基于知识图谱的生成式大模型建模方法、系统及设备与流程
本发明涉及智能医疗,更具体地,涉及一种基于知识图谱的生成式大模型建模方法、系统、设备及计算机可读存储介质。
背景技术:
1、随着信息技术和医学领域的迅速发展,数据量不断增加,带来了新的机会和挑战。医学数据,如患者病例、检测报告和医学图像等,涉及多个部门和机构,如医院、疗养机构。医学领域产生的大量非结构化的数据蕴含着宝贵的医学知识和临床经验,但其非结构化的特性使得传统的数据处理方法难以高效提取和利用这些信息。随着深度学习和大数据技术的发展,特别是bert等预训练模型在语言理解方面的突破,为解决这些问题提供了新的技术手段。通过从大量非结构化的医学文本中提取关键信息,并利用这些信息构建知识图谱,能够将零散、非结构化的数据转化为结构化和半结构化的形式,便于进一步的分析和应用。
2、申请号为cn202211216862.9的中国发明专利提出一种多维知识图谱的构建方法、装置、设备及产品,应用于数据处理技术领域。该方法包括:获取至少两个生物医学数据库,所述生物医学数据库存储有不同实体和连接所述不同实体的实体关系;将所述至少两个生物医学数据库中的同类实体进行标准化,得到至少两个标准化实体;基于所述至少两个生物医学数据库中的不同实体之间的实体关系,重构不同所述标准化实体之间的实体关系;基于所述至少两个标准化实体和不同所述标准化实体之间的实体关系,构建所述多维知识图谱。该方法能够在整合数据库的基础上,以基因类实体为主,构建一个多维度的知识图谱。
3、申请号为cn202310961100.x的中国发明专利提出一种融合知识与患者表示的诊断推荐系统,包括知识图谱构建模块、知识表示学习模块和诊断推荐模块;本发明利用医学知识图谱对患者数据和医学知识进行联结,可以更全面、准确地表达医学知识和患者数据之间的关系;本发明关联了患者就诊的时序数据与医学知识图谱,构建患者信息图谱,利用规则学习算法对患者信息图谱进行剪枝,缩小知识表示学习域,关联数据形成患者信息序列,可以更好地利用患者历史数据,提高诊断推荐准确性;本发明提出了一种计算细粒度语义单元相似性的语义关联方法,可以更准确地对医学实体进行对齐;本发明引入了基于无监督卷积神经网络构建的患者序列表示学习模型,进一步提高诊断推荐的准确性。
技术实现思路
1、本发明提出一种基于知识图谱的生成式大模型建模方法,通过构建知识图谱的方式进行图数据库的构建,进一步地,通过图数据训练生成式大模型。具体包括:
2、一种基于知识图谱的生成式大模型建模方法,所述方法包括:
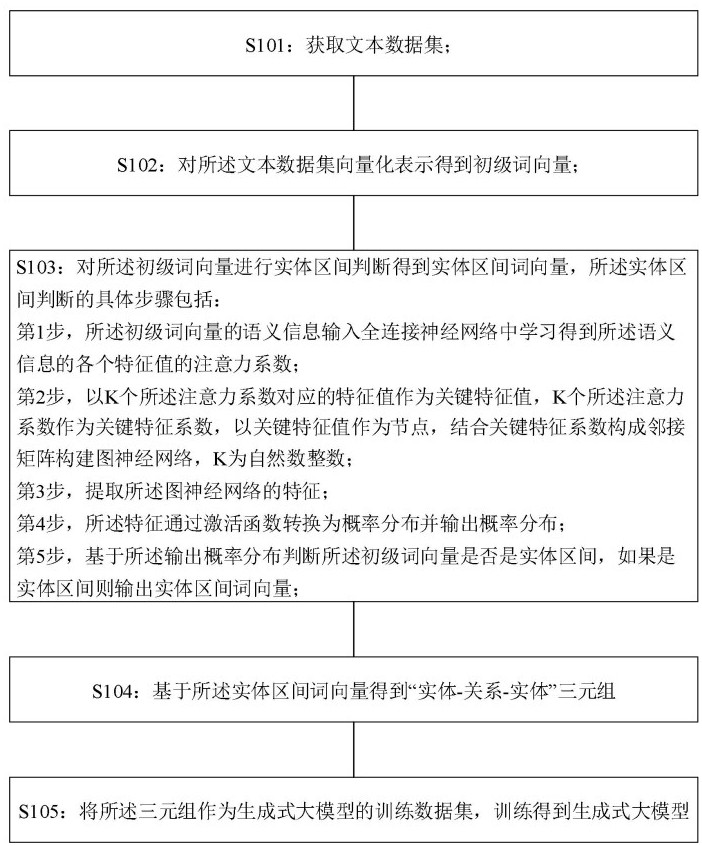
3、获取文本数据集;
4、对所述文本数据集向量化表示得到初级词向量;
5、对所述初级词向量进行实体区间判断得到实体区间词向量,所述实体区间判断的具体步骤包括:
6、第1步,所述初级词向量的语义信息输入全连接神经网络中学习得到所述语义信息的各个特征值的注意力系数;
7、第2步,以k个所述注意力系数对应的特征值作为关键特征值,k个所述注意力系数作为关键特征系数,以关键特征值作为节点,结合关键特征系数构成邻接矩阵构建图神经网络,k为自然数整数;
