数据处理方法、装置及存储介质与流程
本发明涉及智能意图识别领域,具体而言,涉及一种数据处理方法、装置及存储介质。
背景技术:
1、当前,在线客服已成为许多行业为客户提供业务办理的重要渠道。智能坐席助理作为一种基于语音识别、自然语言理解和知识库等智能技术的辅助工具,在在线客服中发挥着重要作用。智能坐席助理通过识别客服对话中产生的查询、办理、投诉、故障等多种复杂类型的用户意图,实时辅助坐席应对用户咨询,并实时监控坐席服务是否符合管理规范。智能坐席助理还能对客户需求进行统计分析,对频繁出现的问题进行纠偏引导,从而有效提升客户满意度。因此,在智能坐席助理系统中,意图分析是其重要功能之一。
2、然而,现有的智能对话意图分析方法主要存在以下几类问题:
3、(1)意图标签体系复杂,具有多个层级、多种类别,且同一层级下标签含义相似度较大,容易误判对话意图;
4、(2)依赖人工客服手动录入用户意图标签,并且没有统一化、标准化的面向客服对话数据的标注规范,不仅成本高、效率低下,还容易出现多标、错标、漏标、尺度不一致等情况;
5、(3)传统的基于机器学习技术的意图分析系统,其主要思想是构建端到端的判别式模型,缺乏必要的辅助、反馈机制,导致意图分析系统难以持续优化;
6、(4)传统模型只能根据输出意图标签的概率进行排序,无法在训练过程中考虑对话角、对话核心意图信息等因素,导致意图分析系统的准确率低下。
7、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种数据处理方法、装置及存储介质,以至少解决相关技术中对话意图分析方法成本高、准确率和效率低下的技术问题。
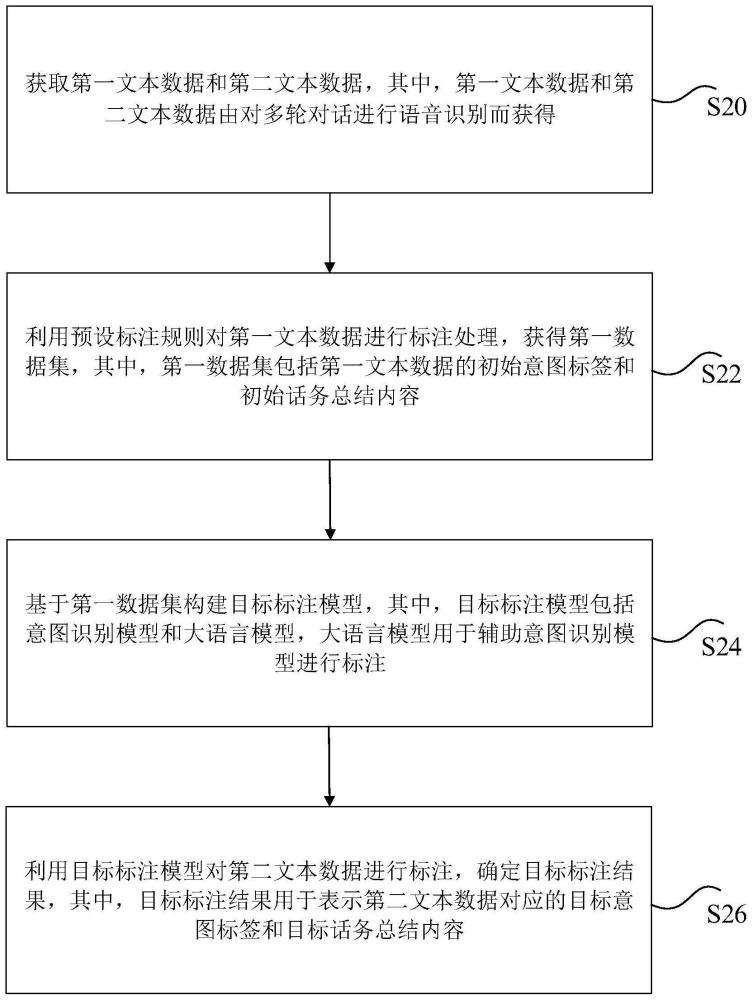
2、根据本发明实施例的其中一个方面,提供了一种数据处理方法,包括:获取第一文本数据和第二文本数据,其中,第一文本数据和第二文本数据由对多轮对话进行语音识别而获得;利用预设标注规则对第一文本数据进行标注处理,获得第一数据集,其中,第一数据集包括第一文本数据的初始意图标签和初始话务总结内容;基于第一数据集构建目标标注模型,其中,目标标注模型包括意图识别模型和大语言模型,大语言模型用于辅助意图识别模型进行标注;利用目标标注模型对第二文本数据进行标注,确定目标标注结果,其中,目标标注结果用于表示第二文本数据对应的目标意图标签和目标话务总结内容。
3、可选地,利用预设标注规则对第一文本数据进行标注处理,获得第一数据集包括:获取第一文本数据对应的语义角色信息;基于第一文本数据与语义角色信息确定初始意图标签;基于时间戳信息对初始意图标签进行排序,得到排序结果;基于预设规则对排序结果进行合并,获得初始话务总结内容。
4、可选地,基于第一数据集构建意图识别模型包括:利用解析策略对第一数据集进行解析处理,得到解析结果,其中,解析处理至少包含以下之一:直接解析、窗口解析、基于初始意图标签解析、基于初始话务总结内容解析、基于语义角色信息解析;对解析结果进行加权处理,得到第二数据集;基于第二数据集和第三文本数据构建意图识别模型,其中,意图识别模型为双分支结构模型,第三文本数据用于描述初始意图标签。
