基于强化学习的仿真足球机器人决策优化方法
本发明涉及仿真足球机器人运动,尤其涉及一种基于强化学习的仿真足球机器人决策优化方法。
背景技术:
1、仿真足球机器人是一种融合了多种技术领域的复杂系统,这些仿真足球机器人需要具备智能的决策能力,以便在仿真足球比赛中执行如传球、进攻、防守等一系列任务。
2、传统的仿真足球机器人决策方法通常是基于预先定义的规则和启发式方法,但在这种决策方法下,决策精度低、适应性差,并且存在着难以升级、优化的问题。
3、故亟需一种可以提高仿真足球机器人的决策精度、增强仿真足球机器人决策适应性、易于升级且易于优化的仿真足球机器人决策方法。
技术实现思路
1、本技术实施例的目的在于提供一种基于强化学习的仿真足球机器人决策优化方法,用于解决现有技术的仿真足球机器人决策方法存在决策精度低、适应性差、难以升级和优化的技术问题。
2、为实现上述目的,本技术实施例采用如下的技术方案:
3、一种基于强化学习的仿真足球机器人决策优化方法,所述方法包括以下步骤:
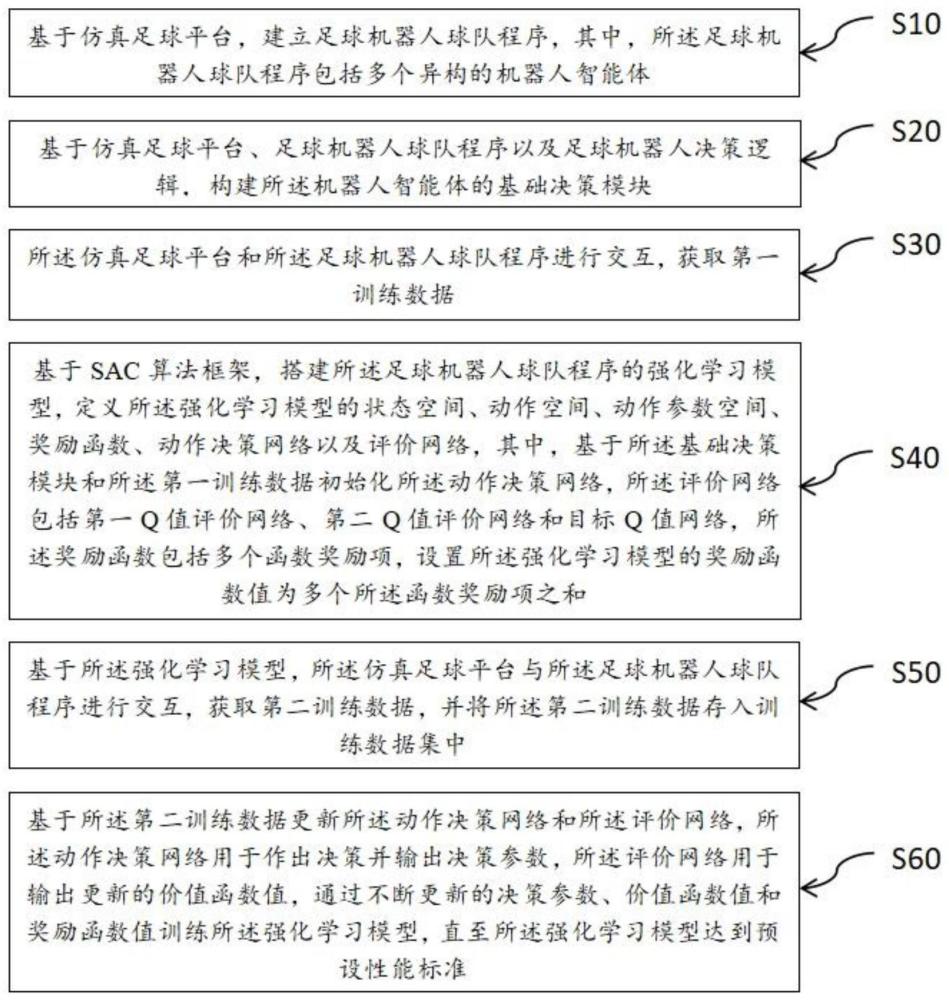
4、基于仿真足球平台,建立足球机器人球队程序,其中,所述足球机器人球队程序包括多个异构的机器人智能体;
5、基于仿真足球平台、足球机器人球队程序以及足球机器人决策逻辑,构建所述机器人智能体的基础决策模块;
6、所述仿真足球平台和所述足球机器人球队程序进行交互,获取第一训练数据;
7、基于sac算法框架,搭建所述足球机器人球队程序的强化学习模型,定义所述强化学习模型的状态空间、动作空间、动作参数空间、奖励函数、动作决策网络以及评价网络,其中,基于所述基础决策模块和所述第一训练数据初始化所述动作决策网络,所述评价网络包括第一q值评价网络、第二q值评价网络和目标q值网络,所述奖励函数包括多个函数奖励项,设置所述强化学习模型的奖励函数值为多个所述函数奖励项之和;
8、基于所述强化学习模型,所述仿真足球平台与所述足球机器人球队程序进行交互,获取第二训练数据,并将所述第二训练数据存入训练数据集中;
9、基于所述第二训练数据更新所述动作决策网络和所述评价网络,所述动作决策网络用于作出决策并输出决策参数,所述评价网络用于输出更新的价值函数值,通过不断更新的决策参数、价值函数值和奖励函数值训练所述强化学习模型,直至所述强化学习模型达到预设性能标准。
10、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,所述动作决策网络包括多分类模型和回归网络模型;
11、所述多分类模型用于实现所述状态空间到所述动作空间的映射,其中,所述动作空间内的原子动作至少包括移动、转身、截球、带球、射门、传球;
12、所述回归网络模型用于实现所述状态空间到所述动作参数空间的映射,其中,所述动作参数包括动作的力度和动作方向与所述机器人智能体身体朝向的夹角。
13、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,基于所述第二训练数据和监督学习方法,实现所述状态空间到所述动作空间和所述动作参数空间的映射。
14、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,基于核密度负例学习方法对每一所述第二训练数据中的每一动作空间和动作参数空间中的参数进行多分类操作,并基于分类结果,对所述机器人智能体的动作特征进行归纳,筛选出符合当前所述动作决策网络的特征的所述第二训练数据,将符合当前所述动作决策网络特征的所述第二训练数据设为正样本数据,扩大所述正样本数据在所述训练数据集中的占比,基于深度确定性策略梯度方法更新所述强化学习模型。
15、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,在所述动作决策网络作出决策并输出决策参数时,所述动作决策网络做出的决策与随机探索策略作出的决策相结合,输出第一决策参数,基于所述第一决策参数、价值函数值以及所述奖励函数值更新所述强化学习模型。
16、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,基于经验回放机制,在所述动作决策网络每一次作出决策后存储本次输入所述强化学习模型的所述第二训练数据,并将本次输入的所述第二训练数据设为经验数据,将所述经验数据存入经验池中,在所述第二训练数据训练所述强化学习模型的过程中,随机从所述经验池中抽取所述经验数据以训练所述强化学习模型。
