一种基于用户自定义类别的物体检测方法及系统与流程
本发明属于图文数据处理,尤其涉及一种基于用户自定义类别的物体检测方法及系统。
背景技术:
1、随着人工智能技术的发展,越来越多的图像识别系统获得了应用,比如人脸识别、物体检测等。由于受经典神经网络技术的限制,主流物体检测算法只能识别预先定义的物体种类,如人形、车辆、宠物等,而不能识别未预先定义的物体种类。
2、随着变形神经网络(transformer)技术的发展,图文多模态模型可以同时处理文本和图像数据,并支持未预先定义类别的物体检测。一方面,由于受到成本限制,图文多模态模型的参数规模不会太大,因而不能理解复杂的用户文本输入,只能理解简单的目标刻画关键词。如何把用户的自然语言输入和图像输入转为合适的检测目标文本刻画是应用图文多模态模型的关键问题。
3、现有公开了基于先验知识启发大语言模型的图像推理问答方法(专利申请号为:cn202310744506.2),该方案通过视觉问答小模型向大语言模型提供更多的图片信息,得到更好的图像知识推理结果,该方法通过提供丰富的输入给大语言模型来调用其推理能力,而用户自定义类别物体检测的目标是通过提供合适的输入给图文多模态模型来激发其物体检测能力,该方案的运算量比较大,检测速度慢,对输入的数据有要求,不能实现自定义类别的输入。现有公开了一种基于预训练语言模型的图像信息抽取方法及装置(专利申请号为:cn202311132052.x),其通过提示(prompt)模板的方法来调用预训练语言模型对图片中识别出来的文字信息进行推理和纠错,输出文本信息,在提供单一图片文本信息抽取服务的应用场景下,提示(prompt)模板方法可有效结合语言模型和图片字符识别模型来进行图像文本信息的生成,但是有限的提示库模板难以应对大量用户都需要进行自定义类别物体检测的应用场景。现有公开了基于提示学习的意图识别方法、问答方法及装置(专利申请号为:cn202211013807.x),其采用提示学习范式来对输入文本进行重构并应用到自动问答中,其实质是判断输入文本的类别并添加特定的提示词,比如输入文本是“为什么a会故障”,重构的文本是“为什么a会故障,答案是…”,其目的是让语言模型给出更合理的答案,客观上增加了输入文本的长度,该方案只能处理单一模态文本信息,并不支持处理多模态图像和文本信息。
技术实现思路
1、本技术提供了一种基于用户自定义类别的物体检测方法及系统,旨在解决如何通过用户输入的图像和文本生成合适的自定义检测目标的文本刻画,以激发图文多模态模型物体检测能力的问题。
2、为了实现上述目的,本发明采用以下技术方案:
3、一种基于用户自定义类别的物体检测方法,包括:
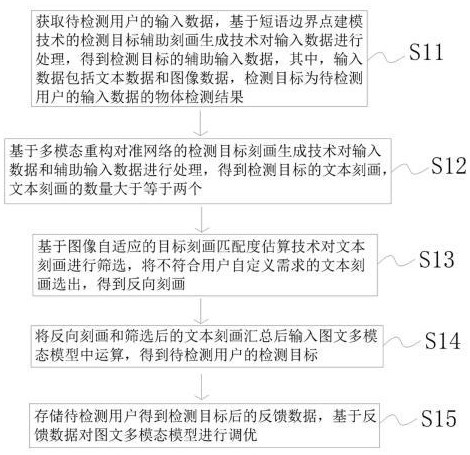
4、获取待检测用户的输入数据,基于短语边界点建模技术的检测目标辅助刻画生成技术对输入数据进行处理,得到检测目标的辅助输入数据,其中,输入数据包括文本数据和图像数据,检测目标为待检测用户的输入数据的物体检测结果;
5、基于多模态重构对准网络的检测目标刻画生成技术对输入数据和辅助输入数据进行处理,得到检测目标的文本刻画,文本刻画的数量大于等于两个;
6、基于图像自适应的目标刻画匹配度估算技术对文本刻画进行筛选,将不符合用户自定义需求的文本刻画选出,得到反向刻画;
7、将反向刻画和筛选后的文本刻画汇总后输入图文多模态模型中运算,得到待检测用户的检测目标;
8、存储待检测用户得到检测目标后的反馈数据,基于反馈数据对图文多模态模型进行调优。
