一种基于半监督学习的混合集成电路组件缺陷检测方法
本发明涉及混合集成电路,特别涉及一种基于半监督学习的混合集成电路组件缺陷检测方法。
背景技术:
1、混合集成电路是在基片上用成膜方法制作厚膜或薄膜元件及其互连线,并在同一基片上将分立的半导体芯片、单片集成电路或微型元件混合组装,再外加封装而成。近年来半导体技术迅速发展,混合集成电路正向着高密度、多样化和小型化方向快速发展,其集成度和精密程度越来越高,随着混合集成电路的大规模生产,不可避免会出现因生产缺陷导致的残次品。为了提高混合集成电路的生产质量,及时检测发现生产的电路中存在的键合丝缺陷和元件焊接缺陷等质量问题,研究针对混合集成电路的工艺缺陷检测技术十分必要。
2、目前,针对混合集成电路组件缺陷检测的主要方法有:人工目检和基于机器视觉的自动光学检测技术(aoi)。人工目检方式存在主观臆断、效率低下以及稳定性差等问题,难以满足如今混合集成电路大规模生产的检测需求。基于机器视觉的aoi检测技术,通过光学传感器、图像处理算法和计算机技术的有机结合,显著提升了检测速度和精确度。在aoi系统中,检测算法的设计是影响检测效果的关键因素。近年来,深度学习的目标检测技术的快速发展为缺陷检测算法带来了新的突破,这种基于深度学习的设计方法具有多项优势,包括高精度、快速检测速度、良好的扩展性和鲁棒性。
3、在基于深度学习的目标检测技术中,基于半监督学习模型进行缺陷检测算法的设计可以解决以下技术问题。首先,半监督学习方法可以在使用标记数据的同时,也能够利用未标记数据来提高模型的准确性,从而使得模型鲁棒性和泛化能力更强。其次,基于半监督学习的模型可以更好地处理大规模数据集,并且可以有效地避免标记样本不足或噪声样本的影响。最后,由于基于半监督学习的模型能够利用未标记数据,因此可以减少人工标记的工作量,降低成本,同时也避免了标记错误带来的负面影响。因此,设计针对混合集成电路组件缺陷检测的半监督学习算法具有重要的意义。
4、设计基于半监督学习的缺陷检测算法时,检测器和伪标签筛选算法设计对模型检测性能影响较大,现阶段基于半监督学习的缺陷检测算法主要存在以下问题及缺陷:
5、(1)目前半监督缺陷检测算法的检测器设计大多是基于两阶段的目标检测器(如faster-rcnn)进行设计的,使用单阶段有锚框检测器(yolo系列)的较少。基于单阶段有锚框检测器具有高召回率、高精度和训练速度快的优点,因此有必要基于单阶段锚框检测器设计半监督缺陷检测算法,以提高缺陷检测算法的检测性能。
6、(2)yolo检测器中特征融合金字塔结构在进行特征融合时非相邻层级之间语义差距较大,尤其是底部和顶部特征,这会导致非相邻特征层之间特征融合效果差。在实际检测任务的多尺度特征提取中也会导致特征信息丢失或退化问题。
7、(3)半监督目标检测的核心问题是如何给无标签数据准确的分配伪标签。伪标签筛选阈值设置不合理,会导致较多错误的伪标签混入正确标签一起训练,影响训练精度。
8、(4)在实际缺陷检测任务中,正常样本数量远多于缺陷样本数量,各类缺陷样本数量也不相同,在进行模型训练时,正负样本的不均衡会影响训练效果。
技术实现思路
1、本发明要解决现有技术中的技术问题,提供一种基于半监督学习的混合集成电路组件缺陷检测方法。
2、为了解决上述技术问题,本发明的技术方案具体如下:
