执行卷积计算的方法、计算装置、介质和程序产品与流程
本发明的实施例总体上涉及数据处理领域,更具体地涉及一种用于执行卷积计算的方法、计算装置、计算机可读存储介质和计算机程序产品。
背景技术:
1、传统的用于执行卷积计算的方法(特别是针对大尺寸卷积核的卷积计算)主要包括两种。第一种方法是将卷积计算转换为矩阵乘法,例如,将多维的卷积核滑动展开为1*1粒度的卷积核,然后反复多次从二级缓存(l2 cache,简称l2)或者高带宽存储器(hbm)加载数据(例如而不限于图像数据)到gpgpu中的加速计算单元(例如,张量核,即,tensorcore)做卷积计算。上述方法存在重复加载多,计算强度较低,数据利用率不足,以及对带宽要求更高的问题。
2、第二种方法是采用硬件特性的卷积指令,从l2或者hbm加载一次数据到tensorcore 的输入缓冲器,由tensorcore直接完成卷积核尺寸大小(即,kh*kw,其中,kh为卷积核高度,kw为卷积核宽度)的卷积计算。上述方法存在的不足在于:由于硬件电路的限制,使得卷积指令对卷积核尺寸大小有限制,进而导致泛化度不够。
3、综上,传统的用于执行卷积计算的方法存在的不足之处在于,难以兼顾解决:因过多重复加载数据而造成计算强度较低和数据利用率不足的问题,以及因硬件电路限制而导致的卷积指令泛化度不足的问题。
技术实现思路
1、本发明提供了一种用于执行卷积计算的方法、计算装置、计算机可读存储介质和计算机程序产品,不仅能够降低访存次数,提高计算访存比,进而显著提升整体计算的性能,而且能够避免硬件电路限制而导致的卷积指令泛化度不足的问题。
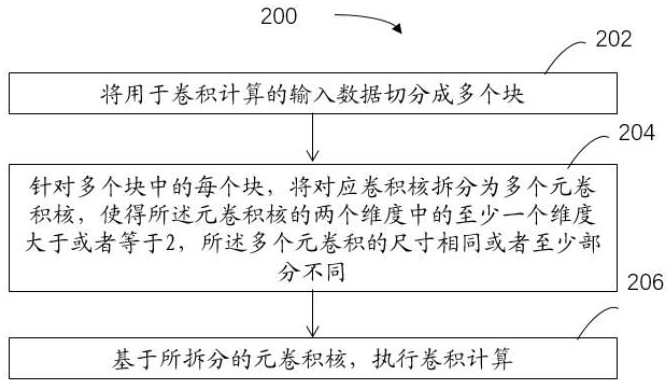
2、根据本发明的第一方面,提供了一种用于执行卷积计算的方法。该方法包括:将用于卷积计算的输入数据切分成多个块;针对多个块中的每个块,将对应卷积核拆分为多个元卷积核,使得所述元卷积核的两个维度中的至少一个维度大于或者等于2,所述多个元卷积的尺寸相同或者至少部分不同;以及基于所拆分的元卷积核,执行卷积计算。
3、根据本发明的第二方面,还提供了一种计算装置。该计算装置包括:至少一个处理器;以及与至少一个处理器通信连接的存储器;其中存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使计算装置能够执行本发明的第一方面的方法。
4、根据本发明的第三方面,还提供了一种计算机可读存储介质。该计算机可读存储介质上存储有计算机程序,计算机程序被机器执行时执行本发明的第一方面的方法。
5、根据本发明的第四方面,还提供了一种计算机程序产品,包括计算机程序,计算机程序被机器执行时执行本发明的第一方面的方法。
6、在一些实施例中,基于所拆分的元卷积核,执行卷积计算包括:针对每个块的每个元卷积核,生成对应的部分结果,以便针对多个元卷积核所分别对应的部分结果进行累加。
7、在一些实施例中,将对应卷积核拆分为多个元卷积核包括:基于对应卷积核尺寸、元卷积核集合所包括的多个参考元卷积核中的至少部分参考元卷积核,将所述对应卷积核拆分为多个元卷积核,元卷积核集合所包括的多个参考元卷积核的尺寸彼此不同。
8、在一些实施例中,用于执行卷积计算的方法还包括:至少基于脉动阵列的硬件参数,确定元卷积核集合所包括的多个参考元卷积核。
9、在一些实施例中,针对每个块的每个元卷积核,生成对应的部分结果包括:针对每个块的每个元卷积核,执行以下各项:加载元卷积核的分权重数据至通用矩阵乘计算单元的第二输入缓冲器;将与所加载的分权重数据对应的输入数据加载至通用矩阵乘计算单元的第一输入缓冲器;经由加速计算单元,利用卷积指令执行卷积计算,以便生成部分结果;以及将所生成的部分结果累加至缓冲器或者寄存器。
10、在一些实施例中,针对多个元卷积核所分别对应的部分结果进行累加包括:在将每个块的最后一个元卷积核的部分结果累加至缓冲器或者寄存器之后,将缓冲器或者寄存器的数据存储到高带宽存储器中。