5、可选地,基于第二数据集和第三文本数据构建意图识别模型包括:基于第二数据集、第三文本数据以及第一损失函数构建意图识别模型的第一分支结构,其中,第一损失函数基于初始意图标签和第二数据集的特征向量而确定;基于第二数据集、第三文本数据以及第二损失函数构建意图识别模型的第二分支结构,其中,第二损失函数基于第二数据集的逻辑分数和边距值而确定;基于第一分支结构、第二分支结构以及第三损失函数构建意图识别模型,其中,第三损失函数基于第一损失函数和第二损失函数而确定。
6、可选地,基于第一数据集构建大语言模型包括:基于第二数据集获得微调数据集,其中,微调数据集用于确定调节大语言模型底座的参数值;基于第二数据集和微调数据集构建大语言模型。
7、可选地,利用目标标注模型对第二文本数据进行标注,确定目标标注结果包括:利用意图识别模型对第二文本数据进行标注处理,获得第一标注结果,其中,第一标注结果包含第二文本数据对应的第一意图标签和第一话务总结内容;利用大语言模型对第二文本数据进行标注处理,获得第二标注结果,其中,第二标注结果包含第二文本数据对应的第二意图标签和第二话务总结内容;将第一标注结果与第二标注结果进行比对,得到第一比对结果;基于第一比对结果确定目标标注结果。
8、可选地,基于第一比对结果确定目标标注结果包括:响应基于第一比对结果确定第一标注结果与第二标注结果不一致,将第一话务总结内容与第二话务总结内容进行比对,得到第二比对结果;响应于基于第二比对结果确定第一话务总结内容与第二话务总结内容一致,将第一标注结果确定为目标标注结果。
9、可选地,上述数据处理方法还包括:响应于第二比对结果确定第一话务总结内容与第二话务总结内容不一致,将第一话务总结内容和第二话务总结内容的交集确定为目标话务总结内容,将第一意图标签确定为目标意图标签。
10、根据本发明实施例的其中一方面,还提供了一种数据处理装置,包括:获取模块,用于获取第一文本数据和第二文本数据,其中,第一文本数据和第二文本数据基于语音识别而获得;标注模块,用于利用预设标注规则对第一文本数据进行标注处理,获得第一数据集,其中,第一数据集包括第一文本数据的初始意图标签和初始话务总结内容;构建模块,用于基于第一数据集构建目标标注模型,其中,目标标注模型包括意图识别模型和大语言模型,大语言模型用于辅助意图识别模型进行标注;确定模块,用于利用目标标注模型对第二文本数据进行标注,确定目标标注结果,其中,目标标注结果用于表示第二文本数据对应的目标意图标签和目标话务总结内容。
11、可选地,获取模块还用于,获取第一文本数据对应的语义角色信息;确定模块还用于:基于第一文本数据与语义角色信息确定初始意图标签;基于时间戳信息对初始意图标签进行排序,得到排序结果;基于预设规则对排序结果进行合并,获得初始话务总结内容。