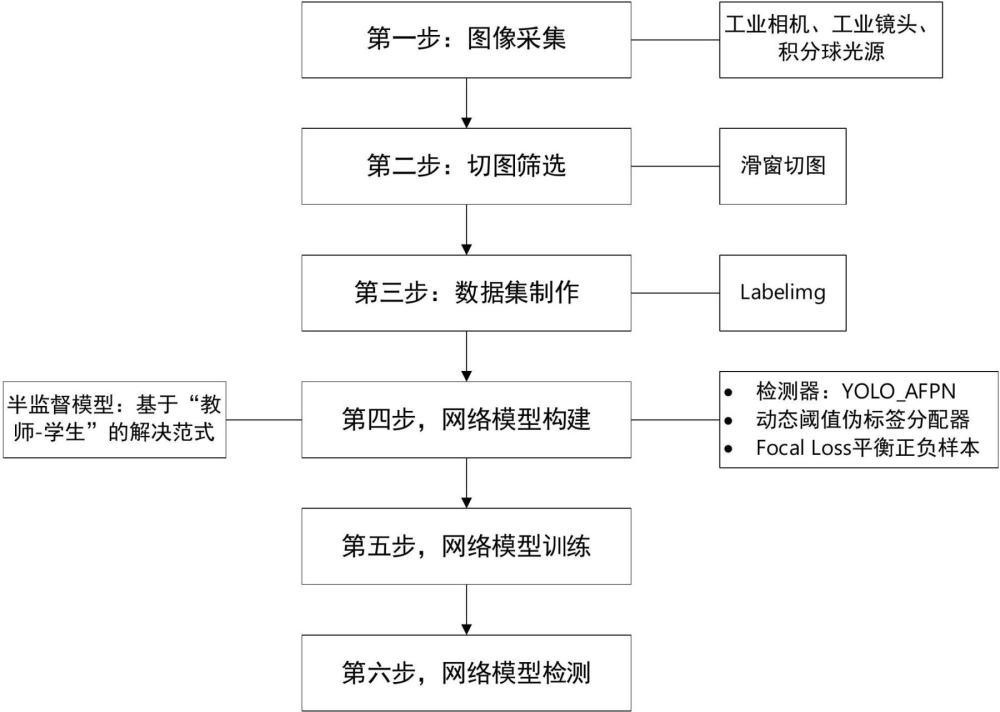
3、一种基于半监督学习的混合集成电路组件缺陷检测方法,包括以下步骤:
4、第一步:图像采集,使用高分辨工业相机采集完整混合集成电路板图像;
5、第二步:切图筛选,先进行图像切割,然后筛选待测目标完整的图像进行后续数据集的制作;
6、第三步:数据集制作,对切图筛选后的混合集成电路图像分两部分进行处理,一部分进行缺陷信息及位置坐标的标注,制作用于半监督模型有监督训练的数据集,另一部分不做标注,用作半监督模型无监督训练的数据集;
7、第四步:网络模型构建,基于半监督检测模型,构建用于混合集成电路组件缺陷检测的网络模型;
8、第五步:网络模型训练,设置网络训练权重和训练参数,训练半监督学习网络;
9、第六步:网络模型检测,将待测混合集成电路图像输入到训练好的网络模型中进行缺陷检测,并输出检测结果;
10、所述第二步中,图像切割的具体步骤为:
11、设置一个指定大小的窗口,对高分辨率图像进行滑动切分,然后通过对切分的子图进行筛选,保留完整待测信息的图像;
12、所述第三步中的有监督训练数据集包含:目标检测所必须的图像标注信息;存储图像的文件夹、与标签相对应的图像名称和图像的绝对路径;标签图像的大小和通道的信息;以及图像中标签对象的类别信息,标注框的起点和终点位置;
13、第四步中构建的网络模型,使用渐进式特征金字塔结构afpn替换yolov5结构中原有的pafpn金字塔结构,首先融合相邻的低层级特征层,然后再渐进式的将更高层级的特征加入融合过程,以减小非相邻层级之间较大的语义差距,加强特征融合效果;
14、采用自适应特征融合模块为不同层级的特征分配不同的空间权重,增强关键层级的重要性,减少来自不同目标的矛盾信息的影响。
15、在上述技术方案中,第四步中的网络模型是采用基于“教师-学生”的解决范式,运用教师网络对无标注数据生成的伪标签来指导学生网络学到全量数据的分布,同时学生网络又会以指数滑动平均(ema)的方式来更新教师网络的参数,教师网络和学生网络互相学习,共同提高模型整体的检测性能。
16、在上述技术方案中,第四步具体为:
17、首先,将有标签数据通过学生模型进行常规全监督训练,训练之后计算得到有标签数据样本的损失;
18、然后,无标签数据进行弱增强和强增强两种数据增强,将弱增强之后的无标签数据输入到教师模型,将强增强之后的无标签数据输入到学生模型中进行后续训练处理,学生模型通过ema方式更新教师模型参数,教师模型对无标签数据进行推理和预测,nms处理后得到初步伪标签;
19、ema计算公式如下:
20、;
21、其中,表示权重参数,表示第次更新的所用参数的指数移动平均数,表示第次更新得到的参数;
22、最后,通过设计伪标签筛选算法筛选高质量伪标签,并将生成的高质量伪标签输入到学生模型中进行训练,使模型学到更加丰富的数据特征,增强模型的检测性能。
23、在上述技术方案中,第四步中构建网络模型时的动态阈值伪标签过滤方法,包括步骤:
24、伪标签过滤器使用负阈值和动态正阈值将伪标签分别分成可靠标签,不确定标签和错误标签,其中的可靠标签和不确定标签分别采用不同的损失计算方式参与训练,可靠标签转化为硬标签与有标签数据一起进行有监督训练,不确定标签转化为软标签进行训练以达到挖掘潜在正样本的目的,错误标签不参与训练;
