一种专题语料发现新词的方法及系统与流程
本发明属于信息领域,主要是针对信息服务领域的一种专题语料发现新词的方法及系统。
背景技术:
1、随着时代的发展,我们会发现出现了很多在字典里没有定义过或者没有见过的词,这些词可能是缩略词,例如:扫盲、亚洲。有些也可能是旧词新用,例如:摆烂、吃瓜。目前传统的挖掘新词的方法是可以将这类词语挖掘出来的。大致步骤是将这些是先对一段长文本进行分段,然后根据词的词频、内部凝固程度和自由运用程度作为是否是一个新词的标准。
2、然而,随着服务领域的不断发展,产生了很多app名称,或很多场景专词,很显然,这些词语是需要作为新词挖掘出来的。但是,目前的传统方法识别率较低。因为传统算法足够严谨,挖掘新词标准单一,这些文章多次提到并重点标注的词却没有被挖掘出来,因此不能满足实际需求。现需要一种在传统的新词挖掘的方式下继续挖掘,既要查全又要查准的挖掘方法,做到让挖掘专题新词的脚步追上服务领域的发展速度。
技术实现思路
1、针对上述技术问题,本发明提供了一种专题语料发现新词的方法,实现高效、准确地提炼特定场景下的新词。
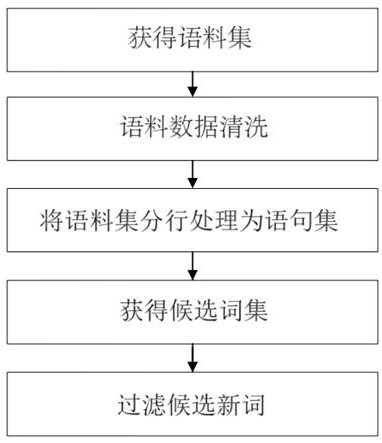
2、为达到上述目的,本发明采用的技术方案为,一种专题语料发现新词的方法,包括如下步骤:
3、s1、得到语料集:收集语料,对不同专题的语料进行分类;并对语料数据进行清洗。
4、s2、获取候选词集:对清洗后的语料数据进行分段处理,得到一批语句集;
5、将语句集输入到nagao算法模型中,生成多个候选词语;
6、基于规则库获得候选新词;
7、利用句法依存关系扩展组合成为候选新词;
8、将语句集输入到gector语法纠错算法中进行纠错,从获得的纠错建议中提取出候选新词:首先,原文文本text经过深度学习模型gector计算获得预测文本;其次,将预测文本经过屏蔽误纠层减少其中的误纠情况,得到结果文本;最后通过流畅度对比模型比较原文文本与结果文本的流畅度,选择流畅度较高的句子作为最后的结果。
9、s3、过滤候选词,过滤方法包括:
10、设置存储常用词的常用词词库、存储专题领域词的专题领域词库、存储禁用词的禁用词库;若候选词已经存在于常用词库或专题领域词库或禁用词库中,则进行过滤;
11、预设词长度限制过滤:词长度阈值为2-10;
12、常用词过滤:利用分词器进行分词,如果分词器对候选词分词分出两个及以上个数的词汇,则表示该候选词在词典中没有作为一个词,所以是常用词,需要进行过滤操作;
13、句法依存关系过滤:利用自然语言处理工具包识别出候选新词的句法依存关系,若候选新词中解析出来存在左附加关系、兼语、并列关系、独立结构,则过滤。
14、s4、过滤后的候选词添加至专题领域词库中。
15、进一步的,对不同专题的语料进行分类的方法是:
16、首先抓取训练语料数据,用文本分类器fasttext进行语料分类处理,训练文本分类模型;当需要处理收集的语料,在fasttext中设置不同专题的分类阈值,若语料经过fasttext处理后,分数小于阈值,则不分到对应专题下。
17、进一步的,分类后的剩余的语料,若不能放入现有分类的专题中,则待有新的专题分类时,继续处理剩余语料数据。
18、进一步的,语料数据清洗包括:清洗空白字符、繁体统一转化为简体中文、全角字符更换成半角字符、xml或html的文本格式转化;对于特殊字符等非中文字符、停用词,用自定义的字符替换。
19、进一步的,基于规则库提炼出的候选词只进行预设词长度限制过滤,不进行s3描述的过滤。
20、建立规则库,将符合规则库中规则的目标词提炼出来作为候选词;规则包括:获取包含书名号的候选词、获取包含双引号的候选词。对于一些活动方案、通知、专业类书籍都是用书名号标注;专题领域的相关文章对于服务app、发展规划纲要、理论、宣言等都标准化为用引号标注。因此可以将符合规则库中规则的词提炼出来作为挖掘出的候选新词。
21、进一步的,过滤候选词的方法还包括:
22、禁用词过滤包括:比较候选词和禁用词的词向量,根据词向量计算得到文本相似度,若结果超过0.8,则进行过滤操作;
23、预设过滤规则:预设特定字符串,过滤掉以特定字符串开始或结束的候选词。
24、过滤掉以特定字符串开始或结束的候选词,例如:“完善了”是很明显不能作为新词的,所以可以直接过滤掉。
25、本发明还公开一种专题语料发现新词的系统,包括:
26、语料集收集模块:收集语料,对不同专题的语料进行分类;并对语料数据进行清洗;
27、候选词集获取模块:对清洗后的语料数据进行分段处理,得到一批语句集;
28、将语句集输入到nagao算法模型中,生成多个候选词语;
29、基于规则库获得候选新词;
30、利用句法依存关系扩展组合成为候选新词;
31、将语句集输入到gector语法纠错算法中进行纠错,从获得的纠错建议中提取出候选新词;纠错方法为:首先,语句集原文文本text经过深度学习模型gector计算获得预测文本;其次,将预测文本经过屏蔽误纠层减少其中的误纠情况,得到结果文本;最后通过流畅度对比模型比较原文文本与结果文本的流畅度,选择流畅度较高的句子作为最后的结果;
32、候选词过滤模块,对候选词进行过滤,候选词过滤模块包括存储常用词的常用词词库、存储专题领域词的专题领域词库、存储禁用词的禁用词库;
33、候选词过滤模块的过滤方法包括:若候选词已经存在于常用词库或专题领域词库或禁用词库中,则进行过滤;
34、预设词长度限制过滤:词长度阈值为2-10;
35、常用词过滤:利用分词器进行分词,如果分词器对候选词分词分出两个及以上个数的词汇,则表示该候选词在词典中没有作为一个词,进行过滤操作;
36、句法依存关系过滤:利用自然语言处理工具包识别出候选新词的句法依存关系,若候选新词中解析出来存在左附加关系、兼语、并列关系、独立结构,则过滤;
37、过滤后的候选词添加至专题领域词库中。
38、综上,本发明相较于传统的挖掘新词的方法上具有以下有益效果:
39、1、在传统的挖掘基础上,通过句法依存关系扩展组合、基于规则库、获取并评估候选词和信息熵的方法扩大了新词的被发现的可能性,提高了挖掘新词的能力;
40、2、通过规范语料集的获取、清洗语料来提高挖掘出的专题新词的准确性;
41、3、通过常用词过滤、预设词长度限制、专题领域词过滤、禁用词过滤、预设过滤规则过滤提高了专题新词的可靠性,适应了特定服务领域的严谨性;
42、4、通过本方法下的挖掘方式、过滤方式,获得专题新词质量有着显著的提高,同时也大大减少了人工收集和整理专题新词的时间和工作成本;
43、5、专题词典越来越丰富,对后续的专题领域自然语言分析奠定良好的基础。
- 还没有人留言评论。精彩留言会获得点赞!