一种数据湖的分区方法及相关装置与流程
本技术涉及计算机领域,特别是涉及一种数据湖的分区方法及相关装置。
背景技术:
1、数据湖(data lake)是一种数据存储架构,它可以容纳大量不同类型和不同格式的数据,并支持用于数据分析和机器学习的高级查询和处理。举例来说,hudi数据湖是一个流式数据湖平台,支持通过计算引擎进行写入和查询。hudi数据湖可以包括多个文件组file group,一个文件组中包含多条数据,每条数据包括数据表中多个字段下的值,且每个文件组具有对应的文件组标识file id。当需要对hudi数据湖存储的数据进行查询、修改或增加等操作时,需要先定位到对应的文件组,再执行后续操作。
2、相关技术中,可以采用以下两种方案定位到对应的文件组:
3、一种方案为:在外部数据库,例如hbase数据库中存储每条数据的主键与文件组标识的对应关系,当需要对数据执行操作时,从hbase数据库中可以获取所需执行操作的数据的主键对应的文件组标识,进而定位到文件组。但方案依赖外部数据库,容易存在数据库和数据湖数据不一致的问题,运维困难。
4、另一种方案为:将多个文件组标识与多个哈希桶一一对应,也就是说,为每个文件组绑定一个哈希桶,当需要对数据执行操作时,确定所需执行操作的数据对应的哈希桶,也即定位到对应的文件组。然而,该方案中哈希桶的个数确定好就无法更改,但数据湖所存入的数据量却无法预先估量,容易出现一个或一些文件组所存入的数据过多的问题;或者,预先确定的哈希桶个数过多,导致对应的文件组数量过多的问题。以上两种情况均会影响数据湖的性能。
5、因此,如何在实现文件组的定位的同时,避免影响数据湖的性能,成为目前亟待解决的问题。
技术实现思路
1、有鉴于此,本技术实施例提供了一种数据湖的分区方法及相关装置,目的是在实现数据组定位的同时,避免影响数据湖的性能。
2、第一方面,本技术实施例提供了一种数据湖的分区方法,数据湖包括多个第一分区,所述多个第一分区分别具有不同的分区编号,所述方法包括:
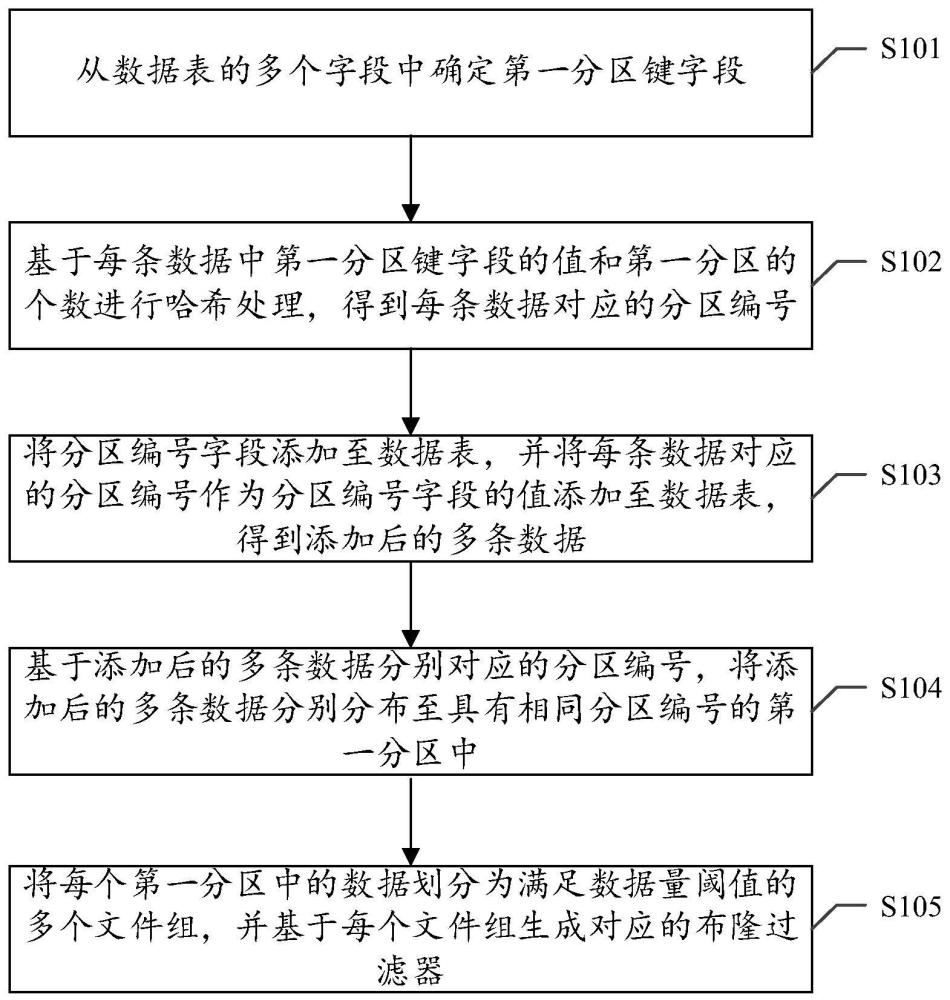
3、从数据表的多个字段中确定第一分区键字段;所述数据表包括多条数据,每条数据包括所述多个字段分别对应的值;
4、基于每条数据中所述第一分区键字段的值和所述第一分区的个数进行哈希处理,得到每条数据对应的分区编号;
5、将分区编号字段添加至所述数据表,并将每条数据对应的分区编号作为所述分区编号字段的值添加至所述数据表,得到添加后的多条数据;
6、基于所述添加后的多条数据分别对应的分区编号,将所述添加后的多条数据分别分布至具有相同分区编号的第一分区中;
7、将每个第一分区中的数据划分为满足数据量阈值的多个文件组,并基于每个文件组生成对应的布隆过滤器,所述布隆过滤器用于定位对应的文件组。
8、可选地,所述方法还包括:
9、获取包括所述第一分区键字段的数据查询条件;