25、伪标签过滤器与之划分效果为:
26、;
27、其中,表示处伪标签的分数,负阈值在训练中固定为0.2,正阈值采用自适应动态阈值计算方法进行计算。
28、在上述技术方案中,第四步中构建网络模型时正阈值采用自适应动态阈值计算方法,根据模型训练期间的学习状态和预测情况,自适应地调整置信度阈值;
29、基于ema计算方法以及伪标签筛选思路,具体的,自适应动态阈值计算分为自适应全局阈值计算和自适应局部阈值计算两个部分,模型先估计一个全局阈值作为模型置信度的ema,然后通过局部特定类别的阈值来调整全局阈值;
30、综合自适应全局阈值和局部阈值得到最终的自适应动态阈值:
31、;
32、 ;
33、其中,表示自适应全局阈值,表示自适应局部阈值,表示最大值归一化,为类别数,表示无标签数据经过弱增强后,模型生成伪标签的综合置信度分数。
34、在上述技术方案中,第四步中构建网络模型时,采用focal loss计算标定框的分类损失和置信度损失,采用融合focal loss计算思想的focal-eiou计算标定框的回归损失,focal loss通过权重参数的调整来控制正负样本对总的损失计算的共享权重,更好地解决正负样本不均衡的问题,其具体的计算公式为:
35、 ;
36、其中,为置信度分数,为调整因子,为权重参数,表示样本标签,表示该样本为正样本,表示该样本为负样本。
37、在上述技术方案中,第五步中,采用如下参数进行网络模型训练:batch_size为16,学习率为0.001,nms_conf置信度阈值:0.3,nms_iou阈值:0.65,burn_in_epoch为150,总epoch为300,优化器使用sgd,数据集中训练集和验证集比例划分为9:1,训练集中有标签数据占30%。
38、一种计算机可读存储介质,存储有计算机程序,所述计算机程序具体为基于半监督学习的混合集成电路组件缺陷检测程序,该计算机程序由处理器执行时,实现上述的基于半监督学习的混合集成电路缺陷检测方法的第二步至第六步。
39、本发明具有以下有益效果:
40、本发明的基于半监督学习的混合集成电路组件缺陷检测方法,以混合集成电路的组件相关缺陷检测为目标,采用基于半监督学习的目标检测技术,有效提升了混合集成电路组件相关缺陷检测的准确性、及时性和检测的效率,提高了混合集成电路的品质和生产效率,为实际工程应用提供一定程度的指导价值。
41、本发明采用基于半监督学习的检测器进行混合集成电路组件的相关缺陷检测,可以在有标注数据较少的情况下,充分利用无标签数据,显著提高模型的泛化能力和检测性能。
42、本发明所用半监督模型的检测器部分,创新性的采用yolo_afpn网络结构,有效避免非相邻层级之间较大的语义差距,促进高层级和底层级之间的语义信息融合,防止特征信息在传输和交互过程中出现丢失或退化从而影响网络特征的学习和提取,增强特征空间融合能力,提高检测精度和检测效率。
43、本发明中的伪标签分配器优化,采用动态阈值对伪标签进行划分,提高无标签数据利用率和生成伪标签的准确率。
44、本发明中的损失函数优化,将交叉熵损失改进为focal loss,缓解数据不平衡对模型性能造成的影响,提高模型的检测精度和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!