利用大模型进行推理的方法和电子设备与流程
本技术涉及大模型应用,尤其涉及一种利用大模型进行推理的方法和电子设备。
背景技术:
1、对于一个模型而言,在用该模型进行推理的时候会将待处理数据输入到模型中,与模型中的权重进行运算之后输出该待处理数据的推理结果。以一个人物识别模型为例,可以将一张图像输入到该人物识别模型,经过该人物识别模型对该输入图像进行处理之后,能够识别出该图像中的人。该识别过程就称之为推理过程,在模型推理的时候会进行权重矩阵与输入数据的运算。随着技术的发展,模型的规模和复杂度越来越高,大模型诞生,大模型具有更加精细和丰富的推理能力,但相对的,大模型的权重矩阵更加复杂,推理过程中的运算量也随之剧增,这就导致大模型的运算过程的时延过长。
2、因此如何提高大模型的计算效率,缩短大模型的推理时长是亟待解决的技术问题。
技术实现思路
1、本技术提供一种利用大模型进行推理的方法和电子设备,能够提高大模型的计算效率,缩短大模型的推理时长。
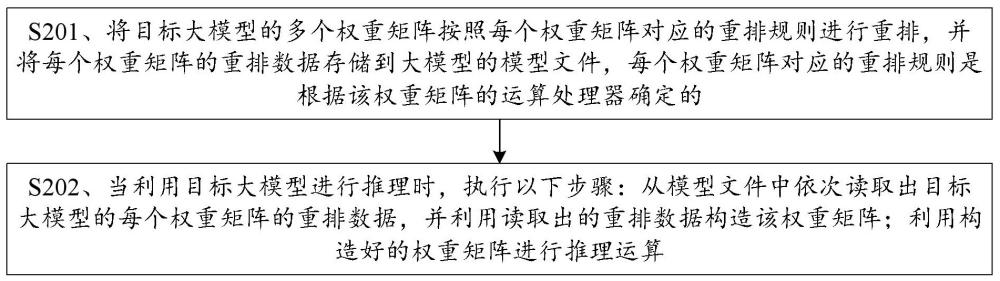
2、第一方面,提供了一种利用大模型进行推理的方法,该方法包括:将目标大模型的多个权重矩阵按照每个权重矩阵对应的重排规则进行重排,并将每个权重矩阵的重排数据存储到大模型的模型文件,每个权重矩阵对应的重排规则是根据该权重矩阵的运算处理器确定的;当利用目标大模型进行推理时,执行以下步骤:从模型文件中依次读取出目标大模型的每个权重矩阵的重排数据,并利用读取出的重排数据构造该权重矩阵;利用构造好的权重矩阵进行推理运算。
3、在本技术技术方案中,主要通过将大模型的权重矩阵按照其运算处理器(会利用该权重矩阵进行运算的处理器)所确定的重排规则进行重排之后存储,使得权重矩阵在重排后更加契合运算处理器的解析权重矩阵的规则和运算特性,从而在利用权重矩阵的重排数据进行运算的时候,能够更快速地得到计算时所需的权重矩阵,然后进行运算,也就是在推理阶段缩短了得到用于计算的权重矩阵的时长(可以理解为计算之前的准备工作的时长),从而缩短推理时长。还应理解,大模型的权重矩阵复杂,每个权重矩阵的数据量相对较大(矩阵维度较大),而且会涉及多种处理器都会参与运算的情况,而不同的处理器如何执行矩阵运算是有所差异的,所以为每个权重矩阵按照矩阵本身的特性和其运算处理器的运算特性设置重排规则进行重排,能够使得在推理过程中更快速地得到用于计算的权重矩阵,降低整体的推理时延。
4、应理解,对于普通的小模型,例如卷积神经网络模型、循环神经网络模型或其他普通神经网络模型或非神经网络模型而言,每个权重矩阵的数据量并不大(矩阵维度较小),数据格式大多为浮点型等其他数据类型,可以在线进行浮点型权重的重排(也就是推理阶段,每次读取之后先重排再计算)。这与本技术的大模型的4比特权重的重排所需方式并不相同,本技术的大模型的4比特权重,在计算之前还需要做更多的准备工作,导致了时延过长,所以才针对该问题,通过本技术所提供的方案,通过离线重排的方式(推理之前就先重排好并存储,在推理阶段就不需要再重排了),来缩短时延。所以上述这类可以在线重排即可的普通小模型不在本技术方案的考虑范围。简而言之,对于普通小模型,不存在因为读取和还原权重矩阵导致的时延过长的问题,所以没有利用本技术方案进行优化以缩短其时延的需求。
5、可以理解为,大模型的权重矩阵具有数据量大的特点,在端侧部署时需要进行4bit量化,直接存储权重进行推理或者在初始化时进行权重重排都会极大增加时延,也就是说,在推理阶段的计算之前读取数据和利用读取数据构造权重矩阵的时长过长,导致整个推理时长变长。针对该问题,本技术提供了一种新的推理方法,通过先将权重矩阵以更加契合处理器的解析权重矩阵的规则和运算特性的方式重新排布和存储(离线重排和存储),使得一旦推理运算被触发,推理框架能更快速地得到计算所需的权重矩阵,缩短了解析数据(对读取出的数据进行预处理来得到计算所需的权重)的时长,提高了运算效率,进而缩短了整个推理运算过程的时长。相当于通过前期准备(重排之后存储),使得在需要用到权重矩阵的时候,在更短的时间准备好用于计算的权重矩阵。
