基于人工智能的企业供应链交易风险预测方法及系统与流程
本发明涉及风险预测,具体是指基于人工智能的企业供应链交易风险预测方法及系统。
背景技术:
1、现代企业的供应链交易风险管理对于企业的长期发展至关重要。随着信息技术的不断发展和智能化的进步,人工智能技术逐渐应用于企业的供应链交易风险预测中,为企业提供更准确、可靠的风险评估和预测信息,帮助企业在风险较高的环境中做出更精确的决策。但是一般企业供应链交易风险预测方法存在单一相似度度量导致数据挖掘不足,相似性测量侧重于根据数值距离来测量曲线的相似性而忽略曲线形状的变化特征,在对区间值函数数据进行聚类时导致聚类结果不合理的问题;一般聚类中心选取不当导致不同簇之间的区别性低,搜索聚类中心方法随机性不足,搜索策略适应性低的问题。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了基于人工智能的企业供应链交易风险预测方法及系统,针对一般企业供应链交易风险预测方法存在单一相似度度量导致数据挖掘不足,相似性测量侧重于根据数值距离来测量曲线的相似性而忽略曲线形状的变化特征,在对区间值函数数据进行聚类时导致聚类结果不合理的问题,本方案通过推导基函数和导数信息下区间函数欧几里得距离的具体计算公式,基于基函数的距离反映数值的绝对差值,根据导数函数信息的距离反映曲线形状差,构建了数值距离和曲线形状相结合的相似度度量方法,使得聚类结果具有更高的稳定性、表现力和精准性;针对一般聚类中心选取不当导致不同簇之间的区别性低,搜索聚类中心方法随机性不足,搜索策略适应性低的问题,本方案通过使用相邻三次将数据点作为初始聚类中心得到的聚类结果评估值的平均值作为适应度值,可以更好地捕捉聚类中心的稳定性;移动策略考虑了全局最优个体和随机参数,提高搜索的效率和局部最优解的发现;从而提高搜索的效率和聚类结果的质量。
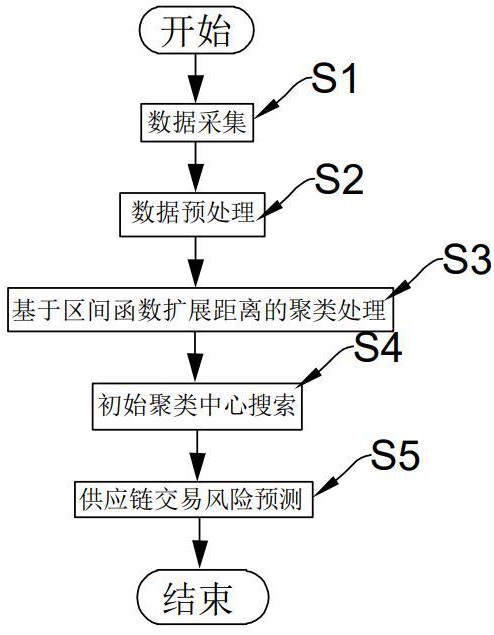
2、本发明采取的技术方案如下:本发明提供的基于人工智能的企业供应链交易风险预测方法,该方法包括以下步骤:
3、步骤s1:数据采集;
4、步骤s2:数据预处理;
5、步骤s3:基于区间函数扩展距离的聚类处理;
6、步骤s4:初始聚类中心搜索;
7、步骤s5:供应链交易风险预测。
8、进一步地,在步骤s1中,所述数据采集是采集历史供应链交易数据、历史供应商评估数据、历史产品信息、历史市场数据、历史宏观经济数据和历史供应链交易风险;
9、所述历史供应链交易数据包括订单数量、交易金额和交易日期;所述历史供应商评估数据包括供应商的信用评级、供应商历史交易记录和供应商财务状况;所述历史产品信息包括产品的分类、产品的质量评估和产品的价格;所述历史市场数据包括市场需求和市场竞争情况;所述历史宏观经济数据包括通货膨胀率、利率和汇率。
10、进一步地,在步骤s2中,所述数据预处理是对采集的数据进行数据清洗、数据转换、标准化处理和构建区间值函数数据集;所述数据清洗是对采集的数据进行缺失值处理、异常值处理和重复值处理;所述数据转换是基于特征编码将清洗后的数据转换为向量形式;所述数据标准化是对转换后的数据基于min-max缩放进行标准化处理;所述构建区间值函数数据集是将供应链交易风险划分为低、中、高三个区间,并为每个区间分配风险等级;将标准化处理后的特征向量与目标变量区间和风险等级相结合,构建区间值函数数据集。
