用于大语言模型的数据知识提取方法与流程
本发明涉及自然语言数据处理,具体涉及用于大语言模型的数据知识提取方法。
背景技术:
1、在自然语言数据处理技术中,通常采用大语言模型的数据知识提取方法对英文文本数据进行数据提取。大语言模型的数据提取方法通常包括:文本数据预处理、分词、词向量表示、训练模型、特征抽取和知识提取以及后处理对应的几个过程。通过词向量表示过程能够将分词处理得到的各个分词转化为高维向量;进一步地通过训练模型以及特征抽取和知识提取过程能够筛选出用于数据降维的分词高维向量;进一步地根据分词高维向量进行数据降维,即可根据降维后的向量进行英文文本数据知识提取。
2、现有技术通常采用主成分分析(principal components analysis,pca)降维方法根据分词高维向量进行数据降维,但是pca降维方法在选取主要特征向量构建投影矩阵时,需要确定前k个特征向量,也即k值的选取;k值的选取不当会导致信息保留不完善,从而导致降维效果较差,也即现有技术直接对各个分词高维向量通过pca降维方法进行数据降维的效果较差,造成对英文文本数据知识提取的效果较差。
技术实现思路
1、为了解决现有技术直接对各个分词高维向量通过pca降维方法进行数据降维的效果较差,造成对英文文本数据知识提取的效果较差的技术问题,本发明的目的在于提供一种用于大语言模型的数据知识提取方法,所采用的技术方案具体如下:
2、本发明提出了一种用于大语言模型的数据知识提取方法,所述方法包括:
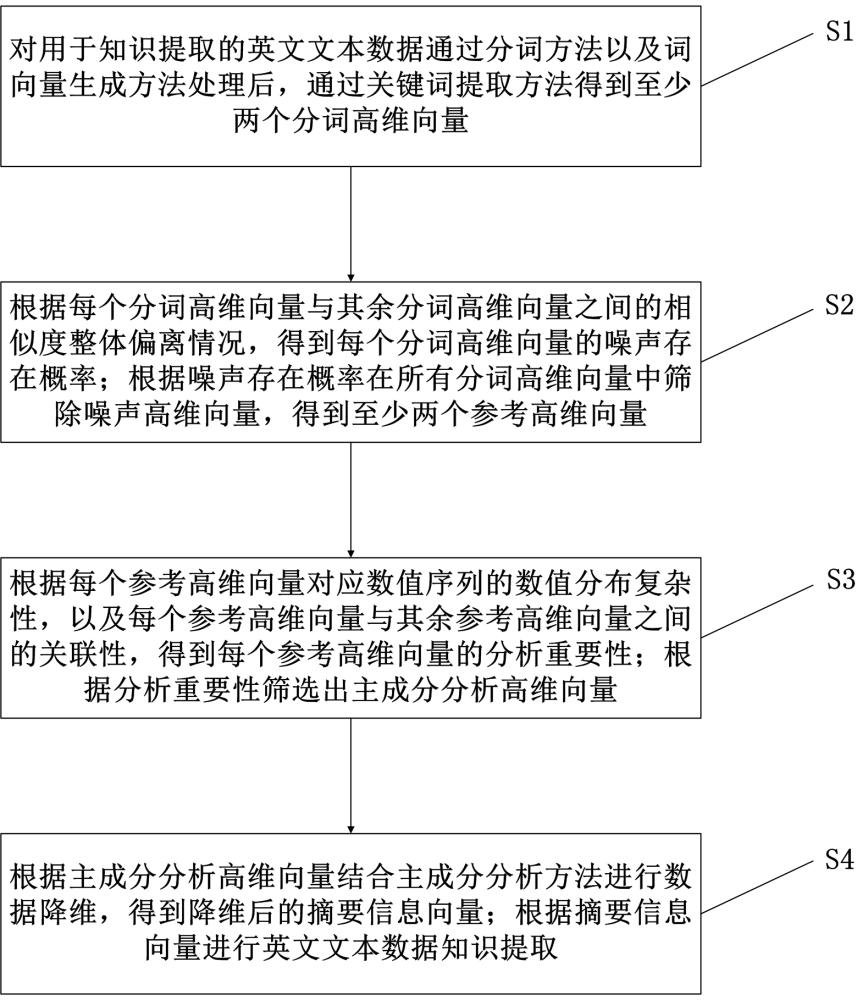
3、对用于知识提取的英文文本数据通过分词方法以及词向量生成方法处理后,通过关键词提取方法得到至少两个分词高维向量;
4、根据每个分词高维向量与其余分词高维向量之间的相似度整体偏离情况,得到每个分词高维向量的噪声存在概率;根据所述噪声存在概率在所有分词高维向量中筛除噪声高维向量,得到至少两个参考高维向量;
5、根据每个参考高维向量对应数值序列的数值分布复杂性,以及每个参考高维向量与其余参考高维向量之间的关联性,得到每个参考高维向量的分析重要性;根据所述分析重要性筛选出主成分分析高维向量;
6、根据所述主成分分析高维向量结合主成分分析方法进行数据降维,得到降维后的摘要信息向量;根据所述摘要信息向量进行英文文本数据知识提取。
7、进一步地,所述噪声存在概率的获取方法包括:
8、任选两个分词高维向量作为一个高维向量二元组,获取所有的高维向量二元组;将每个高维向量二元组中的两个分词高维向量之间的余弦相似度,作为每个高维向量二元组的参考相似度;将所有高维向量二元组的参考相似度的均值,作为向量整体相似度;
9、依次将每个分词高维向量,作为目标分词高维向量;在所有分词高维向量中,将目标分词高维向量之外的其他分词高维向量,作为目标分词高维向量的对比高维向量;将目标分词高维向量与每个对比高维向量之间的余弦相似度,作为目标分词高维向量的每个对比高维向量的对比相似度;将目标分词高维向量的对应的所有对比高维向量的对比相似度的均值,作为目标分词高维向量的向量局部相似度;
