专业领域的生成式问答方法及电子设备与流程
本发明涉及数据处理,尤其涉及一种专业领域的生成式问答方法及电子设备。
背景技术:
1、随着自然语言处理技术的快速发展,大规模语言模型在理解人类意图和快速响应等方面都取得了较为突出的表现。为不断推进大语言模型在实际场景中的落地,本地知识库被逐渐应用到生成式问答中。
2、然而,当前基于本地知识库的生成式问答,往往针对单一信息进行索引,搜索出与问题相关的答案,然而,这并不适用于某些领域下相对复杂的多知识点聚合场景,导致知识库检索问题相关信息的召回率精度较低,生成式问答结果往往答非所问。
3、有鉴于此,特提出本发明。
技术实现思路
1、为了解决上述技术问题,本发明提供了一种专业领域的生成式问答方法及电子设备,解决现有技术生成式问答结果精度差的问题。
2、本发明实施例提供了一种专业领域的生成式问答方法,该方法包括:
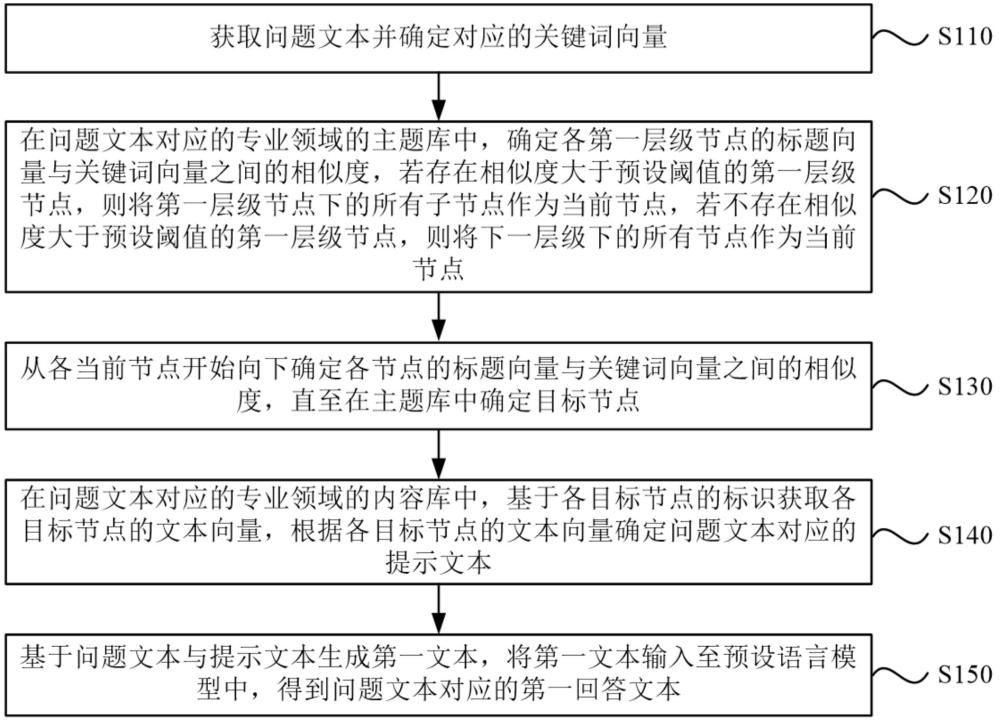
3、获取问题文本并确定对应的关键词向量;
4、在所述问题文本对应的专业领域的主题库中,确定各第一层级节点的标题向量与所述关键词向量之间的相似度,若存在相似度大于预设阈值的第一层级节点,则将所述第一层级节点下的所有子节点作为当前节点,若不存在相似度大于预设阈值的第一层级节点,则将下一层级下的所有节点作为当前节点;
5、从各当前节点开始向下确定各节点的标题向量与所述关键词向量之间的相似度,直至在所述主题库中确定目标节点;
6、在所述问题文本对应的专业领域的内容库中,基于各目标节点的标识获取各目标节点的文本向量,根据各目标节点的文本向量确定所述问题文本对应的提示文本;
7、基于所述问题文本与所述提示文本生成第一文本,将所述第一文本输入至预设语言模型中,得到所述问题文本对应的第一回答文本。
8、本发明实施例提供了一种电子设备,所述电子设备包括:
9、处理器和存储器;
10、所述处理器通过调用所述存储器存储的程序或指令,用于执行任一实施例所述的专业领域的生成式问答方法的步骤。
11、本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质存储程序或指令,所述程序或指令使计算机执行任一实施例所述的专业领域的生成式问答方法的步骤。
12、本发明实施例具有以下技术效果:
13、通过获取问题文本并确定对应的关键词向量,在对应的专业领域的主题库中,确定各第一层级节点的标题向量与关键词向量之间的相似度,若存在相似度大于预设阈值的第一层级节点,则将其下的所有子节点作为当前节点,否则,将下一层级下的所有节点作为当前节点,进而从各当前节点开始向下确定各节点的标题向量与关键词向量之间的相似度,直至在主题库中确定目标节点,进而在对应的专业领域的内容库中,基于各目标节点的标识获取文本向量,得到问题文本对应的提示文本,结合提示文本与问题文本生成第一文本输入至预设语言模型,得到问题文本对应的第一回答文本,实现了基于关键词抽取的多级相似度匹配,通过将关键词向量与各层级下的节点的标题向量依次进行匹配,极大提高匹配的精度,在专业领域相对复杂的多知识点聚合场景下,可以从更高的细粒度识别问题的意图,提高问答的准确性,解决现有技术中单一信息索引导致的召回率精度较低的问题,并且,该方法适用于各种专业领域,无需针对每个专业领域单独训练模型,适用性强。
技术特征:
1.一种专业领域的生成式问答方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述专业领域的主题库与内容库的构建包括如下步骤:
3.根据权利要求2所述的方法,其特征在于,根据所述专业领域下各关联文档对应的标题树,构建所述专业领域的主题库与内容库,包括:
4.根据权利要求1所述的方法,其特征在于,所述从各当前节点开始向下确定各节点的标题向量与所述关键词向量之间的相似度,直至在所述主题库中确定目标节点,包括:
5.根据权利要求1所述的方法,其特征在于,所述根据各目标节点的文本向量确定所述问题文本对应的提示文本,包括:
6.根据权利要求1所述的方法,其特征在于,在确定所述问题文本对应的关键词向量之后,还包括:
7.根据权利要求6所述的方法,其特征在于,在更新所述问题文本以及对应的关键词向量之后,还包括:
8.根据权利要求6所述的方法,其特征在于,所述方法还包括:
9.根据权利要求4所述的方法,其特征在于,所述方法还包括:
10.一种电子设备,其特征在于,所述电子设备包括:
技术总结
本发明涉及数据处理技术领域,公开了一种专业领域的生成式问答方法及电子设备,该方法包括:通过获取问题文本并确定对应的关键词向量,在对应的专业领域的主题库中,通过对各层级的节点依次进行标题向量与关键词向量之间的相似度匹配,得到目标节点,进而在对应的专业领域的内容库中,基于各目标节点的标识得到提示文本,结合提示文本与问题文本生成第一文本输入至预设语言模型,得到第一回答文本,实现了基于关键词抽取的多级相似度匹配,通过将关键词向量与各层级下的节点的标题向量依次进行匹配,极大提高匹配的精度,在专业领域相对复杂的多知识点聚合场景下,可以从更高的细粒度识别问题的意图,提高问答的准确性。
技术研发人员:孟祥飞,赵玮,康波,庞晓磊,赵欣婷,聂鹏飞,吴玲,傅浩
受保护的技术使用者:国家超级计算天津中心
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!