10、基于所述数据查询条件中的第一分区键字段对应的值,以及所述第一分区的个数进行哈希处理,得到所述数据查询条件对应的第一查询分区编号;
11、将分区编号字段为所述第一查询分区编号作为条件添加到第一分区剪枝条件中;
12、基于添加后的第一分区剪枝条件对所述多个第一分区进行剪枝处理,确定满足所述添加后的第一分区剪枝条件的第一分区。
13、可选地,所述第一分区键字段包括所述多个字段中的至少两个字段;所述基于每条数据中所述第一分区键字段的值和所述第一分区的个数进行哈希处理,得到每条数据对应的分区编号,包括:
14、基于每条数据中所述至少两个字段分别对应的值进行拼接处理;
15、针对每条数据,基于拼接后的值和所述第一分区的个数进行哈希处理,得到每条数据对应的分区编号。
16、可选地,所述数据表包括的多条数据为待执行增加操作的数据,或者,所述数据表包括的多条数据为待执行修改操作的数据。
17、可选地,所述数据湖包括多个第二分区,每个第二分区包括多个第一分区,一个第二分区中的多个第一分区分别具有不同的分区编号,所述方法还包括:
18、从所述多个字段中确定第二分区键字段;所述第二分区键字段与所述第一分区键字段不同;
19、从所述多条数据中,将在所述第二分区键字段下具有相同值的数据分布至同一个第二分区中;
20、所述基于每条数据中所述第一分区键字段的值和所述第一分区的个数进行哈希处理,得到每条数据对应的分区编号,包括:
21、基于每条数据中所述第一分区键字段对应的值,以及每条数据所属第二分区中第一分区的个数进行哈希处理,得到每条数据对应的分区编号;
22、所述基于所述添加后的多条数据分别对应的分区编号,将所述添加后的多条数据分别分布至具有相同分区编号的第一分区中,包括:
23、基于所述添加后的多条数据分别对应的分区编号,将所述添加后的多条数据分别分布至所属第二分区中具有相同分区编号的第一分区中。
24、可选地,所述方法还包括:
25、获取包括所述第一分区键字段的数据查询条件;
26、基于所述数据查询条件中所述第一分区键字段对应的值,以及一个第二分区中所述第一分区的个数进行哈希处理,得到所述数据查询条件对应的第二查询分区编号;所述多个第二分区均包括相同个数的第一分区;
27、将分区编号字段为所述第二查询分区编号作为条件添加到第二分区剪枝条件中;
28、基于所述第二分区剪枝条件对多个第二分区进行剪枝处理,确定满足所述第二分区剪枝条件的目标第二分区;
29、基于所述第二分区剪枝条件对所述目标第二分区中的多个第一分区进行剪枝处理,确定满足所述第二分区剪枝条件的第一分区。
30、可选地,所述从数据表的多个字段中确定第一分区键字段,包括:
31、将所述多个字段中的主键字段确定为所述第一分区键字段;所述主键字段的值在所述多条数据中各不相同。
32、第二方面,本技术实施例提供了一种数据湖的分区装置,数据湖包括多个第一分区,所述多个第一分区分别具有不同的分区编号,所述装置包括:
33、第一字段确定模块,用于从数据表的多个字段中确定第一分区键字段;所述数据表包括多条数据,每条数据包括所述多个字段分别对应的值;
34、第一哈希处理模块,用于基于每条数据中所述第一分区键字段的值和所述第一分区的个数进行哈希处理,得到每条数据对应的分区编号;
35、数据添加模块,用于将分区编号字段添加至所述数据表,并将每条数据对应的分区编号作为所述分区编号字段的值添加至所述数据表,得到添加后的多条数据;
36、第一数据分布模块,用于基于所述添加后的多条数据分别对应的分区编号,将所述添加后的多条数据分别分布至具有相同分区编号的第一分区中;
37、过滤器生成模块,用于将每个第一分区中的数据划分为满足数据量阈值的多个文件组,并基于每个文件组生成对应的布隆过滤器,所述布隆过滤器用于定位对应的文件组。
38、第三方面,本技术实施例提供了一种数据湖的分区设备,所述设备包括存储器以及处理器:
39、所述存储器,用于存储计算机程序,并将所述计算机程序传输给所述处理器;
40、所述处理器,用于执行所述计算机程序,以使所述设备执行前述第一方面所述的数据湖的分区方法。
41、第四方面,本技术实施例提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,当所述计算机程序被运行时,运行所述计算机程序的设备实现前述第一方面所述的数据湖的分区方法。
42、相较于现有技术,本技术实施例具有以下有益效果:
43、本技术实施例提供了一种数据湖的分区方法及相关装置,在该方法中,数据湖包括多个第一分区,且多个第一分区分别具有不同的分区编号,从数据表的多个字段中确定第一分区键字段;数据表包括多条数据,每条数据包括多个字段分别对应的值;基于每条数据中第一分区键字段的值和第一分区的个数进行哈希处理,得到每条数据对应的分区编号;将分区编号字段添加至数据表,并将每条数据对应的分区编号作为分区编号字段的值添加至数据表,得到添加后的多条数据;基于添加后的多条数据分别对应的分区编号,将添加后的多条数据分别分布至具有相同分区编号的第一分区中;将每个第一分区中的数据划分为满足数据量阈值的多个文件组,并基于每个文件组生成对应的布隆过滤器,布隆过滤器用于定位对应的文件组。
44、由于本技术是直接将第一分区和多条具有对应分区编号的数据绑定,在绑定后,才对第一分区中的数据划分得到文件组,因此文件组的数量不受第一分区的个数的限制,同时,布隆过滤器是在划分得到文件组后才生成的,因此其数量也不受限制,可以随着文件组数量的变化而变化,且划分得到的多个文件组是满足数据量阈值的,表明本技术划分得到的文件组的数量可以适应性变化,既不会导致文件组存入的数据过多的问题,也不会导致文件组数量过多的问题。因此,本技术提供的数据湖的分区方法能够在通过分区编号和布隆过滤器实现文件组定位的同时,避免影响数据湖的性能。
- 还没有人留言评论。精彩留言会获得点赞!