11、在一些实施例中,用于执行卷积计算的方法还包括:获取跨行状态标识,所述跨行状态标识指示元卷积核的分权重数据对应的输入数据是否存在跨行状态、以及跨行位置。
12、在一些实施例中,经由加速计算单元,利用卷积指令执行卷积计算,以便生成部分结果包括:响应于确定所获取的跨行状态标识指示:与所加载的分权重数据对应的输入数据存在跨行,基于跨行状态标识和填充数据,在跨行位置处的像素数据设置掩码,以便利用包括掩码的对应的输入数据执行卷积计算,用以生成所述部分结果。
13、在一些实施例中,经由加速计算单元,利用卷积指令执行卷积计算,以便生成部分结果包括:响应于确定所获取的跨行状态标识指示:与所加载的分权重数据对应的输入数据存在跨行,基于跨行状态标识和填充数据,在跨行位置处的像素数据设置掩码,以便利用包括掩码的对应的输入数据执行卷积计算,以便生成所述部分结果。
14、在一些实施例中,针对每个块的每个元卷积核,生成对应的部分结果包括:针对每个块的每个元卷积核,执行以下各项:加载元卷积核的分权重数据至通用矩阵乘计算单元的第二输入缓冲器;响应于确定所获取的跨行状态标识指示:与所加载的分权重数据对应的输入数据存在跨行,将与所加载的分权重数据对应的输入数据加载至通用矩阵乘计算单元的第一输入缓冲器,而无需加载填补数据;基于跨行状态标识和填充数据,在跨行位置处的像素数据设置掩码,以便利用包括掩码的对应的输入数据执行卷积计算,以便生成部分结果;以及将所生成的部分结果累加至缓冲器或者寄存器。
15、应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种用于执行卷积计算的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,基于所拆分的元卷积核,执行卷积计算包括:
3.根据权利要求1所述的方法,其特征在于,将对应卷积核拆分为多个元卷积核包括:
4.根据权利要求3所述的方法,其特征在于,还包括:
5.根据权利要求2所述的方法,其特征在于,针对每个块的每个元卷积核,生成对应的部分结果包括:
6.根据权利要求5所述的方法,其特征在于,针对多个元卷积核所分别对应的部分结果进行累加包括:
7.根据权利要求5所述的方法,其特征在于,还包括:
8.根据权利要求7所述的方法,其特征在于,经由加速计算单元,利用卷积指令执行卷积计算,以便生成部分结果包括:
9.根据权利要求8所述的方法,其特征在于,利用包括掩码的对应的输入数据执行卷积计算,以便生成所述部分结果包括:
10.根据权利要求2所述的方法,其特征在于,针对每个块的每个元卷积核,生成对应的部分结果包括:
11.一种计算装置,其特征在于,包括:
12.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被机器执行时执行根据权利要求1-10中任一项所述的方法。
13.一种计算机程序产品,其特征在于,包括计算机程序,所述计算机程序被机器执行时执行根据权利要求1-10中任一项所述的方法。
技术总结
本发明涉及一种用于执行卷积计算的方法、计算装置、介质和程序产品。该方法包括:将用于卷积计算的输入数据切分成多个块;针对多个块中的每个块,将对应卷积核拆分为多个元卷积核,使得所述元卷积核的两个维度中的至少一个维度大于或者等于2,所述多个元卷积的尺寸相同或者至少部分不同;以及基于所拆分的元卷积核,执行卷积计算。本发明不仅能够降低访存次数,提高计算访存比,进而显著提升整体计算的性能,而且能够避免硬件电路限制而导致的卷积指令泛化度不足的问题。
技术研发人员:请求不公布姓名,请求不公布姓名,请求不公布姓名,请求不公布姓名,请求不公布姓名,请求不公布姓名,请求不公布姓名
受保护的技术使用者:北京壁仞科技开发有限公司
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!