数据中台数据血缘图谱构建方法与流程
本发明涉及数据分析,尤其为数据中台数据血缘图谱构建方法。
背景技术:
1、随着企业信息化和数字化的深入推进,企业数据呈现爆炸式增长,为了充分发挥数据的价值,需要对海量数据进行有效的管理和利用,数据血缘关系图谱作为数据管理的重要手段,可以帮助企业更好地管理和利用数据。现有技术中,对于复杂的数据血缘关系识别和标注还存在一定的困难。特别是在面对多源异构数据、动态变化的数据链路和数据血缘关系时,准确识别和标注数据血缘关系的难度较大。鉴于以上问题,本发明提出数据中台数据血缘图谱构建方法以解决上述问题。
技术实现思路
1、本发明的主要目的在于提供数据中台数据血缘图谱构建方法,以解决相关技术中提出的问题。
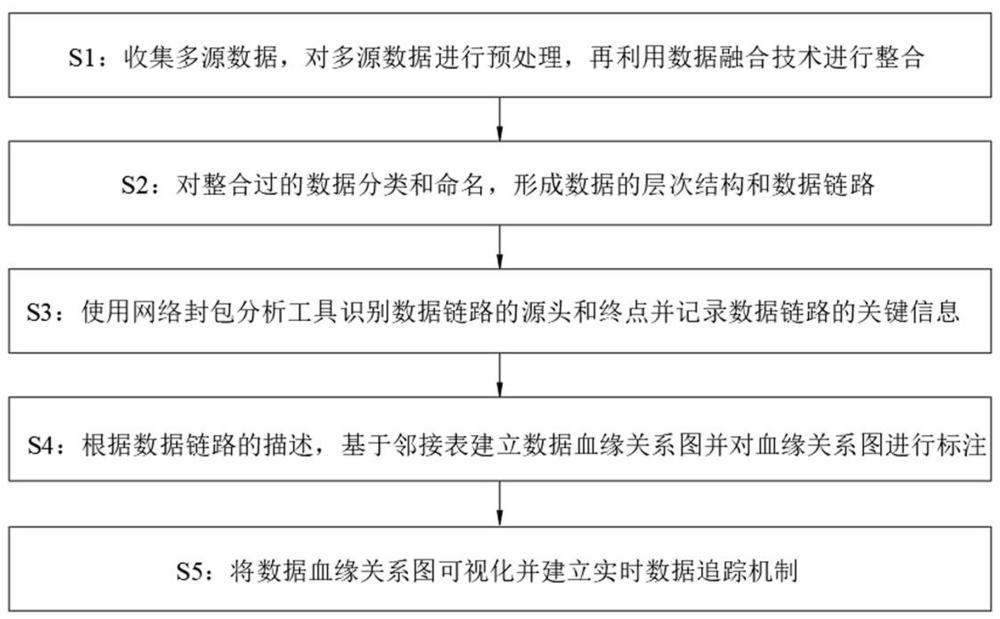
2、为了实现上述目的,根据本发明的一个方面,提供了数据中台数据血缘图谱构建方法,包括如下步骤:
3、s1:收集多源数据,对多源数据进行预处理,再利用数据融合技术进行整合;
4、s2:对整合过的数据分类和命名,形成数据的层次结构和数据链路;
5、s3:使用网络封包分析工具识别数据链路的源头和终点并记录数据链路的关键信息;
6、s4:根据数据链路的描述,基于邻接表建立数据血缘关系图并对血缘关系图进行标注;
7、s5:将数据血缘关系图可视化并建立实时数据追踪机制。
8、进一步地,s1中,多源数据包括数据库中的数据、文件系统数据和api接收的数据,对多源数据进行预处理为数据清洗,处理数据的缺失值和重复值。
9、进一步地,s1中,利用数据融合技术进行整合的具体步骤如下:
10、s11:对预处理后的数据进行多样性判断;
11、s12:经多样性判断后的数据进行标准化处理;
12、s13:计算标准化后数据的准特征矩阵;
13、s14:对准特征矩阵进行特征分解,得到特征值;
14、s15:对准特征矩阵进行正交投影,将原始数据投影到新的空间。
15、进一步地,利用数据融合技术进行整合的计算如下:
16、多样性判断公式为:
17、;
18、;
19、;
20、;
21、其中,d和k权重,x和y是两种数据源,x和y分别是数据源x和数据源y中的数据,为数据源x的多样性,为x和y的互信息,为数据源x的左邻接熵,为数据源y的左邻接熵,为x、y的联合分布,和分别是x和y的边缘分布;
22、经多样性判断后的数据进行标准化处理,计算公式为:
23、;
24、其中,s是一个的矩阵,m是样本数量,n是特征数量,s是标准化后的矩阵,x是原始矩阵;为原始样本均值,为原始样本标准差;
25、标准化后数据的准特征矩阵,计算公式为:
26、;
27、其中,是一个的准特征矩阵,m是样本数量,n是特征数量,e为期望值,为s的均值向量,为特征为n的值,为样本为m的值;
28、准特征矩阵中的对角元素值为:
29、;
30、其中,是第i行第j列的元素,是特征j这组样本的均值,m是样本数量,n是特征数量,为对角线元素的值;
31、准特征对角线上的特征值为:
32、;
33、;
34、其中,为对角线上的均值,为准特征矩阵中的对角线特征值;
35、每个元素的特征值为:
36、;
37、其中,是第i行第j列的元素。
38、进一步地,s2中,数据层次结构和数据链路形成的具体步骤如下:
39、s21:依据业务属性和数据类型对整合后的数据分类;
40、s22:确定数据的命名格式、命名规则以及命名标准,再对数据进行命名;
41、s23:根据分类命名的结果,形成数据与数据之间的层次结构;
42、s24:根据数据与数据之间的层次结构,将数据之间建立连接并传输数据,形成数据链路。
43、进一步地,s3中,网络封包分析工具的使用步骤如下:
44、s31:网络封包分析工具会通过网络接口卡捕获流经的网络封包;
45、s32:监听特定的网络接口并捕获所有经过该接口的数据包;
46、s33:对捕获的数据包进行解码;
47、s34:通过显示过滤器过滤掉没用的数据包,只显示关键信息。
48、进一步地,s4中,建立数据血缘关系图的具体步骤为:
49、s41:从数据库中提取关键信息;
