基于模型结构自动化分析的深度神经网络分布式训练方法
本发明属于神经网络,特别涉及基于模型结构自动化分析的深度神经网络分布式训练方法。
背景技术:
1、近年来,随着产业信息化和互联网的发展,深度学习技术也得到了充分发展,其凭借强大的特征提取与归纳能力,被广泛应用于金融、医学、推荐系统、分子动力学等领域,改变了人们的生活方式,提高了生产效率。随着数据规模的不断增大,深度学习模型越来越复杂,如gpt-3和chatgpt网络模型拥有约1750亿个参数,上述模型训练所需的内存大小最多需要数千gb。通常可以用更多的数据样本来训练更大的模型的方式提高模型精度。但是计算加速设备(如gpu)的内存容量增长速度远小于神经网络训练内存需求的增长速度,单个设备的计算和存储能力有限,难以承受大规模数据集和庞大模型的训练。
2、而如今的深度学习服务器中一般包含多张深度神经网络训练卡(gpu/npu)。因此,如何利用分布式训练技术将深度学习模型分切至多个设备上训练,以提高模型训练性能已经成为了当前深度学习领域关注的热点。
3、当前模型的分布式训练主要依赖于专家经验,其需要开发人员深入了解神经网络模型和训练设备的结构特征,并基于这些特征设计模型的分布式训练策略。然而,随着模型规模和设备集群规模的不断增大,策略的搜索空间呈指数级增长,基于专家经验的方法很难在短时间内设计出性能较优的并行策略。
4、为了提升模型并行策略性能以及策略搜索的效率,学术界和工业界开始研究模型的自动化分析方法。模型自动分析方法通过对模型结构以及设备拓扑信息的提取,借助搜索算法对神经网络模型进行自动分析,以此简化模型并行策略的设计过程,实现模型分布式训练性能的提升。目前,主流的模型自动并行方法分为基于机器学习和基于图算法的两种。其中,基于机器学习的方法需要进行参数的迭代更新以及大量的计算,使得策略搜索时间较长;而基于图算法的方法通常采用动态规划、最短路径等算法进行搜索,其往往存在策略执行性能不足,策略负载不均衡等问题。当前上述方法往往需要综合考虑算子结构、执行性能、设备拓扑结构等多方面特征,并在真实环境下采集算子的数据,利用策略性能模拟器指导策略的搜索,使得搜索过程十分复杂,仅适用于中小型模型,并不适用于近年来十分流行的大模型。
技术实现思路
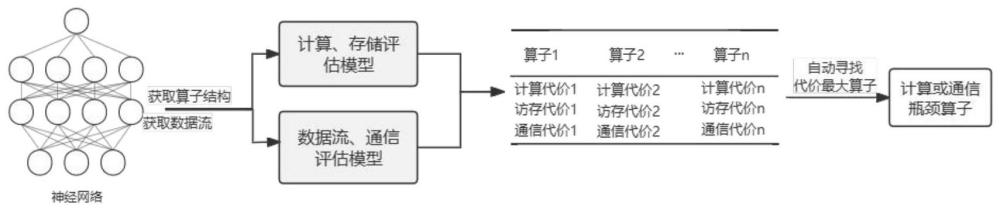
1、本发明针对深度神经网络结构复杂、分析困难导致其分布式并行训练策略设计与实现困难的问题,设计了一种基于模型结构自动化分析的深度神经网络分布式训练方法,以高效准确评估深度学习模型结构及其计算量,支撑模型分布式并行训练策略的设计与实现。首先,本发明分析深度神经网络模型结构算子,根据其计算、存储、参数等特征,对不同类型算子进行计算、存储评估建模,根据神经网络的计算或存储特征,将神经网络中的算子归纳为访存密集型算子、计算密集型算子。通过该评估模型,根据算子的输入、输出来自动推导算子性能。其次,根据深度神经网络计算图,分析算子数据流特征,结合算子参数、通信模式等构建算子间数据流或通信评估模型。通过该评估模型,实现算子通信性能自动推导。最后,根据模型计算图及算子特征,基于计算、存储评估模型和数据流、通信评估模型,实现模型结构自动化分析,自动模型结构中算子进行参数密集和计算密集识别,并寻找最耗时或通信量最大的网络层或算子(该网络层或算子是整体模型结构计算或通信瓶颈),以便进行分布式训练,提升训练效率和降低训练成本。
2、本发明提供一种基于模型结构自动化分析的深度神经网络分布式训练方法,步骤如下:
3、步骤1:分析深度神经网络模型结构算子,根据其计算、存储、参数等特征,对不同类型算子进行计算、存储评估建模,根据神经网络的计算或存储特征,将神经网络中的算子归纳为访存密集型算子、计算密集型算子。通过计算、存储评估模型,根据算子的输入、输出自动推导算子计算代价。
4、子步骤1.1:扫描深度学习框架对模型生成的计算图,并定义一个有向无环图g(o,e)记录,节点表示算子:每个节点表示一个单独的神经网络算子,例如矩阵乘matmul、卷积conv算子等。有向边表示数据依赖关系:有向边用来表示算子之间的数据依赖关系。如果算子b的输出是算子a的输入,那么从节点a到节点b的有向边表示数据从a流向b。这些有向边还可以用于表示算子的执行顺序。并以json格式记录计算图中算子结构以及数据流信息。
5、子步骤1.2:每个算子都由其输入张量和输出张量构成数据流,结合算子及其数据流构建计算、访存评估模型,该评估模型能够自动扫描计算图中所有算子,根据算子类型及其数据流(输入张量大小、输入张量数据类型),计算其访存代价。访存代价主要与算子权重参数和中间结果相关,所以带有参数权重的算子的存储代价用以下公式表示:
6、
