基于协同学习的头部姿态估计方法
本发明属于计算机视觉领域,具体涉及一种头部姿态估计方法,可用于疲劳驾驶检测、智慧课堂行为分析、人机交互。
背景技术:
1、头部姿态估计旨在基于给定的面部图像预测头部的姿态角度,即仰俯角、偏航角、翻滚角。随着计算机视觉的发展,衍生出许多实现头部姿态估计的研究方法,这些方法可以分为两大类:无关键点的方法和基于关键点的方法。
2、无关键点的方法,采用数据驱动网络进行图像到姿态角的学习,由于其不提取面部标志信息,而面部标志信息是多任务应用程序中多个下游任务需要的重要中间结果,因而限制了该方法的应用。
3、基于关键点的方法,首先检测人脸关键点,然后建立这些关键点和姿态角的对应关系,从而训练姿态角,其为目前比较广泛应用的实现头部姿态估计的方法。
4、miao xin等人在2021年cvpr上发表的题为eva-gcn:head pose estimationbased on graph convolutional networks的文章中,将头部姿态估计视为图回归问题,构建了一个地标连接图,利用图卷积网络对图类型和头部姿态角之间的复杂非线性映射进行建模,在图卷积网络中引入联合边缘顶点注意力机制,以提高人脸关键点检测的稳定性,进而提升了头部姿态的估计精度。但该方法由于仅探究了人脸关键点到头部姿态角的单向关系,导致姿态角的估计精度只能依赖于关键点位置的正确预测,造成较差的关键点定位很容易影响头部姿态估计的精确性。
5、申请号为202310708997.5的中国专利文献公开了一种在线考试异常行为检测方法,该方法将考试视频信息转换为图像后,通过人脸检测算法和人眼检测算法分析图像,再利用训练好的头部姿态估计模型进行分析,基于对在线考试考生的头部姿态的准确估计,为后续异常行为检测算法提供基础。该方法由于其头部姿态估计模型,依赖于提前检测到的感兴趣区域,这意味着需要一个前置串行人脸检测器,因而在教室这样多人的场景下,即使是最轻量化的人脸检测器也会减缓整个前向推理时间,使得检测多人的头部姿态时推理时间较长,检测效率较低。
技术实现思路
1、本发明的目的在于针对上述现有技术的不足,提出一种基于协同学习的头部姿态估计方法,以提高头部姿态角的估计精度,同时在多人场景下,缩短头部姿态估计时间,提高检测效率。
2、实现本发明的技术思路是:利用人脸关键点和头部姿态角之间的对应关系,构建人脸关键点到头部姿态角、头部姿态角到人脸关键点学习模块,并进行协同学习,以提高头部姿态角的估计精度;通过将人脸的热图特征在人脸关键点生成、头部姿态预测等多任务中共享,避免了人脸的热图特征的多次提取,以缩短头部姿态的估计时间,提高检测效率。
3、根据上述思路,本发明的技术方案包括如下:
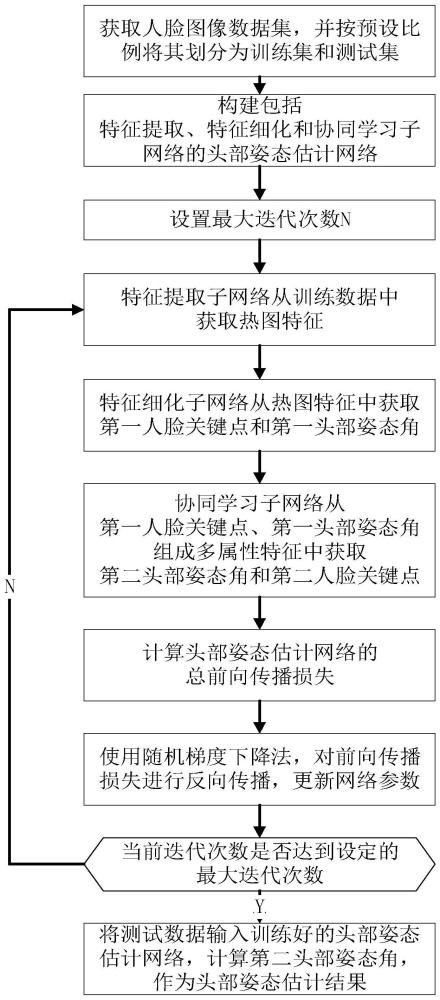
4、1)从公开网站获取人脸图像数据集,并按预设比例将其划分为训练数据集和测试数据集,数据集中的每幅图像均包含人脸关键点和头部姿态角真值;
5、2)构建头部姿态估计网络:
6、建立包括特征提取模块、区域生成模块、上采样模块和热图生成模块的特征提取子网络;
7、建立包括人脸关键点热图模块和头部姿态初步预测模块的特征细化子网络;
8、建立包括姿态角模块和人脸关键点模块的协同学习子网络;
9、将特征提取子网络、特征细化子网络和协同学习子网络依次级联构成头部姿态估计网络;
10、3)对头部姿态估计网络进行训练:
11、3a)设置最大迭代次数n;
12、3b)将训练数据输入特征提取子网络,得到热图特征h;
13、3c)将热图特征h共享给特征细化子网络中的人脸关键点热图模块和头部姿态初步预测模块,分别得到第一人脸关键点k1和第一头部姿态角e1;
14、3d)用第一人脸关键点k1、第一头部姿态角e1组成多属性特征,输入到协同学习子网络,通过姿态角模块输出第二头部姿态角e2,通过人脸关键点模块输出第二人脸关键点k2;