6、结合第一方面,在第一方面的某些实现方式中,当目标大模型的运算处理器包括中央处理单元(cpu)时,将目标大模型的多个权重矩阵按照每个权重矩阵对应的重排规则进行重排,并将每个权重矩阵的重排数据存储到大模型的模型文件,包括:按照cpu解析权重矩阵的规则和运算特性,确定第一权重矩阵的切分规则,切分规则包括切分单位和切分次序,切分单位用于指示切分出的子矩阵的大小,第一权重矩阵为目标大模型的多个权重矩阵中运算处理器为cpu的权重矩阵;按照切分次序并根据切分单位,将第一权重矩阵切分为多个第一子矩阵,每个第一子矩阵对应一个切分单位;按照预设排布策略将每个第一子矩阵中的数据进行重新排布,得到第二子矩阵;将每个第二子矩阵写入模型文件,写入到模型文件的第一权重矩阵对应的所有第二子矩阵的数据构成第一权重矩阵对应的重排数据。对于cpu负责处理的权重矩阵,除了会切分矩阵之外,还会按照预设的排布策略将每个切分出的矩阵中的数据进行重新排布,使得重新排布之后的矩阵在推理阶段更容易解析出权重矩阵。切分规则和预设排布策略都是为了使得重排数据后续在推理的时候能更快速地解析出权重矩阵。
7、结合第一方面,在第一方面的某些实现方式中,在按照cpu解析权重矩阵的规则和运算特性,确定第一权重矩阵的切分规则时,可以包括:按照cpu的读取指令的一次读取的最大数据量、将重排数据解析成计算所需的权重矩阵时所耗费的指令数和矩阵外积计算时的分块大小,确定切分规则。cpu是有特定的解析权重矩阵的规则和运算规则的,所以为了方便存储和后续的快速读取和还原矩阵,会综合cpu的这些规则来确定出将权重矩阵切分成多大更合适以及确定出按照什么样的次序切分更合适。
8、结合第一方面,在第一方面的某些实现方式中,切分次序为交替地先沿行方向切分后沿列方向切分的切分次序。该切分次序也是根据cpu存储和读取数据的规则确定的,以契合cpu的存储和读取需求。交替地先沿行方向切分后沿列方向切分,包括:先沿行方向,按照切分单位依次取值得到小矩阵(第一子矩阵),等一行全都取值完毕后,沿列方向按照切分单元下移一行,再次重复沿行方向按照切分单位依次取值得到第一子矩阵直到这一行都取值完毕的步骤,之后再次重复沿列方向按照切分单元下移一行的步骤,以此类推,直到将整个权重矩阵取值完毕。
9、结合第一方面,在第一方面的某些实现方式中,第一权重矩阵的行数是n1的倍数,切分单位为n1行n2列,n1和n2均为正整数;n1和n2是根据cpu解析权重矩阵的规则和运算特性以及目标大模型的每个权重参数的数据大小确定的;预设排布策略为将第一子矩阵中的每一行的数据按照预设间隔交替排布。在这种实现方式中,除了按照上述的cpu解析权重矩阵的规则和运算特性来确定切分单位之外,还考虑了目标大模型的每个权重参数的数据大小,使得切分单位更加合理,预设排布策略则是根据cpu的运算规则和切分单位的大小来确定出的,按照将第一子矩阵中的每行数据按照预设间隔交替排布的方式重新排布。
10、结合第一方面,在第一方面的某些实现方式中,当目标大模型的运算处理器包括图形处理器(gpu)时,将目标大模型的多个权重矩阵按照每个权重矩阵对应的重排规则进行重排,并将每个权重矩阵的重排数据存储到大模型的模型文件,包括:按照gpu的运算规则,确定多个备选重排规则,每个备选重排规则中包括取值单位和取值次序;根据第二权重矩阵的结构,从多个备选重排规则中确定出第二权重矩阵对应的目标重排规则,第二权重矩阵为目标大模型的多个权重矩阵中运算处理器为gpu的权重矩阵;根据目标重排规则所指示的取值次序,按照目标重排规则所指示的取值单位,依次对第二权重矩阵取值之后,写入模型文件,写入到模型文件的第二权重矩阵对应的所有数据构成第二权重矩阵对应的重排数据。对于gpu负责处理的权重矩阵,会先按照gpu的特性确定几个备选重排规则,再根据权重矩阵自身的结构来从中选出最合适的重排规则,使得对权重矩阵进行分块和存储后,更加契合gpu矩阵计算的分块及并行处理的特性,从而在推理阶段能够在读取出重排数据之后直接进行运算,并且可以确保gpu的计算效率。