10、将目标分词高维向量的向量局部相似度与所述向量整体相似度之间的差异,作为目标分词高维向量的向量偏离程度;
11、将目标分词高维向量中所有元素值的方差,作为目标分词高维向量的数值离散程度;
12、根据所述向量偏离程度和所述数值离散程度,得到目标分词高维向量的噪声存在概率,所述向量偏离程度和所述数值离散程度均与所述噪声存在概率呈正相关关系。
13、进一步地,所述参考高维向量的获取方法包括:
14、将大于预设噪声阈值的噪声存在概率对应的分词高维向量,作为噪声高维向量;将所有分词高维向量中噪声高维向量之外的分词高维向量,作为参考高维向量。
15、进一步地,所述分析重要性的获取方法包括:
16、将每个参考高维向量标量化后,得到每个参考高维向量的标量数据序列;将所述标量数据序列中所有数据的信息熵,作为每个参考高维向量的分布混乱程度;
17、依次将每个参考高维向量作为目标参考高维向量;在所有参考高维向量中,将目标参考高维向量之外的其他参考高维向量,作为目标参考高维向量对应的对比参考高维向量;
18、根据每个对比参考高维向量的分布混乱程度与目标参考高维向量的分布混乱程度之间的相对占比,得到每个对比参考高维向量的对比权重系数;
19、将每个对比参考高维向量的对比权重系数的负相关映射值,作为每个对比参考高维向量影响下目标参考高维向量的参考权重系数;
20、通过所述对比权重系数对每个对比参考高维向量的标量数据序列进行加权,得到每个对比参考高维向量的加权数据序列;通过所述参考权重系数对目标参考高维向量的标量数据序列进行加权,得到每个对比参考高维向量影响下目标参考高维向量的加权数据序列;
21、将每个对比参考高维向量的加权数据序列与对应的对比参考高维向量影响下目标参考高维向量的加权数据序列之间的皮尔逊相关系数,作为每个对比参考高维向量的加权相关性;将目标参考高维向量对应的所有对比参考高维向量的加权相关性的均值的归一化值,作为目标参考高维向量的分析重要性。
22、进一步地,所述根据所述主成分分析高维向量结合主成分分析方法进行数据降维,得到降维后的摘要信息向量的方法包括:
23、将每个主成分高维向量作为列向量组成主成分分析矩阵;对所述主成分分析矩阵通过主成分分析方法得到对应的协方差矩阵的各个特征向量和每个特征向量对应的特征值;
24、将每个特征向量对应的特征值,以从大到小的顺序排列,得到特征值序列;将特征值序列中所有特征值的累加和,作为整体累加值;在所述特征值序列中,将每个特征值与该特征值之前的所有特征值的累加和,作为每个特征值的参考累加值;将所述参考累加值与所述整体累加值的比值,作为每个特征值对应的特征向量的方差解释率;在所述特征值序列中,将大于预设解释率阈值的方差解释率对应的特征值的索引值,作为主成分分析的最优k值;
