一种混洗融合矩阵乘指令实现方法及系统
本发明涉及处理器,特别是涉及一种混洗融合矩阵乘指令实现方法及系统。
背景技术:
1、gemm(general matr ix mu lt ip ly,通用矩阵乘法)是一种重要的科学计算内核,在科学计算、数值方程求解等方面有着广泛的应用。近年以来随着人工智能的热潮,神经网络模型迅速发展,网络规模呈指数级增长,对算力的要求已经远远超过摩尔定律预测的硬件性能增长速度。在以cnn(convol utional neural network,卷积神经网络)为代表的诸多神经网络模型中,gemm覆盖了其中大部分的计算过程。因此如何提高gemm效率成为了研究的热点。
2、gemm作为一种数据排列规整,近似流式访存的计算内核,在通用处理器中通常采用simd(single i nstruction mu ltip le data,单指令多数据)的方式进行计算,向量处理部件(vector processing unit,vpu)中并列的多个处理单元(processing element,pe)根据指令各自从向量访存部件(array memory,am)中加载源操作数矩阵的一行(列)或若干行(列),由各自的mac(mu ltip ly accumu late,乘累加)单元分别计算出目标矩阵中的一个或若干个值,重复该过程直到计算完整个目标矩阵。由于数据只在am和pe的局部寄存器之间流动,因此其计算方式的优点是指令简单,流程清晰,可以在一定程度上高度并行化。但缺点也非常明显,操作数据复用率低,计算访存比不高。
3、因此,提供一种数据复用率高、计算密度高的混洗融合矩阵乘指令实现方法及系统是本领域技术人员亟待解决的问题。
技术实现思路
1、本发明的目的在于提供一种混洗融合矩阵乘指令实现方法,该方法逻辑清晰,安全、有效、可靠且操作简便,能有效提高数据复用率以及计算密度。
2、基于以上目的,本发明提供的技术方案如下:
3、一种混洗融合矩阵乘指令实现方法,包括如下步骤:
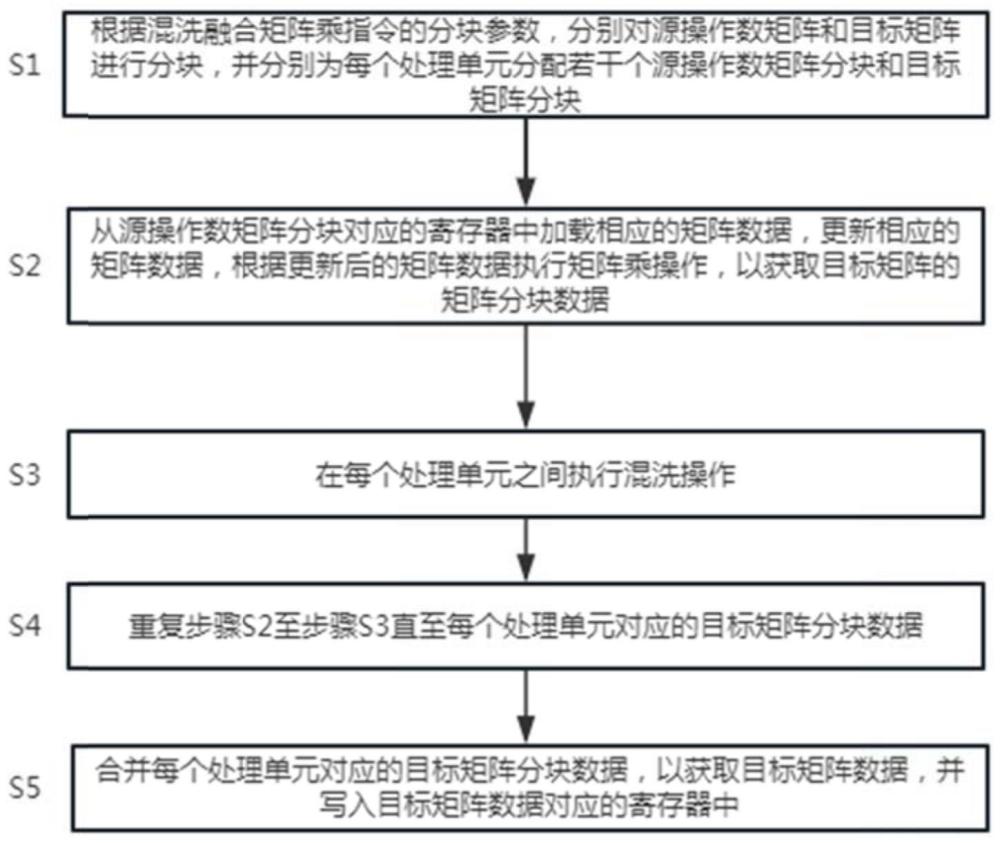
4、s1.根据混洗融合矩阵乘指令的分块参数,分别对源操作数矩阵和目标矩阵进行分块,并分别为每个处理单元分配若干个源操作数矩阵分块和目标矩阵分块;
5、s2.从所述源操作数矩阵分块对应的寄存器中加载相应的矩阵数据,更新相应的矩阵数据,根据所述更新后的矩阵数据执行矩阵乘操作,以获取目标矩阵的矩阵分块数据;
6、s3.在每个所述处理单元之间执行混洗操作;
7、s4.重复步骤s2至步骤s3直至每个所述处理单元对应的目标矩阵分块数据;
8、s5.合并所述每个所述处理单元对应的目标矩阵分块数据,以获取目标矩阵数据,并写入所述目标矩阵数据对应的寄存器中。
9、优选地,所述分块参数包括:数据精度、矩阵规模、处理单元并行度、寄存器资源和数据带宽。
10、优选地,所述分别为每个处理单元分配若干个源操作数矩阵分块和目标矩阵分块中的分配规则是基于协同性、交互性、局部性、负载均衡而设置的。
11、优选地,所述步骤s2中加载相应的矩阵数据,包括如下步骤:
12、根据源操作数矩阵分块的个数、所述数据精度和处理单元的编号,获取加载矩阵数据的初始位置和跨步长度;
13、根据所述加载矩阵数据的初始位置和跨步长度,获取加载寄存器地址偏移量;
14、当加载矩阵数据的顺序为行优先时,根据所述加载寄存器地址偏移量按寄存器编号顺序依次读取数据;
15、当加载矩阵数据的顺序为列优先时,根据所述数据精度和所述矩阵规模,按加载矩阵数据的的跨步长度跨步读取数据。