8、第3步,提取所述图神经网络的特征;
9、第4步,所述特征通过激活函数转换为概率分布并输出概率分布;
10、第5步,基于所述输出概率分布判断所述初级词向量是否是实体区间,如果是实体区间则输出实体区间词向量;
11、基于所述实体区间词向量得到“实体-关系-实体”三元组;
12、将所述三元组作为生成式大模型的训练数据集,训练得到生成式大模型。
13、进一步,所述提取所述图神经网络的特征的步骤包括:
14、第1步,用所述关键特征值初始化所述图神经网络中t=0时刻所有节点的隐状态;
15、第2步,在任意t时刻,所述节点k的隐状态基于节点k的聚合特征向量和节点k在t-1时刻的隐状态更新,所述节点k的聚合特征向量根据节点k的所有邻居节点的t-1时刻的隐状态得到,其中k表示所有所述k个节点中的任意一个;
16、第3步,当所述节点k与其邻居节点k’高度相关时,所述图神经网络会在二者之间进行信息传递,反之则抑制信息传递;
17、重复第2步至第3步,直至达到停止条件后输出最终的节点隐状态作为提取后的特征,所述停止条件指损失函数收敛或达到预设的停止条件。
18、进一步,所述注意力系数的计算公式为:
19、
20、其中,为注意力系数,为第个特征值的权重系数,为求和函数,exp()为指数函数。
21、进一步,所述节点k的聚合特征向量的计算公式如下:
22、
23、其中,表示节点k在t时刻的聚合特征向量,表示已知节点'的条件下节点的出现概率,表示已知节点的条件下节点'的出现概率,表示节点'在t-1时刻的隐状态。
24、进一步,节点k的隐状态的计算公式如下:
25、
26、
27、
28、
29、其中,表示sigmoid函数,是双曲正切函数,代表元素乘法运算,表示更新门,表示重置门,表示候选隐藏状态,表示最后要计算的节点k的隐状态,是待学习的网络参数。
30、进一步,所述“实体-关系-实体”三元组是基于实体区间词向量得到的,方法包括:用命名实体识别模型来识别所述实体区间词向量的实体类型,然后利用深度学习模型或机器学习模型来识别所述实体区间词向量之间的关系。
31、进一步,所述“实体-关系-实体”三元组是基于实体区间词向量得到的,方法包括:使用多任务联合学习框架同时进行实体类型识别和关系抽取,所述多任务联合学习框架包括共享层和任务特定层,所述实体区间词向量输入共享层提取特征,所述特征输入任务特定层训练后输出结果,在所述任务特定层定义实体类型识别任务和关系抽取任务各自的损失函数,所述任务特定层联合两个任务的所述损失函数作为训练的总损失函数,通过优化所述总损失函数来优化模型参数,所述任务特定层输出实体类型识别和关系抽取的结果得到所述“实体-关系-实体”三元组。
32、进一步,所述向量化表示方法包括下列方法中的一种或几种:词袋模型、tf-idf、word2vec、glove、fasttext、预训练的bert。