12、可选地,构建模块还用于:利用解析策略对第一数据集进行解析处理,得到解析结果,其中,解析处理至少包含以下之一:直接解析、窗口解析、基于初始意图标签解析、基于初始话务总结内容解析、基于语义角色信息解析;对解析结果进行加权处理,得到第二数据集;基于第二数据集和第三文本数据构建意图识别模型,其中,意图识别模型为双分支结构模型,第三文本数据用于描述初始意图标签。
13、可选地,构建模块还用于:基于第二数据集、第三文本数据以及第一损失函数构建意图识别模型的第一分支结构,其中,第一损失函数基于初始意图标签和第二数据集的特征向量而确定;基于第二数据集、第三文本数据以及第二损失函数构建意图识别模型的第二分支结构,其中,第二损失函数基于第二数据集的逻辑分数和边距值而确定;基于第一分支结构、第二分支结构以及第三损失函数构建意图识别模型,其中,第三损失函数基于第一损失函数和第二损失函数而确定。
14、可选地,构建模块还用于:基于第二数据集获得微调数据集,其中,微调数据集用于确定调节大语言模型底座的参数值;基于第二数据集和微调数据集构建大语言模型。
15、可选地,标注模块还用于:利用意图识别模型对第二文本数据进行标注处理,获得第一标注结果,其中,第一标注结果包含第二文本数据对应的第一意图标签和第一话务总结内容;利用大语言模型对第二文本数据进行标注处理,获得第二标注结果,其中,第二标注结果包含第二文本数据对应的第二意图标签和第二话务总结内容;确定模块还用于:将第一标注结果与第二标注结果进行比对,得到第一比对结果;基于第一比对结果确定目标标注结果。
16、可选地,确定模块还用于:响应基于第一比对结果确定第一标注结果与第二标注结果不一致,将第一话务总结内容与第二话务总结内容进行比对,得到第二比对结果;响应于基于第二比对结果确定第一话务总结内容与第二话务总结内容一致,将第一标注结果确定为目标标注结果。
17、可选地,确定模块还用于:响应于第二比对结果确定第一话务总结内容与第二话务总结内容不一致,将第一话务总结内容和第二话务总结内容的交集确定为目标话务总结内容,将第一意图标签确定为目标意图标签。
18、根据本发明实施例的其中一方面,还提供了一种非易失性存储介质,非易失性存储介质中存储有计算机程序,其中,在非易失性存储介质所在设备通过运行计算机程序执行上述任意一项的数据处理方法。
19、在本发明实施例中,采用获取第一文本数据和第二文本数据以及利用预设标注规则对第一文本数据进行标注处理,获得第一数据集的方式,基于第一数据集构建目标标注模型,利用目标标注模型对第二文本数据进行标注,确定目标标注结果,达到了快速、准确地识别对话意图的目的,从而实现了降低对话意图分析系统成本,提高对话意图分析方法的准确率和效率的技术效果,进而解决了相关技术中对话意图分析方法成本高、准确率和效率低下的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!