一种新闻文本分类方法
本发明属于数据处理,具体涉及一种新闻文本分类方法。
背景技术:
1、现在,新闻阅读产品一般是按照新闻内容所属的领域进行组织和整理的,如根据热点、国内和国际等或根据科技、军事和娱乐等进行分类发行。目前,上述对新闻进行分类发行的过程,通常是由人工进行的,这不仅浪费了人力,而且使得新闻分类结果受个人主观感受的影响较大,使得分类结果不够精准。
技术实现思路
1、本发明为了解决以上问题,提出了一种新闻文本分类方法。
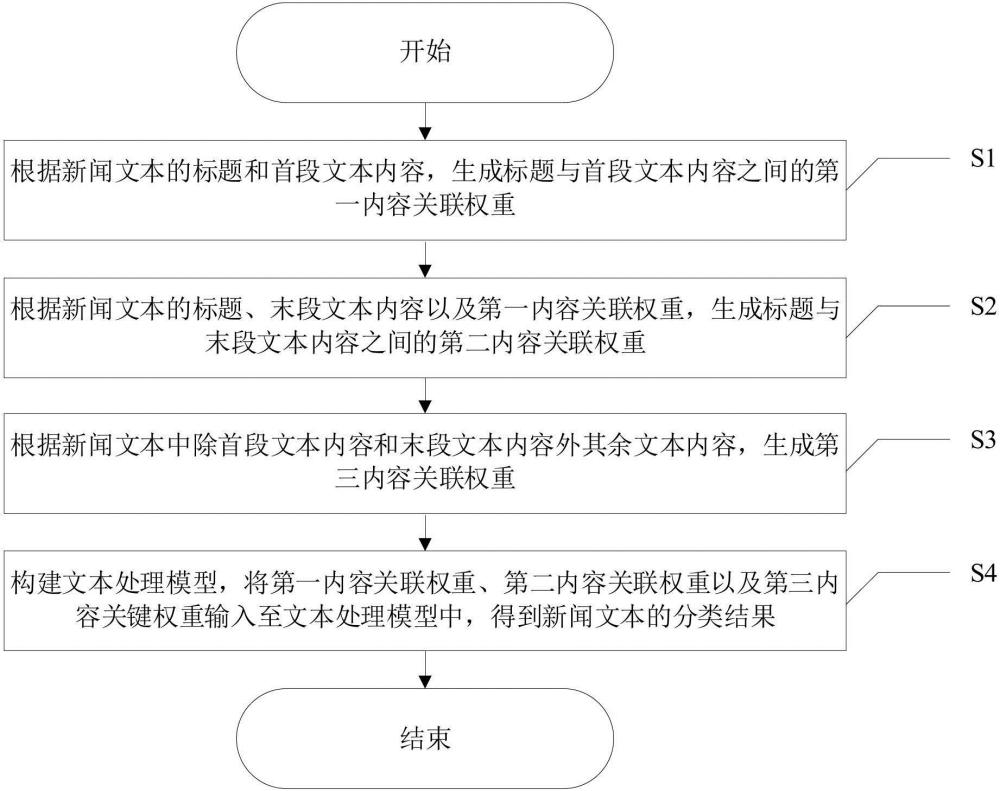
2、本发明的技术方案是:一种新闻文本分类方法包括以下步骤:
3、s1、根据新闻文本的标题和首段文本内容,生成标题与首段文本内容之间的第一内容关联权重;
4、s2、根据新闻文本的标题、末段文本内容以及第一内容关联权重,生成标题与末段文本内容之间的第二内容关联权重;
5、s3、根据新闻文本中除首段文本内容和末段文本内容外其余文本内容,生成第三内容关联权重;
6、s4、构建文本处理模型,将第一内容关联权重、第二内容关联权重以及第三内容关键权重输入至文本处理模型中,得到新闻文本的分类结果。
7、进一步地,s1包括以下子步骤:
8、s11、剔除新闻文本的标题和首段文本内容的停用词,分别得到标准标题和标准首段文本内容;
9、s12、提取标准首段文本内容中与标准标题的相同单词,生成第一训练单词序列;
10、s13、根据第一训练单词序列,确定首段占比率;
11、s14、根据首段占比率,生成标题与首段文本内容之间的第一内容关联权重。
12、上述进一步方案的有益效果是:在本发明中,新闻文本首段通常会简单介绍新闻事件的概要,因此具有较高的参考价值,又考虑到新闻标题是对整个新闻文本内容的高度概括,因此本发明构建第一内容关联权重来反映新闻标题与首段内容之间的关联程度。第一内容关联权重参考了首段文本内容中与新闻标题相同的单词在首段文本内容的占比情况以及这些相同单词的词向量,使得第一内容关联权重可以有效反映语义关联程度。
13、进一步地,s13中,首段占比率zf的计算公式为:;式中,p表示第一训练单词序列的单词个数,m表示标准首段文本内容的单词个数,j表示标准标题的单词个数。
14、进一步地,s14中,标题与首段文本内容之间的第一内容关联权重σ1的计算公式为:;式中,p表示第一训练单词序列的单词个数,cp表示第一训练单词序列中第p个单词在标准首段文本内容的词频,zf表示首段占比率,xp表示第一训练单词序列中第p个单词的词向量。
15、进一步地,s2包括以下子步骤:
16、s21、剔除末段文本内容的停用词,得到标准末段文本内容;
17、s22、提取标准末段文本内容中与标准标题的相同单词,生成第二训练单词序列;
18、s23、根据第二训练单词序列,确定末段占比率;
19、s24、根据首段占比率、末段占比率以及第一内容关联权重,计算标准首段文本内容与标准末段文本内容之间的内容关联标签值;
20、s26、根据标准首段文本内容与标准末段文本内容之间的内容关联标签值,生成标题与末段文本内容之间的第二内容关联权重。