11、进一步地,在步骤s3中,所述基于区间函数扩展距离的聚类处理具体包括以下步骤:
12、步骤s31:定义区间函数扩展距离,区间函数扩展距离前半部分提取了区间值函数的信息,以在数值距离上度量函数曲线的相似性,而后半部分提取了上下限函数的导数函数信息,以反映函数曲线在曲线形状上的相似性;通过结合这两者,旨在考虑区间值函数的数值距离和形态特征考虑区间值函数的数值信息、曲线形状之间的相似性和区间值函数的欧几里得距离;获取了区间值函数的下限函数和上限函数的导数函数信息;结合原始函数和导数函数信息得到区间函数扩展距离,表示如下:
13、;
14、式中,是第i个区间值函数样本和第j个区间值函数样本之间在时间点t的区间函数扩展距离;t是时间变量;和分别是第i个区间值函数样本在时间点t的下限函数和上限函数;和分别是第j个区间值函数样本在时间点t的下限函数和上限函数;和分别是和在时间点t的一阶导数函数,表示区间值函数样本下限函数的变化速率;和分别是和在时间点t的一阶导数函数,表示区间值函数样本上限函数的变化速率;
15、步骤s32:初始簇质心建立,对于所有区间值函数数据样本x(t),计算任意两个区间值函数样本的区间函数扩展距离;将具有最大区间函数扩展距离的两个区间值函数样本作为初始聚类中心,标记为和;计算其他区间值函数样本到现有聚类中心和的距离之和;距离之和最大的区间值函数样本被选为第三个初始聚类中心,表示为;类似地,通过循环得到所有初始聚类中心和聚类数目:;
16、步骤s33:数据点分配;计算每个区间值函数样本到聚类中心的距离;根据距离最小原则分配数据点;在第m次迭代中,第i个区间值函数样本的簇表示为:
17、;
18、式中,是第i个区间值函数样本第m次迭代时所属簇;表示m-1次迭代时簇s的质心;s是簇的索引,k是簇的数量;
19、步骤s34:聚类中心更新;将簇中距离所有样本的均值最近的数据点作为新的聚类中心;在第m次迭代中,新的聚类中心可以表示如下:
20、;
21、式中,是第m次迭代第s个簇的质心;表示分配给第s个聚类的区间值函数样本的个数;
22、步骤s35:群集结果确定;重复步骤s33和s34,直到质心保持不变;
23、步骤s36:评估聚类结果,考虑类内样本的相似度以及类间样本的差异度,表示如下:
24、;
25、式中,pg是聚类评估指数;n是类别数量;和分别是第i个类别和第j个类别中数据点的平均区间函数扩展距离;是第i个类别和第j个类别中数据点的区间函数扩展距离和;
26、步骤s37:分配簇标签,将供应链交易风险等级作为标签维度,将具有最多数量样本数据的供应链交易风险等级作为簇标签。
27、进一步地,在步骤s4中,所述初始聚类中心搜索是预先设有适应度阈值,当步骤s3得到的聚类评估指数高于适应度阈值时,采用搜索策略搜索初始聚类中心,具体包括以下步骤:
28、步骤s41:初始化聚类中心,基于数据样本空间确定参数搜索空间,随机选取一组样本数据点作为初始聚类中心点,每个数据点的适应度值是相邻三次将该数据点作为初始聚类中心得到的聚类结果评估值的平均值;将10%数量的适应度值最低的数据点作为随机组,其余数据点为搜索组;移动时采用就近策略,搜索到的数据点是距离移动后位置最近的数据点;
29、步骤s42:定义随机组移动策略,随机组个体注重搜索的随机性,移动时只考虑全局最优个体和随机参数,所用公式如下:
30、;
31、;
32、式中,r是随机参数,随着迭代次数的增加而减小;d是维度大小;t是当前迭代次数,tmax是最大迭代次数;和分别是第t+1次迭代和第t次迭代时第i个随机组个体位置;是全局最优个体位置;rand(0,1)是0到1范围内的随机数;
33、步骤s43:定义搜索组移动策略,搜索组个体根据其历史位置和种群最优位置进行更新,所用公式如下:
34、;
35、;
36、式中,xrand是随机个体;和分别是第t+1次迭代和第t次迭代时第i个搜索组个体位置;f(·)是适应度值函数;是个体历史最优位置;θ是0到360之间的随机数;
37、步骤s44:搜索判定,若当前搜索到的初始聚类中心适应度值低于适应度阈值,则输出搜索到的初始聚类中心;若达到最大迭代次数,则重新初始化聚类中心并搜索;否则继续移动位置搜索。
38、进一步地,在步骤s5中,所述供应链交易风险预测是实时采集供应链交易数据、供应商评估数据、产品信息、市场数据和宏观经济数据作为实时数据;将步骤s1采集的数据作为历史数据;将实时数据和历史数据共同参与聚类,将聚类后实时数据对应的簇标签作为企业供应链交易风险预测结果。
39、本发明提供的基于人工智能的企业供应链交易风险预测系统,包括数据采集模块、数据预处理模块、聚类处理模块、初始聚类中心搜索模块和供应链交易风险预测模块;
40、所述数据采集模块采集历史供应链交易数据、历史供应商评估数据、历史产品信息、历史市场数据、历史宏观经济数据和历史供应链交易风险,并将数据发送至数据预处理模块;
41、所述数据预处理模块对采集的数据进行数据清洗、数据转换、标准化处理和构建区间值函数数据集,并将数据发送至聚类处理模块;
42、所述聚类处理模块是结合原始函数和导数函数信息定义区间函数扩展距离,通过初始簇质心建立、数据点分配和聚类中心更新完成聚类;并将数据发送至初始聚类中心搜索模块;
43、所述初始聚类中心搜索模块基于初始化聚类中心和定义适应度值,定义随机组移动策略和搜索组移动策略实现聚类中心搜索,并将数据发送至供应链交易风险预测模块;
44、所述供应链交易风险预测模块实时采集供应链交易数据、供应商评估数据、产品信息、市场数据和宏观经济数据作为实时数据,基于聚类结果实现供应链交易风险预测。
45、采用上述方案本发明取得的有益效果如下:
46、(1)针对一般企业供应链交易风险预测方法存在单一相似度度量导致数据挖掘不足,相似性测量侧重于根据数值距离来测量曲线的相似性而忽略曲线形状的变化特征,在对区间值函数数据进行聚类时导致聚类结果不合理的问题,本方案通过推导基函数和导数信息下区间函数欧几里得距离的具体计算公式,基于基函数的距离反映数值的绝对差值,根据导数函数信息的距离反映曲线形状差,构建了数值距离和曲线形状相结合的相似度度量方法,使得聚类结果具有更高的稳定性、表现力和精准性。
47、(2)针对一般聚类中心选取不当导致不同簇之间的区别性低,搜索聚类中心方法随机性不足,搜索策略适应性低的问题,本方案通过使用相邻三次将数据点作为初始聚类中心得到的聚类结果评估值的平均值作为适应度值,可以更好地捕捉聚类中心的稳定性;移动策略考虑了全局最优个体和随机参数,提高搜索的效率和局部最优解的发现;从而提高搜索的效率和聚类结果的质量。
- 还没有人留言评论。精彩留言会获得点赞!