25、根据所述最优k值以及所述主成分分析矩阵进行主成分分析降维,得到降维后的各个摘要信息向量。
26、进一步地,所述分词高维向量的获取方法包括:
27、对用于知识提取的英文文本数据通过分词方法进行分词,得到至少两个分词处理单元;通过word2vec技术将每个分词处理单元映射为初始高维向量;通过训练好的大语言模型bert得到每个初始高维向量的语义信息;根据所有初始高维向量的语义信息通过tf-idf算法进行提取,得到至少两个分词高维向量。
28、进一步地,所述根据所述向量偏离程度和所述数值离散程度,得到目标分词高维向量的噪声存在概率的方法包括:
29、将所述向量偏离程度和所述数值离散程度的乘积的归一化值,作为目标分词高维向量的噪声存在概率。
30、进一步地,所述对比权重系数的获取方法包括:
31、将每个对比参考高维向量的分布混乱程度与目标参考高维向量的分布混乱程度之间的和值,作为每个对比参考高维向量的参考适应和值;将目标参考高维向量的分布混乱程度与所述参考适应和值的比值,作为每个对比参考高维向量的对比权重系数。
32、进一步地,所述参考权重系数的获取方法包括:
33、将正数1与每个对比参考高维向量的对比权重系数之间的差值,作为每个对比参考高维向量影响下目标参考高维向量的参考权重系数。
34、进一步地,所述根据所述分析重要性筛选出主成分分析高维向量的方法包括:
35、将大于预设分析阈值的分析重要性对应的参考高维向量,作为主成分分析高维向量。
36、本发明具有如下有益效果:
37、考虑到pca降维通常借助累计方差解释率选取k值,但是首先需要确定累计方差解释率的最优阈值,而最优阈值的确定受到降维后向量的特征保留度的制约,向量的特征保留度即降维后的结果满足简单显示并概括文本内容的程度,对于能够满足简单显示并概括文本内容的信息对应的分词高维向量,在进行k值累计方差解释率阈值选取时的贡献度是需要放大的,目的是将其作为摘要信息保留到最终经过降维后的向量中,从而使得得到的k值更加准确。对于满足简单显示并概括文本内容的分词高维向量的特征,通常表现为向量内元素的重复性较高并且向量之间的距离和模值相近,以及重复率较高等数据分布性较高的向量,也即本发明对应的主成分分析高维向量。因此本发明的目的即获取主成分分析高维向量,首先为了避免部分可能出现异常的噪声高维向量对后续筛选过程的影响,噪声数据通常对应拼写错误或转录错误对应的数据,所以根据每个分词高维向量与其余分词高维向量之间的相似度整体偏离情况得到噪声存在概率,得到筛除噪声高维向量后对应的各个参考高维向量;进一步地根据简单显示并概括文本内容通常具有较高的重复性并且分布较为稳定的特征,结合每个参考高维向量对应数值序列的数值分布复杂性,以及每个参考高维向量与其余参考高维向量之间的关联性,筛选出主成分分析高维向量,使得根据主成分分析高维向量通过pca降维方法进行数据降维的效果更好,也即根据降维后的摘要信息向量对英文文本数据知识提取的效果更好。
- 还没有人留言评论。精彩留言会获得点赞!