21、上述进一步方案的有益效果是:在本发明中,考虑到新闻文本的首末段可能存在语义关联以及末段内容可能是对新闻文本内容的高度总结,因此本发明结合末段占比率和第一内容关联权重等参数来构建第二内容关联权重,在末段占比率大于两倍首段占比率时,说明首段文本内容的重要性较低,则适当减小第一内容关联权重对第二内容关联权重的影响,并利用第二内容关联权重来反映末段文本内容与新闻标题之间的关联程度。
22、进一步地,s23中,末段占比率zl的计算公式为:;式中,q表示第二训练单词序列的单词个数,n表示标准末段文本内容的单词个数,j表示标准标题的单词个数。
23、进一步地,s24中,标准首段文本内容与标准末段文本内容之间的内容关联标签值b的计算公式为:;式中,zf表示首段占比率,zl表示末段占比率,σ1表示标题与首段文本内容之间的第一内容关联权重。
24、进一步地,s26中,标题与末段文本内容之间的第二内容关联权重σ2的计算公式为:;式中,q表示第二训练单词序列的单词个数,cq表示第二训练单词序列中第q个单词在标准末段文本内容的词频,zl表示末段占比率,xq表示第二训练单词序列中第q个单词的词向量,b表示标准首段文本内容与标准末段文本内容之间的内容关联标签值。
25、进一步地,s3中,生成第三内容关联权重的具体方法为:选取除首段文本内容和末段文本内容外其余文本内容中单词数量最多的段落,作为次要段落,提取次要段落的关键词,根据次要段落的所有关键词以及标准标题,生成第三内容关联权重;
26、其中,第三内容关联权重σ3的计算公式为:;式中,xj表示标准标题中第j个单词的词向量,表示次要段落中最高词频单词的词向量,exp(·)表示指数函数,j表示标准标题的单词个数。
27、上述进一步方案的有益效果是:在本发明中,文本内容最多(即单词数量最多)的段落是对新闻事件的详细描述,因此本发明采用该段落的词向量分布情况来构建第三内容关联权重。
28、进一步地,文本处理模型的目标函数loss的表达式为:;式中,o表示新闻文本的单词个数,ln(·)表示对数函数,σ1表示第一内容关联权重,σ2表示第二内容关联权重,σ3表示第三内容关联权重,r表示支持向量机的超参数。
29、文本处理模型可采用支持向量机。
30、本发明的有益效果是:本发明公开了一种新闻文本分类方法,对新闻文本中重要的首末段以及文本内容最多的段落依次进行文本分析处理,得到三个表征语义信息的内容关联权重,再将三个内容关联权重输入至构建的文本处理模型中,可以得到新闻文本的精准类别。整个分类过程把握新闻文本整体内容结构,充分考虑关键词的影响,分类结果的误差小,准确率高。
技术特征:
1.一种新闻文本分类方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的新闻文本分类方法,其特征在于,所述s1包括以下子步骤:
3.根据权利要求2所述的新闻文本分类方法,其特征在于,所述s13中,首段占比率zf的计算公式为:;式中,p表示第一训练单词序列的单词个数,m表示标准首段文本内容的单词个数,j表示标准标题的单词个数。
4.根据权利要求2所述的新闻文本分类方法,其特征在于,所述s14中,标题与首段文本内容之间的第一内容关联权重σ1的计算公式为:;式中,p表示第一训练单词序列的单词个数,cp表示第一训练单词序列中第p个单词在标准首段文本内容的词频,zf表示首段占比率,xp表示第一训练单词序列中第p个单词的词向量。
5.根据权利要求1所述的新闻文本分类方法,其特征在于,所述s2包括以下子步骤:
6.根据权利要求5所述的新闻文本分类方法,其特征在于,所述s23中,末段占比率zl的计算公式为:;式中,q表示第二训练单词序列的单词个数,n表示标准末段文本内容的单词个数,j表示标准标题的单词个数。
7.根据权利要求5所述的新闻文本分类方法,其特征在于,所述s24中,标准首段文本内容与标准末段文本内容之间的内容关联标签值b的计算公式为:;式中,zf表示首段占比率,zl表示末段占比率,σ1表示标题与首段文本内容之间的第一内容关联权重。
8.根据权利要求5所述的新闻文本分类方法,其特征在于,所述s26中,标题与末段文本内容之间的第二内容关联权重σ2的计算公式为:;式中,q表示第二训练单词序列的单词个数,cq表示第二训练单词序列中第q个单词在标准末段文本内容的词频,zl表示末段占比率,xq表示第二训练单词序列中第q个单词的词向量,b表示标准首段文本内容与标准末段文本内容之间的内容关联标签值。
9.根据权利要求1所述的新闻文本分类方法,其特征在于,所述s3中,生成第三内容关联权重的具体方法为:选取除首段文本内容和末段文本内容外其余文本内容中单词数量最多的段落,作为次要段落,提取次要段落的关键词,根据次要段落的所有关键词以及标准标题,生成第三内容关联权重;
10.根据权利要求1所述的新闻文本分类方法,其特征在于,所述文本处理模型的目标函数loss的表达式为:;式中,o表示新闻文本的单词个数,ln(·)表示对数函数,σ1表示第一内容关联权重,σ2表示第二内容关联权重,σ3表示第三内容关联权重,r表示支持向量机的超参数。
技术总结
本发明公开了一种新闻文本分类方法,属于数据处理技术领域,包括以下步骤:S1、根据新闻文本的标题和首段文本内容,生成标题与首段文本内容之间的第一内容关联权重;S2、根据新闻文本的标题、末段文本内容以及第一内容关联权重,生成标题与末段文本内容之间的第二内容关联权重;S3、根据新闻文本中除首段文本内容和末段文本内容外其余文本内容,生成第三内容关联权重;S4、构建文本处理模型,将第一内容关联权重、第二内容关联权重以及第三内容关键权重输入至文本处理模型中,得到新闻文本的分类结果。整个分类过程把握新闻文本整体内容结构,充分考虑关键词的影响,分类结果的误差小,准确率高。
技术研发人员:冯卓文,王观承,王颢静,徐广珺
受保护的技术使用者:广东海洋大学
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!