16、优选地,所述步骤s2,包括如下步骤:
17、根据所述源操作数矩阵分块分别从第一寄存器中加载第一源操作矩阵数据,从第二寄存器中加载第二源操作矩阵数据;
18、从外部存储器中读取新的矩阵数据,分别对所述第一源操作矩阵数据和第二源操作矩阵数据进行更新,以获取更新后的第一源操作矩阵数据和更新后的第二源操作矩阵数据;
19、将所述更新后的第一源操作矩阵数据和所述更新后的第二源操作矩阵数据执行矩阵乘操作,得到所述目标矩阵的矩阵分块数据。
20、优选地,所述步骤s3,具体为:
21、获取所述第二寄存器中的每个所述处理单元中的更新后的第二源操作数据;
22、按照预设预设混洗方式重新排列后,重新输出至所述第二寄存器中。
23、优选地,所述步骤s3还包括:
24、若第i个处理单元的源操作数矩阵分块和第i个处理单元的目标矩阵分块不匹配,则获取第k个处理单元的源操作数矩阵分块为所述第i个处理单元的源操作数矩阵分块更新,以使得所述第i个处理单元更新后的源操作数矩阵分块与所述第i个处理单元的目标矩阵分块匹配。
25、优选地,所述步骤s5中写入目标矩阵数据,包括如下步骤:
26、根据目标矩阵分块的个数、所述数据精度和处理单元的编号,获取写入目标矩阵数据的初始位置和跨步长度;
27、根据所述写入目标矩阵数据的初始位置和跨步长度,获取写入寄存器的地址偏移量;
28、当写入目标矩阵数据的顺序为行优先时,根据所述写入寄存器的地址偏移量按寄存器编号顺序依次写入数据;
29、当写入目标矩阵数据的顺序为列优先时,根据所述数据精度和所述矩阵规模,按写入目标矩阵数据的跨步长度跨步写入数据。
30、一种混洗融合矩阵乘指令实现系统,包括:
31、分块模块,用于根据混洗融合矩阵乘指令的分块参数,分别对源操作数矩阵和目标矩阵进行分块,并分别为每个处理单元分配若干个源操作数矩阵分块和目标矩阵分块;
32、目标矩阵分块模块,用于从所述源操作数矩阵分块对应的寄存器中加载相应的矩阵数据,更新相应的矩阵数据,根据所述更新后的矩阵数据执行矩阵乘操作,以获取目标矩阵的矩阵分块数据;
33、混洗模块,用于在每个所述处理单元之间执行混洗操作;
34、所述目标矩阵分块模块,还用于获取每个所述处理单元对应的目标矩阵分块数据;
35、目标矩阵模块,用于合并所述每个所述处理单元对应的目标矩阵分块数据,以获取目标矩阵数据,并写入所述目标矩阵数据对应的寄存器中。
36、本发明提供的混洗融合矩阵乘指令实现方法,是通过根据预设的混洗融合矩阵乘指令中的分块参数,分别对源操作数矩阵和目标操作数矩阵进行分块,并且分别为每个处理单元分配多个源操作数矩阵分块和目标矩阵分块;从每个处理单元中的源操作数矩阵分块对应的寄存器中加载相应的矩阵数据,并对相应的矩阵数据进行更新,通过将更新后的矩阵数据执行矩阵乘操作,从而获得目标矩阵的矩阵分块数据;通过在每个处理单元之间执行混洗操作;重复上述步骤,得到每个处理单元对应的目标矩阵分块数据;合并每个处理单元对应的目标矩阵分块数据,从而得到目标矩阵数据,并写入目标矩阵数据对应的寄存器中。
37、相比于现有技术,本发明可以无需使用者了解处理器的硬件结构和参数,通过混洗计算融合即可实现矩阵乘计算,提高了数据复用性,减少了访存需求,有利于隐藏访存延迟,提高了计算密度。
38、本发明还提供了一种混洗融合矩阵乘指令实现系统,由于该系统与该方法属于相同的技术构思,解决相同的技术问题,理应具有相同的有益效果,在此不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!