17、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,所述状态空间至少包括所述机器人智能体的位置参数、球的位置参数、球的速度参数以及所述机器人智能体的速度和方向参数。
18、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,基于所述第一q值评价网络或所述第二q值评价网络与所述目标q值网络更新所述动作决策网络,其中,所述第一q值评价网络和所述第二q值评价网络的输入为当前的所述第二训练数据中的环境参数和当前所述动作决策网络的输出;
19、当所述第一q值评价网络输出的q值小于所述第二q值评价网络输出的q值时,基于所述第一q值评价网络与所述目标q值网络更新所述动作决策网络;
20、当所述第二q值评价网络输出的q值小于所述第一q值评价网络输出的q值时,基于所述第二q值评价网络与所述目标q值网络更新所述动作决策网络;
21、所述动作决策网络损失函数如下:
22、
23、其中,πφ(at|st)表示所述动作决策网络在状态空间st做出动作at的分数输出,qθ(st,at)表示第一q值评价网络或第二q值评价网络在状态空间st做出动作at的分数输出,α表示所述动作决策网络更新的超参数。
24、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,所述第一q值评价网络和所述第二q值评价网络均通过最小化自身的损失进行网络参数的更新;
25、所述第一q值评价网络和所述第二q值评价网络的损失函数均如下:
26、
27、其中,qθ(st,at)表示第一q值评价网络或第二q值评价网络在当前状态空间st做出动作at的分数输出,rt表示正则化熵项,表示目标q值网络在下一状态空间st+1做出动作at+1的分数输出,πφ(at+1|st+1)表示所述动作决策网络在下一状态空间st+1做出动作at+1的分数输出,α1表示所述第一q值评价网络或第二q值评价网络更新的超参数。
28、在本技术实施例所述的基于强化学习的仿真足球机器人决策优化方法中,基于所述第一q值评价网络或所述第二q值评价网络和所述动作决策网络,更新所述目标q值网络,其中,所述第一q值评价网络和所述第二q值评价网络的输入为当前的所述第二训练数据中的环境参数和当前所述动作决策网络的输出;
29、当所述第一q值评价网络输出的q值小于所述第二q值评价网络输出的q值时,基于所述第一q值评价网络和所述动作决策网络更新所述目标q值网络;
30、当所述第二q值评价网络输出的q值小于所述第一q值评价网络输出的q值时,基于所述第二q值评价网络和所述动作决策网络更新所述目标q值网络;
31、所述目标q值网络的损失函数如下:
32、
33、其中,所述表示目标q值网络在下一状态空间st+1做出动作at+1的分数输出,πφ(at+1|st+1)表示所述动作决策网络在下一状态空间st+1做出动作at+1的分数输出,α2表示目标q值网络更新的超参数。
34、与现有技术相比,本技术实施例具有如下有益效果:
35、由上述技术方案可知,本技术实施例提供的基于强化学习的仿真足球机器人决策优化方法,通过仿真足球平台,建立包括多个异构足球机器人智能体的足球机器人球队程序,并给予仿真足球平台、足球机器人球队程序和足球机器人决策逻辑,构件机器人智能体的基础决策模块,仿真足球平台和足球机器人球队程序进行交互,获取第一训练数据,基于sac算法框架,搭建足球机器人球队程序的强化学习模型,并定义强化学习模型的状态空间、动作空间、动作参数空间、奖励函数、动作决策网络以及评价网络,并基于基础决策模块和第一训练数据初始化动作决策网络,评价网络包括第一q值评价网络、第二q值评价网络和目标q值网络,奖励函数包括多个函数奖励项,设置强化学习模型的奖励函数值为多个函数奖励项之和,基于强化学习模型,仿真足球平台和足球机器人球队程序进行交互,获取第二训练数据,并将第二训练数据存入训练数据集中,基于第二训练数据更新动作决策网络和评价网络,动作决策网络用于作出决策并输出决策参数,评价网络用于输出更新的价值函数值,通过不断更新的决策参数、价值函数值和奖励函数值训练强化学习模型,直至强化学习模型达到预设性能标准,提高了足球机器人智能体的决策精度、适应能力,并简化了足球机器人智能体的决策方法的升级、优化难度,解决了现有技术中的仿真足球机器人决策方法存在决策精度低、适应性差、难以升级和优化的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!