11、结合第一方面,在第一方面的某些实现方式中,上述方法还包括:在取值过程中,当第二权重矩阵的大小不是取值单位的大小的整数倍时,对于第二子矩阵中的空缺部分用填充数据进行填充,第二子矩阵的大小对应一个取值单位,第二子矩阵中除了包括第二权重矩阵的数据之外还包括空缺部分。由于gpu负责处理的权重矩阵的大小会有多种情况,可能会出现取值单位不能整除权重矩阵的大小的情况,可能是取值单位的行数不能整除权重矩阵的行数,也可能是取值单位的列数不能整除权重矩阵的列数,或者可能是行和列都不能整除。或者理解为权重矩阵的大小不是取值单位的大小的整数倍。在这种情况下,就需要对于边缘的取值进行填充。简而言之,当不是整数倍关系的时候,第二权重矩阵的边缘处的取值会出现无法取满整个取值单位的量的情况,此时对于空缺部分可以用填充数据进行填充。填充数据可以是固定数值,为了方式对于其他数据造成干扰,填充数据可以设置为零。
12、结合第一方面,在第一方面的某些实现方式中,取值次序可以为:沿列方向对第二权重矩阵中取值单位对应的第i列取值,直到第i列取值完毕后,沿行方向按照取值单位平移一列,到第二权重矩阵中取值单位对应的第i+1列;沿列方向对第i+1列取值,直到第i+1列取值完毕后,沿行方向按照取值单位平移一列;以此类推,直到将第二权重矩阵的所有数据都取值完毕,i为正整数。可以看出,gpu的取值次序是交替地先沿列方向后沿行方向的交替取值次序。这是为了契合gpu的运算规则。
13、结合第一方面,在第一方面的某些实现方式中,每个备选取值规则的取值单位的数据量相同;多个备选取值规则中至少有两个备选取值规则的取值单位的大小不同。为gpu提供多个数据量相同但大小不同的取值单位,能够方便对不同的权重矩阵进行取值,数据量相同能够保证每次取值指令取出的数据量固定,大小不同则可以更契合不同的权重矩阵的结构。取值单位的数据量会受到gpu的读取指令(例如opencl image指令)的影响。
14、结合第一方面,在第一方面的某些实现方式中,在根据第二权重矩阵的结构,从多个备选重排规则中确定出第二权重矩阵对应的目标重排规则时,可以包括:按照最快推理速度原则,从多个备选重排规则中确定出目标重排规则。重排规则会影响gpu计算时矩阵的分块大小及其并行程度,从而影响计算速度,也就是说,采用不同的重排规则会对应不同的计算速度,因此按照最快推理速度来确定重排规则能选择出更适合进行推理运算的重排规则,进一步提高运算效率。也就是说,在这种实现方式中,可以根据gpu的运算规则来推算每个备选重排规则下的分块大小和并行程度,从而推算出每个备选重排规则对应的gpu计算速度,并将所有备选重排规则中,gpu计算速度最快(即满足最快推理速度)的备选重排规则确定为目标重排规则。
15、结合第一方面,在第一方面的某些实现方式中,目标大模型的每个权重参数的数据大小为4比特(bit)。这种实现方式是可以更好地匹配现有的量化大模型的方式,使得整个权重矩阵的重排更加契合经过量化的大模型。
16、第二方面,提供了一种执行利用大模型进行推理的装置,该装置包括由软件和/或硬件组成的用于执行第一方面的任意一种方法的单元。
17、第三方面,提供了一种电子设备,所述电子设备包括:一个或多个处理器,以及存储器;
18、所述存储器与所述一个或多个处理器耦合,所述存储器用于存储计算机程序代码,所述计算机程序代码包括计算机指令,所述一个或多个处理器调用所述计算机指令以使得所述电子设备能够实现第一方面的任意一种方法。
19、第四方面,提供了一种芯片系统,所述芯片系统应用于电子设备,所述芯片系统包括一个或多个处理器,所述一个或多个处理器用于调用计算机指令以使得所述电子设备能够实现第一方面的任意一种方法。
20、可选地,该芯片系统还包括存储器,存储器与处理器电连接。
21、可选地,该芯片系统还可以包括通信接口。
22、第五方面,提供了一种计算机可读存储介质,所述计算机可读存储介质包括指令,当所述指令在电子设备上运行时,使得所述电子设备能够实现第一方面的任意一种方法。
23、第六方面,提供了一种计算机程序产品,该计算机程序产品包括计算机程序,当计算机程序被电子设备执行时能够实现第一方面的任意一种方法。
- 还没有人留言评论。精彩留言会获得点赞!