一种命名实体识别方法和系统
本发明涉及自然语言处理,尤其是一种利用深度学习模型实现命名实体识别(named entity resolution,ner)的方法和系统。
背景技术:
1、命名实体识别作为自然语言处理领域的关键任务,主要依赖于基于规则的系统、统计学习方法以及初期的机器学习模型。随着深度学习的兴起,尤其是循环神经网络(recurrent neural network,rnn)及其变种如长短期记忆网络(lstm,long-short termmemory)和双向长短期记忆网络(bi-directional lstm,bilstm)在序列数据处理中的有效应用,命名实体识别任务的处理能力得到了显著提升。条件随机场(crf,conditionalrandom field)作为一种序列标注模型,能够在输出层对标签序列进行全局优化,将双向长短期记忆网络和条件随机场结合是一种常见的做法,用于捕获序列数据中的高级特征,并在序列标注任务中达到较好的性能。此外,bert(bidirectional encoderrepresentations from transformers,来自transformers的双向编码器表示)等上下文编码器的引入,通过预训练丰富的语料库来捕捉深层次的双向上下文关系,极大地提升了文本表示的质量,进一步改善了文本表示的效果。
2、对于命名实体识别,目前已知的设计思路包括:
3、(1)基于隐马尔可夫模型(hmm,hidden markov model)的命名实体识别技术
4、隐马尔可夫模型在命名实体识别任务中的应用是基于其对序列数据建模的能力。在命名实体识别中,目标是从文本中识别出具有实际意义的实体,如人名、地理位置、组织名称等。隐马尔可夫模型通过一个隐含的状态序列来建模文本中的实体和非实体部分,其中每个状态对应于特定类型的实体或非实体。这些状态非直接观察到,但与它们相关联的观测(通常是单词或词性标签)是可见的。在隐马尔可夫模型中,状态转移概率表征了从一个实体类型转移到另一个类型的概率,而观测概率则代表了在特定实体状态下观察到特定单词的可能性。通过在一个已标注的数据集上训练,隐马尔可夫模型学习了实体标注的统计模式。然后它可以使用viterbi算法等解码技术,为新的文本序列预测最可能的实体标注。
5、然而,隐马尔可夫模型在处理命名实体识别任务时存在局限性,比如无法有效地使用上下文信息、处理词汇歧义、以及解决数据稀疏性问题等。
6、(2)基于条件随机场模型的命名实体识别技术
7、条件随机场是一种概率图模型,特别适用于标注和分割序列数据,如命名实体识别任务。与隐马尔可夫模型不同,条件随机场是判别式模型,它直接模拟条件概率p(y/x),其中x是输入数据(如句子中的单词序列),y是输出标签(如实体类型)。条件随机场能够考虑到上下文的相互依赖性,因此在序列预测问题上通常优于生成式模型,如隐马尔可夫模型。在命名实体识别任务中,条件随机场通过学习特征函数及其权重来预测实体边界和类别,这些特征函数可以包括词性标签、周围单词的信息、词缀信息等,使条件随机场能够捕捉复杂的、非独立的特征间的关系,如一个词的标签可能受到前后词的标签的影响。
8、条件随机场在命名实体识别中的优势在于其灵活性和强大的特征组合能力,从而能够较好地捕捉和利用文本数据中地依赖关系。此外,条件随机场不像隐马尔可夫模型那样受限于严格的独立性假设,因此在处理具有复杂结构依赖的问题时更为有效。
9、然而,条件随机场也有其局限性。首先,它们通常需要大量的手工特征工程,这可能需要领域专业知识。其次,训练条件随机场模型计算代价高,尤其是在特征空间庞大时,模型参数的优化过程既时间消耗多也计算资源密集。此外,随着序列长度的增加,条件随机场模型的推断过程可能变得更加缓慢。虽然条件随机场在传统的命名实体识别任务中表现优异,但在深度学习的兴起之后,许多基于深度学习的模型,如lstm和transformer,由于其能够自动学习复杂的特征表示且不需要昂贵的特征工程,逐渐在命名实体识别任务中取得了主导地位。
10、(3)基于cnn-lstm-crf的模型命名实体识别技术
