来计算第k个词wk在当前目标下的语用权重α(wk):
12、
13、
14、其中,代表词wk在当前目标语料的词频占所有语料词频的比重;εt(wk)代表词wk在当前目标语料下的词频,εo(wk)代表词wk在其他目标语料下的词频;和分别代表词频比重的最小值和最大值;
15、针对每个目标都提取出了一组主题词组:
16、
17、其中,vt表示当前目标的词表大小,t代表当前目标。
18、更进一步的,所述步骤2中,汉语分词具体过程如下:
19、步骤2.1:将提取出的主题词添加到词汇表v;在预分词过程中,使用带有自定义词典的jieba分词模块将句子s分割成词组;
20、步骤2.2:循环遍历词组中的词语,并确定词语是否被包含在词汇表v中;如果能够在v上找到,则保留这个词语,否则使用roberta的原生分词器再次分割短语;
21、步骤2.3:将所有分词结果进行拼接,形成最终的分词结果。
22、更进一步的,所述步骤3中,主题增强训练具体过程如下:
23、步骤3.1:对原始输入文本进行主题掩码嵌入,即判断每个token是否属于主题词组ot;如果属于主题词组ot,则将掩码的token进行替换,否则就判断下一个;
24、步骤3.2:掩码输入构建结束后根据多目标语料的预训练语言模型mt-bert的词汇表v进行token嵌入,并进行掩码语言模型任务,以提高主题词的语境权重。
25、更进一步的,所述步骤3.1中,限定掩码数量大小为原句大小的40%。即当原句中包含的主题词数量大于原句大小的40%时,将忽略超出的部分,而当主题数量小于原句的40%时,将采用随机掩码的策略来达成限定条件。
26、更进一步的,所述步骤4具体为:
27、设计一个描述中文立场检测任务的立场提示模板pt,以及描述情感分类任务的情感
28、提示模板ps,对于每一对输入x=(text,target),定义下面两种提示模板:
29、pt(text,target)=[cls]<text>[sep]w1t,w2t,...,wit<target>wi+1t,wi+2t,...,wnt[mask][sep]
30、ps(text,target)=[cls]<text>[sep]w1s,w2s,...,wls[mask][sep]
31、其中,[cls]、[sep]和[mask]为bert(bidirectional encoder representationfrom transformers双向transformer的编辑器)原始语料库的特定标识符;
32、从而得到立场信息嵌入向量tt=[t1t,t2t,...,tnt],将其作为立场检测任务的输入;并得到情感信息嵌入向量ts=[t1s,t2s,...,tls],将其作为情感分析的输入。
33、更进一步的,所述步骤5具体包括:
34、步骤5.1:通过词汇表将tt=[t1t,t2t,...,tnt]和ts=[t1s,t2s,...,tls]转换为id,并通过主题增强预训练模型进行编码,生成具有上下文关系的词向量ht=[h1t,h2t,...,hnt]和hs=[h1s,h2s,...,hls];所述词向量的维度大小为e;
35、将两个词向量进行拼接,并通过全连接层与正则化,将输出向量乘以词表的嵌入矩阵,使得输出的维度转换为词表维度得到xt,如下式所示:
36、xt=tanh(htw1t+b1t)wvocab
37、其中,表示立场检测任务中矩阵大小为2e×e的全连接层;表示矩阵大小为e×v的词表嵌入矩阵;表示立场检测任务中大小为2e的向量;v为词表大小;
38、通过找到标识符[mask]的位置,提取出立场掩码隐藏状态
39、情感分析任务仅考虑情感词向量,并且输入相似结构的网络,具体如下式所示:
40、xs=tanh(hsw3s+b3s)wvocab
41、其中,表示情感分析任务中矩阵大小为e×e的全连接层;表示情感分析任务中大小为e的向量;
42、同样通过找到标识符[mask]的位置,提取情感掩码隐藏状态
43、步骤5.2:将标签映射到连续的标签向量:针对立场检测任务构造三个标签向量:vfavor、vagainst和vnone,分别代表favor、against和none;针对情感分析任务构造三个标签向量:vpositive、vnegative和vneutral,分别代表positive、negative和neutral;同时,标签向量的维度大小为e;
44、步骤5.3:使用线性变换将标签向量映射为将掩码隐藏状态hmask和的点积送入softmax层得到最终预测值pi,如下式所示:
45、
46、其中,代表一组标签向量,为其中一个标签向量;在立场分析任务中在情感分析任务中
47、更进一步的,所述基于提示学习的多任务立场检测模型以连续的方式进行训练,并且在每个时间步,整体训练目标包括两部分:立场检测损失lmain和情感分析损失laux;两个任务都为测量预测标签与真实标签之间的距离,该距离通过标准交叉熵损失函数进行计算,具体下式所示:
48、
49、其中,ce交叉熵损失函数,和分别代表预测标签和真实标签,并且x代表d中的样本,d为数据集;
50、每个时间步最终的损失lall由lmain和laux组成,计算方式如下所示:
51、lall=λlmain+(1-λ)laux
52、其中,λ是微调后的超参数,其代表了立场检测任务的权重。
53、本发明的有益效果是:
54、1)本发明是第一个在少样本立场检测任务中使用词级的中文预训练模型来捕获特定目标主题信息的研究。通过主题增强预训练的方式来提高语言模型对文本中主题信息的感知,以此来获取少样本立场检测任务中与目标相关的隐式表达,有效的增强上下文感知。
55、2)本发明通过目标语用权重公式提取出与目标高度相关的主题词,能够缓解因目标内容的语义信息有限导致无法为立场检测提供足够信息的问题。
56、3)本发明针对立场任务和情感任务构建不同的提示模板输入,将其输入多任务学习框架进行立场检测为主,情感分析为辅的分类任务,有效弥补主题增强预训练阶段和下游任务之间的差距,促进对预训练模型中主题知识的获取,提升少样本立场检测的性能。
- 还没有人留言评论。精彩留言会获得点赞!