文本聚类方法、装置及存储介质与流程
本技术涉及自然语言处理领域,尤其涉及一种文本聚类方法、装置及存储介质。
背景技术:
1、目前,云计算服务和软件服务等各类业务场景中,一般可以采用聚类算法对业务相关的大量历史工单进行处理,得到相关参考经验以用作处理业务中后续出现的问题。
2、通用技术中聚类算法不能灵活地对不同类别的工单数据进行处理,且容易陷入局部最优,从而导致生成的聚类结果准确度较低。
技术实现思路
1、本技术提供一种文本聚类方法、装置及存储介质,能够准确地对文本进行聚类。
2、为达到上述目的,本技术采用如下技术方案:
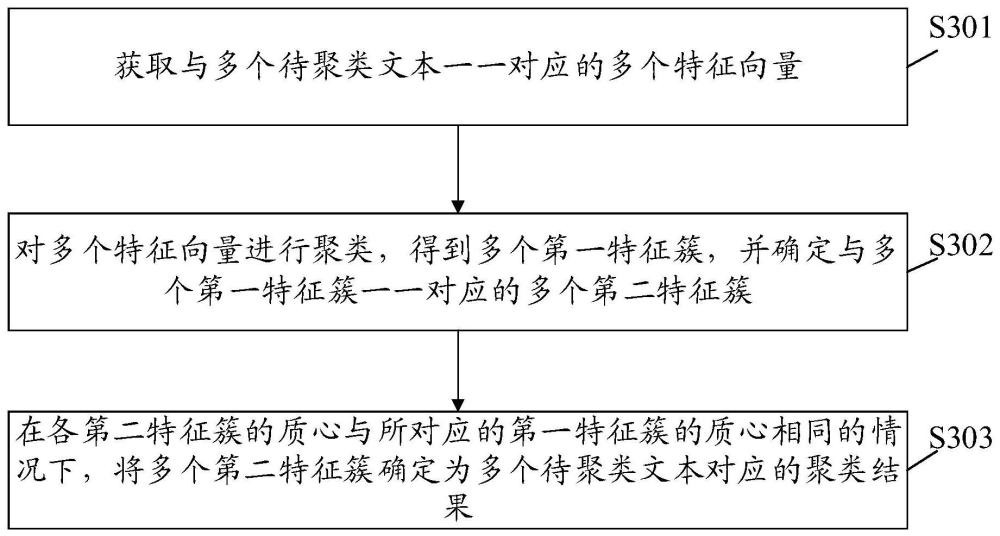
3、第一方面,本技术提供一种文本聚类方法,该方法包括:获取与多个待聚类文本一一对应的多个特征向量;对多个特征向量进行聚类,得到多个第一特征簇,并确定与多个第一特征簇一一对应的多个第二特征簇;第二特征簇所包括的特征向量对应的第一距离小于第二距离,第一距离用于表示第二特征簇所包括的特征向量与第二特征簇对应的第一特征簇的质心之间的距离,第二距离用于表示第二特征簇所包括的特征向量与其他第一特征簇的质心之间的距离;在各第二特征簇的质心与所对应的第一特征簇的质心相同的情况下,将多个第二特征簇确定为多个待聚类文本对应的聚类结果。
4、一种可能的方式中,获取与多个待聚类文本一一对应的多个特征向量,包括:确定各待聚类文本所包括的多个词语中每个词语的特征权重;将特征权重大于预设权重阈值的词语,确定为特征词,得到多个特征词;将多个特征词输入至目标生成模型进行生成处理,得到与多个特征词一一对应的多个词向量;根据多个特征权重,对多个词向量进行加权处理,得到与多个词向量一一对应的多个加权后词向量,并将多个加权后词向量组成的集合,确定为特征向量。
5、一种可能的方式中,确定各待聚类文本所包括的多个词语中每个词语的特征权重,包括:确定各待聚类文本所包括的多个词语中每个词语的词频,得到与待聚类文本一一对应的词频集合;增加多个词语中标签词的词频,得到增加后词频集合;根据增加后词频集合,确定与多个词语一一对应的多个特征权重。
6、一种可能的方式中,获取训练数据;训练数据包括多个样本集合,不同样本集合所包括的样本文本对应的业务类别不同;通过训练数据,对初始训练模型进行训练,得到目标生成模型。
7、一种可能的方式中,确定各待聚类文本所包括的多个词语中每个词语的特征权重之前,还包括:
8、对各待聚类文本进行分词和/或去除停用词处理。一种可能的方式中,在各第二特征簇的质心与所对应的第一特征簇的质心相同的情况下,方法,还包括:确定与第一特征簇对应的第一轮廓系数,以及与第二特征簇对应的第二轮廓系数;在第一轮廓系数大于第二轮廓系数的情况下,将第一特征簇确定为多个待聚类文本对应的聚类结果;在第二轮廓系数大于第一轮廓系数的情况下,将第二特征簇确定为多个待聚类文本对应的聚类结果。
9、一种可能的方式中,在各第二特征簇的质心与所对应的第一特征簇的质心不相同的情况下,确定与多个第二特征簇一一对应的多个第三特征簇;第三特征簇所包括的特征向量对应的第三距离小于第四距离,第三距离用于表示第三特征簇所包括的特征向量与第三特征簇对应的第二特征簇的质心之间的距离,第四距离用于表示第三特征簇所包括的特征向量与其他第二特征簇的质心之间的距离。
10、第二方面,本技术提供一种文本聚类装置,该装置包括:获取单元和确定单元;获取单元,用于获取与多个待聚类文本一一对应的多个特征向量;确定单元,用于对多个特征向量进行聚类,得到多个第一特征簇,并确定与多个第一特征簇一一对应的多个第二特征簇;第二特征簇所包括的特征向量对应的第一距离小于第二距离,第一距离用于表示第二特征簇所包括的特征向量与第二特征簇对应的第一特征簇的质心之间的距离,第二距离用于表示第二特征簇所包括的特征向量与其他第一特征簇的质心之间的距离;确定单元,还用于在各第二特征簇的质心与所对应的第一特征簇的质心相同的情况下,将多个第二特征簇确定为多个待聚类文本对应的聚类结果。