33、进一步,所述预训练的bert的关键组成部分包括:transformer架构、双向上下文表示、以及预训练模块,所述文本数据集输入transformer架构得到包含注意力信息的词向量,所述包含注意力信息的词向量输入所述上下文表示模块中通过mlm任务结合了上下文信息后输入所述预训练模块训练,所述预训练模块包括mlm任务和nsp任务,通过所述预训练得到语言的深层次特征后输出所述初级词向量。
34、进一步,所述生成式大模型包括下列模型中的一种或几种:transformer、gpt、bert、t5、xlnet、roberta、albert、dall-e、wavegan、biggan、unilm、clip。
35、进一步,所述生成式大模型的训练步骤包括:
36、第1步,将所述三元组进行格式化得到文本字符串;
37、第2步,将所述文本字符串通过分词工具分解为词元区间;
38、第3步,将所述词元区间通过向量化表示转换为词向量,同时将所述词向量进行填充或截断以匹配最大序列长度得到格式化词向量;
39、第4步,初始化所述生成式大模型的参数,将所述格式化词向量输入所述生成式大模型,计算损失函数并根据损失函数选择优化器训练优化所述参数,直至所述损失函数收敛或达到预设的停止轮数。
40、一种基于知识图谱的生成式大模型建模系统,包括:
41、获取模块:用于获取文本数据集;
42、向量化表示模块:用于对所述文本数据集向量化表示得到初级词向量,所述初级词向量包括词向量的区间;
43、实体区间判断模块:用于对所述初级词向量进行实体区间判断得到实体区间词向量,所述实体区间判断的具体步骤包括:
44、第1步,所述初级词向量的语义信息输入全连接神经网络中学习得到所述语义信息的各个特征值的注意力系数;
45、第2步,以k个所述注意力系数对应的特征值作为关键特征值,k个所述注意力系数作为关键特征系数,以关键特征值作为节点,结合关键特征系数构成邻接矩阵构建图神经网络,k为自然数整数;
46、第3步,提取所述图神经网络的特征;
47、第4步,所述特征通过激活函数转换为概率分布并输出概率分布;
48、第5步,基于所述输出概率分布判断所述初级词向量是否是实体区间,如果是实体区间则输出实体区间词向量;
49、三元组构建模块:用于基于所述实体区间词向量得到“实体-关系-实体”三元组;
50、训练模块:用于将所述三元组作为生成式大模型的训练数据集,训练得到生成式大模型。
51、一种基于知识图谱的生成式大模型建模设备,包括:存储器和处理器;所述存储器用于存储程序指令;所述处理器用于调用程序指令,当程序指令被执行时实现任意一项所述的基于知识图谱的生成式大模型建模方法。
52、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时任意一项所述的基于知识图谱的生成式大模型建模方法。
53、本技术的优势:
54、1、提出了一种创新性的实体区间识别方法,以在文本中确定实体的起始和结束边界。
55、2、采用特征关联图神经网络来处理语义信息特征,包括注意力系数的计算、关键特征值的选择,以及利用这些关键特征值构建的图神经网络。
56、3、采用特征关联循环更新机制来通过图传递信息并学习上下文的关联特征。
- 还没有人留言评论。精彩留言会获得点赞!