人脸视频生成方法、装置及电子设备与流程
本公开涉及人工智能,尤其涉及深度学习、大数据、计算机视觉、语音技术等,尤其涉及一种人脸视频生成方法、装置及电子设备。
背景技术:
1、目前的人脸口型驱动方案主要为,获取人脸口型驱动模型;获取目标对象的人脸图像,以及音频或者视频;将音频或者视频,以及目标对象的人脸图像,输入人脸口型驱动模型,获取人脸口型驱动模型输出的目标对象的人脸视频。
2、上述方案中,人脸口型驱动模型为通用的人脸口型驱动模型,输出的人脸视频,为通用风格下目标对象的人脸视频,难以体现不同目标对象的个性化口型风格,导致生成的人脸视频的准确度低。
技术实现思路
1、本公开提供了一种人脸视频生成方法、装置及电子设备。
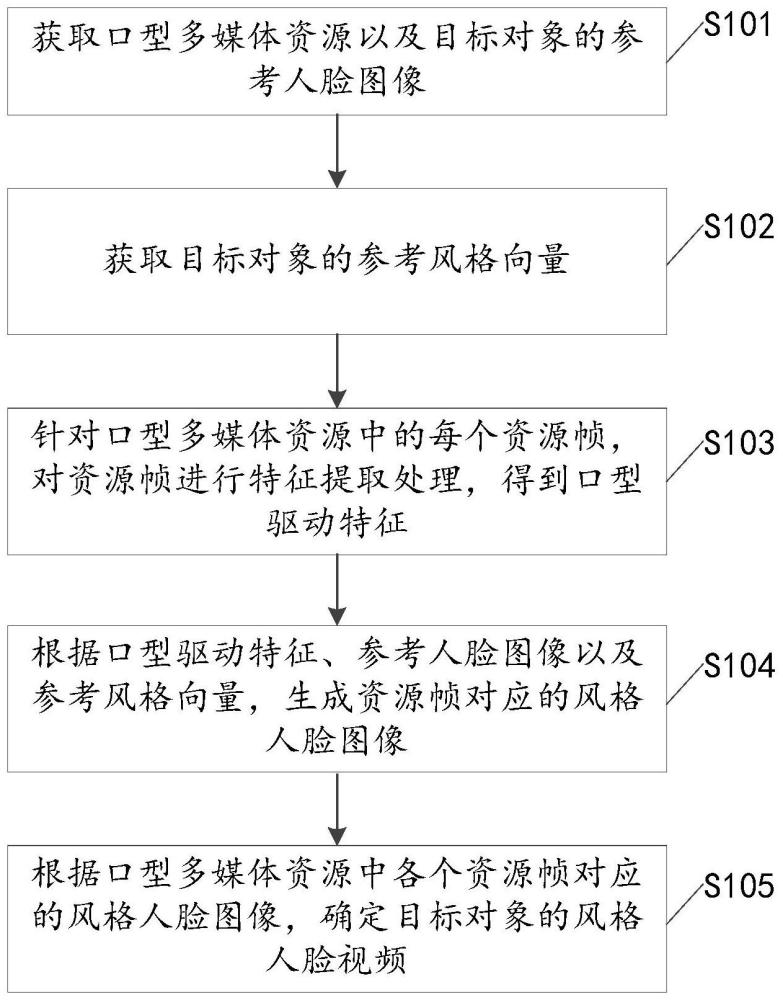
2、根据本公开的一方面,提供了一种人脸视频生成方法,所述方法包括:获取口型多媒体资源以及目标对象的参考人脸图像;获取所述目标对象的参考风格向量;针对所述口型多媒体资源中的每个资源帧,对所述资源帧进行特征提取处理,得到口型驱动特征;根据所述口型驱动特征、所述参考人脸图像以及所述参考风格向量,生成所述资源帧对应的风格人脸图像;根据所述口型多媒体资源中各个资源帧对应的风格人脸图像,确定所述目标对象的风格人脸视频。
3、根据本公开的另一方面,提供了一种人脸口型驱动模型的训练方法,所述方法包括:获取经过预训练的人脸口型驱动模型以及编码网络;所述人脸口型驱动模型包括,依次连接的特征提取网络和人脸驱动网络;获取样本口型多媒体资源中各个样本资源帧的样本口型驱动特征、样本参考人脸图像、以及样本风格人脸视频;所述样本口型多媒体资源中的样本资源帧,与所述样本风格人脸视频中的样本视频帧一一对应;针对所述样本口型多媒体资源中的每个样本资源帧,将所述样本资源帧对应的样本口型驱动特征以及样本视频帧,输入初始的编码网络,获取所述编码网络输出的预测风格向量;将所述预测风格向量、所述样本口型驱动特征以及所述样本参考人脸图像输入所述人脸驱动网络,获取所述人脸驱动网络输出的预测风格人脸图像;根据所述预测风格向量所属的分布、高斯分布、所述预测风格人脸图像以及所述样本资源帧对应的样本视频帧,对所述编码网络以及所述人脸口型驱动模型中的所述人脸驱动网络进行参数调整处理,以获取训练好的人脸口型驱动模型。
4、根据本公开的另一方面,提供了一种人脸视频生成装置,所述装置包括:第一获取模块,用于获取口型多媒体资源以及目标对象的参考人脸图像;第二获取模块,用于获取所述目标对象的参考风格向量;特征提取模块,用于针对所述口型多媒体资源中的每个资源帧,对所述资源帧进行特征提取处理,得到口型驱动特征;生成模块,用于根据所述口型驱动特征、所述参考人脸图像以及所述参考风格向量,生成所述资源帧对应的风格人脸图像;确定模块,用于根据所述口型多媒体资源中各个资源帧对应的风格人脸图像,确定所述目标对象的风格人脸视频。
5、根据本公开的另一方面,提供了一种人脸口型驱动模型的训练装置,所述装置包括:第一获取模块,用于获取经过预训练的人脸口型驱动模型以及编码网络;所述人脸口型驱动模型包括,依次连接的特征提取网络和人脸驱动网络;第二获取模块,用于获取样本口型多媒体资源中各个样本资源帧的样本口型驱动特征、样本参考人脸图像、以及样本风格人脸视频;所述样本口型多媒体资源中的样本资源帧,与所述样本风格人脸视频中的样本视频帧一一对应;第三获取模块,用于针对所述样本口型多媒体资源中的每个样本资源帧,将所述样本资源帧对应的样本口型驱动特征以及样本视频帧,输入初始的编码网络,获取所述编码网络输出的预测风格向量;第四获取模块,用于将所述预测风格向量、所述样本口型驱动特征以及所述样本参考人脸图像输入所述人脸驱动网络,获取所述人脸驱动网络输出的预测风格人脸图像;训练模块,用于根据所述预测风格向量所属的分布、高斯分布、所述预测风格人脸图像以及所述样本资源帧对应的样本视频帧,对所述编码网络以及所述人脸口型驱动模型中的所述人脸驱动网络进行参数调整处理,以获取训练好的人脸口型驱动模型。
6、根据本公开的另一方面,提供了一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本公开上述提出的人脸视频生成方法;或者执行本公开上述提出的人脸口型驱动模型的训练方法。