9、作为优选,基于短语边界点建模技术的检测目标辅助刻画生成技术对输入数据进行处理,得到检测目标的辅助输入数据,具体为:
10、基于文本数据从历史文本库dst中提取相似文本集合,基于图像数据从历史图像库dsi中提取相似图像集合,将相似图像集合代入图文多模态模型中计算,得到相似图像集合对应的刻画文本集合,将相似文本集合和刻画文本集合汇总,得到辅助输入集合;
11、基于短语边界点建模技术的检测目标辅助刻画生成技术提取辅助输入集合中文本语句的关键短语,将关键短语汇总,得到辅助输入数据。
12、作为优选,基于文本数据从历史文本库dst中提取相似文本集合,具体为:将历史文本库dst中文本依次代入公式中进行计算,当计算结果小于第一预设阈值时,将对应文本加入相似文本集合,其中,为文本数据,为的嵌入向量,为历史文本库dst中第i项文本,为的嵌入向量,i为非零的自然数;
13、基于图像数据从历史图像库dsi中提取相似图像集合,具体为:使用图文多模态模型提取图像数据的特征,并提取历史图像库dsi中第i项图像的特征,将和代入进行计算,当计算结果小于第二预设阈值时,将对应图像加入相似图像集合。
14、作为优选,得到关键短语的处理过程具体为:
15、依据高斯分布选取个样本,其中为非零自然数;
16、使用训练完成的模型,计算、、,其中,模型为去噪神经网络模型,是时刻短语的边界点的预测值,表示长度为的时间序列,,从 到1迭代计算,,和是个样本中的两个相邻样本,和均为预先定义的高斯分布的方差系数,为文本数据中的语句,和为短语左右两边的边界点的概率,,是可训练的参数矩阵,表示可训练的双层感知网络,为输入模型后输出的编码,为增强后的噪声采样;
17、依据边界点的概率值,解析出个候选短语的边界点,其中,,分别为短语左右的边界点;
18、从左右边界点相同的候选短语中选择概率值最高的,汇总后进行过滤,舍去概率值小于第三预设阈值的候选短语,得到关键短语。
19、作为优选,基于多模态重构对准网络的检测目标刻画生成技术对输入数据和辅助输入数据进行处理,得到检测目标的文本刻画,具体为:
20、获取训练样本数据,基于训练样本数据对文本模态的损失函数、图像模态的损失函数、辅助模态的损失函数进行联合优化,得到每个模态对应的刻画编码器和刻画生成解码器;
21、分别提取文本数据、图像数据和辅助输入数据的特征,将特征分别输入对应模态的刻画编码器,得到检测目标初级文本刻画、检测目标初级图像刻画和检测目标初级辅助刻画;
22、分别用检测目标初级文本刻画、检测目标初级图像刻画和检测目标初级辅助刻画挖掘隐藏在每个模态描述中的目标刻画特性,进行重构对准,合并后得到完整的刻画描述,将完整的刻画描述输入对应的刻画生成解码器,得到检测目标的文本刻画。
23、作为优选,基于图像自适应的目标刻画匹配度估算技术对文本刻画进行筛选,将不符合用户自定义需求的文本刻画选出,得到反向刻画,具体为:
24、使用上下文环境向量对文本刻画进行增强,得到增强后的输入刻画词;
25、提取图像数据中的图像特征,计算输入刻画词与图像特征之间的匹配值,将匹配值小于第四预设阈值的输入刻画词所对应的文本刻画选出,得到反向刻画,匹配值的计算公式为,其中为匹配值,,是一个可学习的超参数,表示两个特征之间的相似度,为图像特征,为所有文本刻画中的一个文本刻画,为文本刻画对应的输入刻画词,为所有文本刻画增强后的输入刻画词。
26、作为优选,使用上下文环境向量对文本刻画进行增强之前,还包括:
27、将文本刻画依次输入图文多模态模型中运算,得到检测结果,将检测结果反馈给待检测用户,待检测用户对检测结果进行正确或不正确的标注,当标注内容为不正确时,将该检测结果所对应的文本刻画进行增强。
28、一种基于用户自定义类别的物体检测系统,包括:
29、辅助输入数据计算模块:用于获取待检测用户的输入数据,基于短语边界点建模技术的检测目标辅助刻画生成技术对输入数据进行处理,得到检测目标的辅助输入数据,其中,输入数据包括文本数据和图像数据,检测目标为待检测用户的输入数据的物体检测结果;
30、文本刻画计算模块:用于基于多模态重构对准网络的检测目标刻画生成技术对输入数据和辅助输入数据进行处理,得到检测目标的文本刻画,文本刻画的数量大于等于两个;
31、反向刻画计算模块:用于基于图像自适应的目标刻画匹配度估算技术对文本刻画进行筛选,将不符合用户自定义需求的文本刻画选出,得到反向刻画;
32、物体检测模块:用于将反向刻画和筛选后的文本刻画汇总后输入图文多模态模型中运算,得到待检测用户的检测目标;
33、模型调优模块:用于存储待检测用户得到检测目标后的反馈数据,基于反馈数据对图文多模态模型进行调优。
34、一种电子设备,包括存储器和处理器,所述存储器用于存储一条或多条计算机指令,其中,所述一条或多条计算机指令被所述处理器执行以实现如上述中任一所述的一种基于用户自定义类别的物体检测方法。
35、一种计算机可读存储介质,所述存储介质中存储的计算机程序被计算机执行时实现如上述中任一所述的一种基于用户自定义类别的物体检测方法。
36、本发明具有以下有益效果:
37、(1)本方案支持用户自定义类别的物体检测技术,用户只需要输入一段语言描述(即文本数据)和一张相关图像(即图像数据),就能生成合适的检测目标的文本刻画,将其输入现有的图文多模态模型中,即可输出得到物体检测结果,能够充分激发图文多模态模型的物体检测能力,不需要复杂的模型训练,方案具有较好的性价比;
38、(2)本方案结合了多模态重构对准网络的检测目标刻画生成技术和图文多模态模型的图像识别能力,极大方便用户对图像识别技术的使用,方案具有较强的普及能力;
39、(3)本方案对输入的数据量没有要求,只需要用户按照意图自定义的输入一段语言描述和一张相关图像,通过短语边界点建模技术的检测目标辅助刻画生成技术、多模态重构对准网络的检测目标刻画生成技术、图像自适应的目标刻画匹配度估算技术的数据处理,即可生成合适的检测目标的文本刻画,输入图文多模态模型检测后,得到最符合用户需求的检测目标,便于用户的使用,且检测速度快,便于技术推广;
40、(4)本方案为提高物体检测的精度,基于输入数据通过历史文本库dst和历史图像库dsi生成辅助输入数据,历史文本库dst和历史图像库dsi都是使用的用户越多,数据库积累的文本数据或图像数据越多,能够应对大量用户都需要进行自定义类别物体检测的应用场景,且通过生成辅助输入数据的方式,能够避免忽略重要的背景信息以及最大限度发挥图文多模态模型的物体检测能力;
41、(5)本方案同时对文本数据模态、图像数据模态以及辅助数据模态进行多模态同时的训练,即支持同时进行多模态的数据处理,在进行多模态数据同时处理之后,再进行多模态重构对准处理,能进一步优化检测目标文本刻画的生成效果;
42、(6)本方案的实现,将会极大加快图像分析技术的普及,提高生产力,改善生活状态,方案具有一定的社会意义。
- 还没有人留言评论。精彩留言会获得点赞!