15、3e)计算头部姿态估计网络的总前向传播损失l=l1+l2+l3,其中,l1、l2、l3分别为特征提取子网络、特征细化子网络和协同学习子网络的损失函数;
16、3f)使用随机梯度下降法,对总前向传播损失l进行反向传播,更新网络参数w;
17、3g)判断当迭代次数是否达到设定的最大迭代次数n:
18、若达到,则停止更新网络参数w,获得训练好的头部姿态估计网络;
19、若未达到,则返回步骤3b);
20、4)将测试数据输入训练好的头部姿态估计网络,计算第二头部姿态角e2,作为头部姿态估计结果。
21、本发明与现有技术相比,具有如下优点:
22、1.本发明通过特征提取子网络获取人脸特征图,并将该人脸特征图共享给人脸关键点热图模块、头部姿态初步预测模块和姿态角模块,避免了信息的重复提取,缩短了头部姿态估计时间;特别是在多人脸场景下,可以有效地减少多人头部姿态估计的整体计算时间,提高估计效率。
23、2.本发明在姿态角模块和人脸关键点模块之间进行协同学习,姿态角模块从第一人脸关键点中提取低维局部特征和高维全局特征,并将上述特征与第一头部姿态角进行整合,获取精度更高的第二头部姿态角,并通过人脸关键点模块从输入的第二头部姿态角获取辅助坐标,利用该辅助坐标对第一人脸关键点进行修正,不仅可得到精度更高的第二人脸关键点。而且可有效地提高估计精度。
技术特征:
1.一种基于协同学习的头部姿态估计方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的方法,其特征在于,步骤2)建立特征提取子网络中的各模块结构和功能如下:
3.根据权利要求2所述的方法,其特征在于,所述深度残差网络,包括输入层、中间层和输出层,其中:
4.根据权利要求2所述的方法,其特征在于,所述特征聚集层采用基于双线性插值的感兴趣区域对齐roialign方法实现,具体如下:
5.根据权利要求1所述的方法,其特征在于,步骤2)建立特征细化子网络中的各模块结构和功能如下:
6.根据权利要求5所述的方法,其特征在于,所述人脸关键点热图模块利用积分位姿回归得到第一人脸关键点k1,计算公式如下:
7.根据权利要求5所述的方法,其特征在于,所述头部姿态初步预测模块中的第一自适应池化层,是在平均池化的基础上,根据输入输出特征图的大小,自动寻找池化核相应的大小以及步长,实现二维平均自适应池化。
8.根据权利要求1所述的方法,其特征在于,步骤2)建立协同学习子网络中的各模块结构和功能如下:
9.根据权利要求8所述的方法,其特征在于,所述姿态角模块中的解码器,包括顺次连接的三个一维卷积块、第二自适应平均池化层、扁平化函数层和线性层,其中:
10.根据权利要求1所述的方法,其特征在于,步骤3e)中特征提取子网络的损失函数l1、特征细化子网络的损失函数l2和协同学习子网络的损失函数l3,分别表示如下:
技术总结
本发明公开了一种基于协同学习的头部姿态估计方法,主要解决现有技术估计精度较低,前向推理时间较长的问题。其实现方案为:获取人脸图像数据集,划分训练数据和测试数据;构建包括人脸关键点热力图模块、头部姿态初步预测模块和姿态角模块的头部姿态估计网络,在这些模块中共享人脸特征图,在人脸关键点和头部姿态角之间进行协同学习;将训练数据输入到对头部姿态估计网络采用反向传播法对其训练;将测试数据输入训练好的头部姿态估计网络得到头部姿态估计结果。本发明通过共享人脸特征图,缩短了在多人脸场景下头部姿态估计时间,可有效地提高估计效率,并通过协同学习提高了头部姿态角的估计精度,可用于疲劳驾驶检测、智慧课堂行为分析、人机交互。
技术研发人员:王笛,李欣浩,刘锦辉,王泉,万波,罗雪梅,王义峰
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/5/6
- 还没有人留言评论。精彩留言会获得点赞!