11、一种可能的方式中,获取单元,具体用于:确定各待聚类文本所包括的多个词语中每个词语的特征权重;将特征权重大于预设权重阈值的词语,确定为特征词,得到多个特征词;将多个特征词输入至目标生成模型进行生成处理,得到与多个特征词一一对应的多个词向量;根据多个特征权重,对多个词向量进行加权处理,得到与多个词向量一一对应的多个加权后词向量,并将多个加权后词向量组成的集合,确定为特征向量。
12、一种可能的方式中,获取单元,还用于:确定各待聚类文本所包括的多个词语中每个词语的词频,得到与待聚类文本一一对应的词频集合;增加多个词语中标签词的词频,得到增加后词频集合;根据增加后词频集合,确定与多个词语一一对应的多个特征权重。
13、一种可能的方式中,装置还包括:训练单元;获取单元,还用于获取训练数据;训练数据包括多个样本集合,不同样本集合所包括的样本文本对应的业务类别不同;训练单元,用于通过训练数据,对初始训练模型进行训练,得到目标生成模型。
14、一种可能的方式中,装置还包括:处理单元;处理单元,用于对各待聚类文本进行分词和/或去除停用词处理。
15、一种可能的方式中,确定单元,还用于确定与第一特征簇对应的第一轮廓系数,以及与第二特征簇对应的第二轮廓系数;确定单元,还用于在第一轮廓系数大于第二轮廓系数的情况下,将第一特征簇确定为多个待聚类文本对应的聚类结果;确定单元,还用于在第二轮廓系数大于第一轮廓系数的情况下,将第二特征簇确定为多个待聚类文本对应的聚类结果。
16、一种可能的方式中,确定单元,还用于在各第二特征簇的质心与所对应的第一特征簇的质心不相同的情况下,确定与多个第二特征簇一一对应的多个第三特征簇;第三特征簇所包括的特征向量对应的第三距离小于第四距离,第三距离用于表示第三特征簇所包括的特征向量与第三特征簇对应的第二特征簇的质心之间的距离,第四距离用于表示第三特征簇所包括的特征向量与其他第二特征簇的质心之间的距离。
17、第三方面,本技术提供了一种文本聚类装置,该装置包括:处理器和通信接口;通信接口和处理器耦合,处理器用于运行计算机程序或指令,以实现如第一方面和第一方面的任一种可能的实现方式中所描述的文本聚类方法。
18、第四方面,本技术提供了一种计算机可读存储介质,计算机可读存储介质中存储有指令,当指令在终端上运行时,使得终端执行如第一方面和第一方面的任一种可能的实现方式中描述的文本聚类方法。
19、第五方面,本技术实施例提供一种包含指令的计算机程序产品,当计算机程序产品在文本聚类装置上运行时,使得文本聚类装置执行如第一方面和第一方面的任一种可能的实现方式中所描述的文本聚类方法。
20、第六方面,本技术实施例提供一种芯片,芯片包括处理器和通信接口,通信接口和处理器耦合,处理器用于运行计算机程序或指令,以实现如第一方面和第一方面的任一种可能的实现方式中所描述的文本聚类方法。
21、具体的,本技术实施例中提供的芯片还包括存储器,用于存储计算机程序或指令。
22、在本技术中,上述文本聚类装置的名字对设备或功能模块本身不构成限定,在实际实现中,这些设备或功能模块可以以其他名称出现。只要各个设备或功能模块的功能和本技术类似,属于本技术权利要求及其等同技术的范围之内。
23、本技术的这些方面或其他方面在以下的描述中会更加简明易懂。
24、基于上述任一方面,本技术提供的技术方案至少带来以下有益效果:
25、获取与多个待聚类文本一一对应的多个特征向量之后,可以对多个特征向量进行聚类,得到多个第一特征簇,并计算得到多个第一特征簇的质心,然后将多个特征向量分配至距离最近的质心所在的第一特征簇中,得到与多个第一特征簇一一对应的多个第二特征簇,以进一步将在各第二特征簇的质心与所对应的第一特征簇的质心相同的情况下,将多个第二特征簇确定为多个待聚类文本对应的聚类结果。
26、基于此,本技术能够在对多个待聚类文本进行初始聚类的基础上,通过迭代修正的方式,使得聚类结果“簇内差异小,簇外差异大”,从而灵活地对不同类别的工单数据进行处理,且能够通过多次迭代,避免聚类结果陷入局部最优。因此,本技术能够准确地对文本进行聚类。
- 还没有人留言评论。精彩留言会获得点赞!