7、根据本公开的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,所述计算机指令用于使计算机执行本公开上述提出的人脸视频生成方法;或者执行本公开上述提出的人脸口型驱动模型的训练方法。
8、根据本公开的另一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现本公开上述提出的人脸视频生成方法的步骤;或者实现本公开上述提出的人脸口型驱动模型的训练方法。
9、应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种人脸视频生成方法,所述方法包括:
2.根据权利要求1所述的方法,其中,所述参考风格向量符合高斯分布;所述获取所述目标对象的参考风格向量,包括:
3.根据权利要求2所述的方法,其中,所述根据所述样本资源帧、所述样本参考人脸图像以及所述样本视频帧,从各个候选高斯分布中选择目标高斯分布,包括:
4.根据权利要求1所述的方法,其中,所述根据所述口型驱动特征、所述参考人脸图像以及所述参考风格向量,生成所述资源帧对应的风格人脸图像,包括:
5.根据权利要求1所述的方法,其中,所述口型多媒体资源为,口型音频或者口型视频。
6.根据权利要求1所述的方法,其中,所述口型多媒体资源,为非目标对象的口型多媒体资源;或者,为合成得到的口型多媒体资源。
7.一种人脸口型驱动模型的训练方法,所述方法包括:
8.根据权利要求7所述的方法,其中,所述获取样本口型多媒体资源中各个样本资源帧的样本口型驱动特征、样本参考人脸图像、以及样本风格人脸视频,包括:
9.根据权利要求8所述的方法,其中,所述获取所述样本口型多媒体资源、所述样本参考人脸图像、以及所述样本风格人脸视频,包括:
10.根据权利要求7所述的方法,其中,所述根据所述预测风格向量所属的分布、高斯分布、所述预测风格人脸图像以及所述样本资源帧对应的样本视频帧,对所述编码网络以及所述人脸口型驱动模型中的所述人脸驱动网络进行参数调整处理,以获取训练好的人脸口型驱动模型,包括:
11.一种人脸视频生成装置,所述装置包括:
12.根据权利要求11所述的装置,其中,所述参考风格向量符合高斯分布;所述第二获取模块包括,第一获取单元、第二获取单元、选择单元和确定单元;
13.根据权利要求12所述的装置,其中,所述选择单元具体用于,
14.根据权利要求11所述的装置,其中,所述生成模块具体用于,
15.根据权利要求11所述的装置,其中,所述口型多媒体资源为,口型音频或者口型视频。
16.根据权利要求11所述的装置,其中,所述口型多媒体资源,为非目标对象的口型多媒体资源;或者,为合成得到的口型多媒体资源。
17.一种人脸口型驱动模型的训练装置,所述装置包括:
18.根据权利要求17所述的装置,其中,所述第二获取模块包括,第一获取单元和第二获取单元;
19.根据权利要求18所述的装置,其中,所述第一获取单元具体用于,
20.根据权利要求17所述的装置,其中,所述训练模块具体用于,
21.一种电子设备,包括:
22.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行根据权利要求1至6中任一项所述的人脸视频生成方法;或者,执行根据权利要求7至10中任一项所述的人脸口型驱动模型的训练方法。
23.一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现根据权利要求1至6中任一项所述的人脸视频生成方法;或者,实现根据权利要求7至10中任一项所述的人脸口型驱动模型的训练方法。
技术总结
本公开提供了人脸视频生成方法、装置及电子设备,涉及人工智能技术领域,尤其涉及深度学习、大数据、计算机视觉、语音技术等技术领域。具体实现方案为:获取口型多媒体资源以及目标对象的参考人脸图像;获取目标对象的参考风格向量;针对口型多媒体资源中的每个资源帧,对资源帧进行特征提取处理,得到口型驱动特征;根据口型驱动特征、参考人脸图像以及参考风格向量,生成资源帧对应的风格人脸图像;进而确定目标对象的风格人脸视频;其中,目标对象的参考风格向量,能够体现目标对象的个性化口型风格,确保生成的风格人脸视频能够体现目标对象的个性化口型风格,从而提高生成的风格人脸视频的准确度。
技术研发人员:范锡睿,赵亚飞,陈毅,杜宗财,王志强
受保护的技术使用者:北京百度网讯科技有限公司
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!