7、其中t表示有参数权重算子的数量,w1,w2,...,wh表示参数权重大小,sizeof(wtype)表示参数的数据类型为wtype的字节数大小,,wtype包括fp16、fp32等,k表示输出张量的数量,h1,h2,...,hh表示张量h维大小,sizeof(htype)表示获取数据的类型为htype的字节数大小,htype包括fp16、fp32等。
8、子步骤1.3:算子计算代价是指张量计算所产生的开销,其体现了张量转化的过程。因此计算代价costcompute基于算子的输入张量和输出张量计算得到,使用以下公式表达:
9、
10、其中sin和sout分别表示算子的输入和输出张量总和,当输入张量和输出张量之间的变化较大时,表示算子的计算过程也复杂则算子的计算代价也越大。其中r表示代价转换率,由实现分析所得。
11、神经网络算子主要分为两类:访存密集型和计算密集型。访存密集型是指算子的时间绝大部分都花费为访存上,如concat、add、relu、maxpooling等算子。计算密集型是指计算复杂度较大其绝大部分时间都花费在计算上的算子,这类算子往往是负责一些复杂矩阵运算如conv、fc、matmul、lstm等算子。通过计算和比较算子的costmemory和costcompute,可以将算子成功归类。
12、步骤2:根据子步骤1.1中得到的深度神经网络计算图,分析算子数据流特征,结合算子参数、通信模式等构建算子间数据流、通信评估模型,通过数据流、通信评估模型,实现算子通信性能自动推导。
13、子步骤2.1:常见的集群间通信模式有allreduce、allgather、alltoall等等,例如allreduce通信是将各个进程中的数据汇总求和之后再分发,每个进展有k数据量,每个进程就会通信k数据量,而allgather通信中每个进程会从所有进程中收集数据,每个进程就会通信k×n数据量。因此需要从计算图中获取通信算子的通信模式。本专利中通过分析计算图中数据边来推断通信模式。例如allreduce通常涉及多个节点之间的同步和归约操作,而allgather则涉及节点之间的数据收集。通过扫描计算图,对算子的输入输出关系进行判断,分析它与相邻节点之间的操作属于哪类通信模式,并将判断结果添加进有向无环图g(o,e)中。
14、子步骤2.2:根据算子数据流信息,结合算子参数、通信模式,对算子进行算子问数据流或通信评估建模分析,自动推导算子通信代价。算子之间的通信代价与传输张量密切相关,通信代价可以利用算子输出张量与其数据类型得到,使用以下公式表达:
15、
16、其中表示输出张量的数量,sizeof(htype)表示张量数据类型为的字节数大小,常见的htype有fp16和fp32,t(ctype)表示通信方式为ctype时产生通信量倍数,例如allgather通信中每个进程都需要从其他进程收集数据,t(allgather)=进程数。本方法将算子输出张量的大小作为通信代价。
17、步骤3:根据子步骤1.1中得到的深度神经网络计算图,基于计算、存储评估模型和数据流、通信评估模型,实现模型结构自动化分析,自动分析模型结构中算子进行参数密集和计算密集识别,并寻找最耗时或通信量最大的网络层或算子(该网络层或算子是整体模型结构计算或通信瓶颈),以便进行分布式训练。
18、子步骤3.1:根据上述计算、存储评估建模和算子间数据流、通信评估模型的建模分析,得到每个算子的计算代价costcompute、访存代价costmemory和通信代价costcommunicate,并根据上述三个代价自动从计算图中寻找代价最大的k个算子。这些算子又往往是整体模型结构中计算或通信的瓶颈,将计算代价大的算子切分放置到多个设备上,将通信代价大的算子聚拢放置在同一设备上。或者将本专利分析计算图自动推导出的计算代价、访存代价、通信代价输入到模型并行切分策略中,能帮助该策略更有效更快地切分模型,无需算法工程师profiling模型训练手动寻找模型结构瓶颈。一种有效的模型切分放置方法能更好地利用计算资源、存储资源、通信资源,可以更快地训练神经网络模型和训练更大规模的复杂神经网络模型。
19、本发明具有的有益效果是:
20、自动分析深度神经网络模型结构算子,根据其计算、存储、参数等特征,对不同类型算子进行计算、存储评估建模,根据神经网络的计算或存储特征,将神经网络中的算子归纳为访存密集型算子、计算密集型算子。通过该评估模型,根据算子的输入、输出来自动推导算子性能。
21、根据深度神经网络计算图,自动分析算子数据流特征,结合算子参数、通信模式等构建算子问数据流或通信评估模型。通过该评估模型,实现算子通信性能自动推导。
22、通过上述2个评估模型的自动化评估建模分析,寻找最耗时或通信量最大的网络层或算子(该网络层或算子是整体模型结构计算或通信瓶颈),帮助ai工程师设计并行策略,以便进行分布式训练,提升训练效率和降低训练成本。
- 还没有人留言评论。精彩留言会获得点赞!