50、s42:根据提取的关键信息,设计网络拓扑结构图,再使用邻接表建立数据血缘关系的图谱结构;
51、s43:对图谱结构中的每个节点和边使用自动化标注工具和半自动化工具结合进行标注;
52、s44:将标注好的数据血缘关系图保存到数据库中。
53、进一步地,s42中,邻接表的表达式为:
54、网络拓扑结构图表示为:
55、;
56、其中,v是节点的集合,e是边的集合,,,n为节点的总数;
57、邻接表表示为:
58、;
59、其中,k为与相邻节点的总数,为的邻接节点;
60、数据血缘关系图的邻接表表示为:
61、;
62、;
63、其中,为数据表。
64、进一步地,在数据血缘关系图的邻接表中引入增量更新,避免整个邻接表进行重新构建,与节点a有关的新增关系为:
65、;
66、将变化合集与原始邻接表合并,更新后的邻接表为:
67、;
68、其中,为数据表,表示数据集a与数据集b存在数据流向,数据集a与数据集d存在数据流向。
69、进一步地,邻接表的构建过程如下:
70、s421:创建空的数组存储邻接表;
71、s422:从数据中提取邻接信息,确定每个节点的入度数量;
72、s423:将每个节点的入度信息添加到其对应的邻接列表中;
73、s424:再遍历数据链路中的所有节点,将所有节点入度的路径长度存储在邻接表中;
74、s425:从邻接列表中提取出邻接表。
75、与现有技术相比,本发明具有以下有益效果:
76、本发明通过整合来自不同数据源的数据,实现数据链路的全覆盖和无缝连接,利用数据融合技术,将多源数据进行整合和优化,提高数据血缘关系图谱构建的全面性和准确性。基于邻接表建立数据血缘关系,只需要维护每个节点的入度信息,以及边的信息即可,能够高效地进行图的遍历,查找和分析,使得在处理大规模图时能够保持高效和快速。
技术特征:
1.数据中台数据血缘图谱构建方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的数据中台数据血缘图谱构建方法,其特征在于,s1中,多源数据包括数据库中的数据、文件系统数据和api接收的数据,对多源数据进行预处理为数据清洗,处理数据的缺失值和重复值。
3.根据权利要求2所述的数据中台数据血缘图谱构建方法,其特征在于,s1中,利用数据融合技术进行整合的具体步骤如下:
4.根据权利要求3所述的数据中台数据血缘图谱构建方法,其特征在于,利用数据融合技术进行整合的计算如下:
5.根据权利要求1所述的数据中台数据血缘图谱构建方法,其特征在于,s2中,数据层次结构和数据链路形成的具体步骤如下:
6.根据权利要求1所述的数据中台数据血缘图谱构建方法,其特征在于,s3中,网络封包分析工具的使用步骤如下:
7.根据权利要求1所述的数据中台数据血缘图谱构建方法,其特征在于,s4中,建立数据血缘关系图的具体步骤为:
8.根据权利要求7所述的数据中台数据血缘图谱构建方法,其特征在于,s42中,邻接表的表达式为:
9.根据权利要求8所述的数据中台数据血缘图谱构建方法,其特征在于,在数据血缘关系图的邻接表中引入增量更新,避免整个邻接表进行重新构建,与节点a有关的新增关系为:
10.根据权利要求9所述的数据中台数据血缘图谱构建方法,其特征在于,邻接表的构建过程如下:
技术总结
本发明涉及数据分析技术领域,具体涉及数据中台数据血缘图谱构建方法,包括如下步骤:收集多源数据,对多源数据进行预处理,再利用数据融合技术进行整合;对整合过的数据分类和命名,形成数据的层次结构和数据链路;使用网络封包分析工具识别数据链路的源头和终点并记录数据链路的关键信息;根据数据链路的描述,基于邻接表建立数据血缘关系图并对血缘关系图进行标注;将数据血缘关系图可视化并建立实时数据追踪机制。本发明利用数据融合技术,将多源数据进行整合和优化,提高数据血缘关系图谱构建的全面性和准确性。基于邻接表建立数据血缘关系,能够高效地进行图的遍历,查找和分析,使得在处理大规模图时能够保持高效和快速。
技术研发人员:田山,张志龙,孙小龙
受保护的技术使用者:山东再起数据科技有限公司
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!