11、cnn-lstm-crf框架结合了卷积神经网络(cnn)、长短时记忆网络和条件随机场,可以有效捕捉文本数据的局部特征和长距离依赖关系。它进行命名实体识别主要包括以下步骤:步骤一:进行数据预处理,对文本进行分割、标注和字词嵌入;步骤二:使用卷积神经网络处理字符嵌入,提取每个词的字符级特征,并与词嵌入结合形成最终特征表示;步骤三:使用长短时记忆网络处理词级特征,捕获词与词之间的依赖关系以及长距离的上下文信息;步骤四:在条件随机场层对整个句子的标签序列进行建模,考虑到标签之间的约束,从而预测最可能的实体标签序列;步骤五:在推理时,使用维特比算法在条件随机场层中找出给定输入序列的最优标签序列;步骤六:根据预测的标签序列抽取实体。该方法的不足之处在于,其缺乏分隔符(空格)和强标识符(大写字母),以及训练数据不足,从而导致实体的模糊性。
12、(4)基于提示学习的两阶段命名实体识别技术
13、公开号为cn117236335a的中国专利文献公开了一种基于提示学习的两阶段命名实体识别方法,其提高少样本命名实体识别性能。该方法第一阶段是跨度识别,使用特征编码器(如bert)提取文本特征,并通过线性分类层预测实体边界。第二阶段是跨度分类,结合自然语言模板和预训练语言模型,将识别的实体跨度映射到特定类别。该方法利用了自然语言处理的先验知识,提高了在标注数据有限的情况下的标签依赖性学习,并通过减少需要评估的模板数量优化了预测效率。
14、该方法也存在一些局限性,包括对高质量自然语言模板的依赖,这要求模型需要精心设计以匹配不同的实体类型和上下文。此外,尽管预测效率有所提高,但与传统的一阶段ner模型相比,两阶段流程仍比较耗时。
技术实现思路
1、本发明的发明目的在于:针对上述存在的全部或部分问题,提供一种命名实体识别方法和系统,以提高命名实体识别中模型的鲁棒性和识别精度。
2、本发明采用的技术方案如下:
3、一种命名实体识别方法,其包括:
4、步骤1:对输入的文本进行预处理;
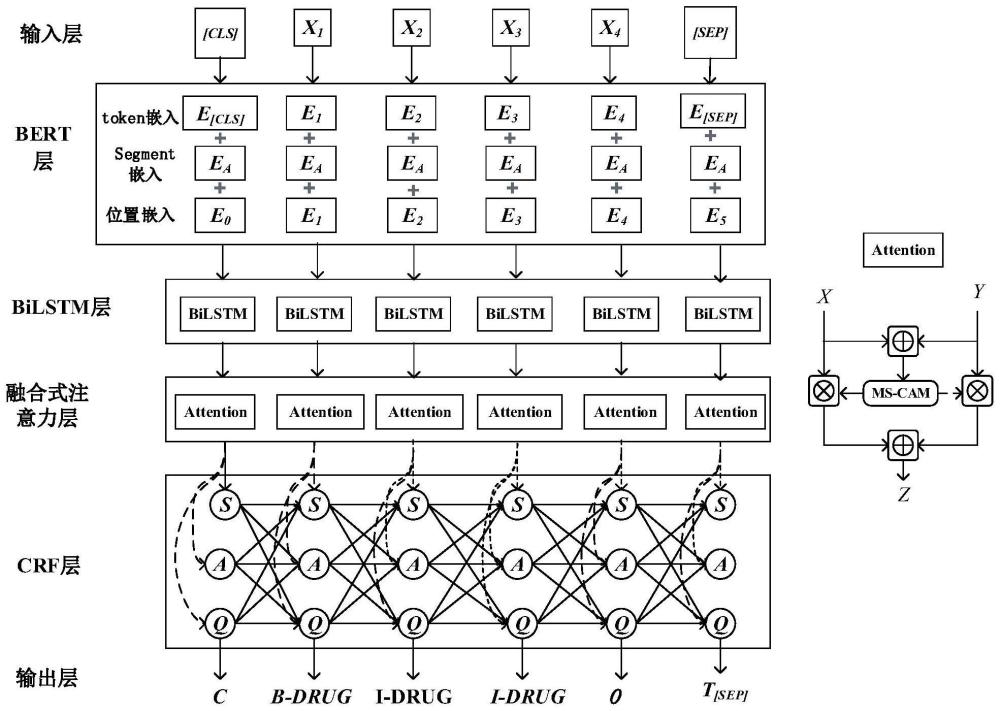
5、步骤2:将经步骤1预处理后的文本输入到嵌入层,嵌入层利用预训练语言模型将预处理后的文本转换为向量表示;
6、步骤3:基于步骤2得到的向量表示进行对抗训练,生成对抗样本;
7、步骤4:将步骤2得到的向量表示和步骤3得到的对抗样本输入到bilstm层,输出表示特征的序列;
8、步骤5:将步骤4得到的序列输入到注意力层以聚焦特征;
9、步骤6:将步骤5得到的序列输入到crf层中,借助crf模型完成对序列的标注。
10、本发明还提供了一种命名实体识别系统,该系统包括逐层连接的预处理层、嵌入层、对抗网络、bilstm层、注意力层和crf层,所述系统被配置为:
11、利用预处理层对输入的文本进行预处理;
12、将预处理层输出的文本输入到嵌入层,并在嵌入层利用预训练语言模型将预处理后的文本转换为向量表示;
13、将嵌入层输出的向量输入到对抗网络进行对抗训练,以生成对抗样本;
14、将嵌入层输出的向量表示和对抗网络输出的对抗样本输入到bilstm层,输出表示特征的序列;
15、将bilstm层输出的序列输入到注意力层以聚焦特征;
16、将注意力层输出的序列输入到crf层中,借助crf模型完成对序列的标注。
17、综上所述,由于采用了上述技术方案,本发明的有益效果是:
18、与现有技术相比,本发明具有显著的优势。首先,预训练语言模型的深度双向表示捕捉到了文本中丰富的上下文信息,而双向长短时记忆网络则能够有效地处理序列数据,捕捉长距离地依赖关系。结合条件随机场层能够使模型学习到标签之间地约束关系,从而提高序列标注的准确性。采用投影梯度下降对抗样本技术进一步增强了模型的泛化能力,使得模型对输入数据的微小扰动没那么敏感,提高了模型面对真实世界、噪声数据的鲁棒性。融合式注意力机制(fusion attention)将来自bert的自注意力和bilstm的序列注意力进行融合,构造一个更为综合的注意力模型,一次性改善命名实体识别的精确度。这种融合了深度语言模型、循环神经网络和条件随机场的模型框架,在特征提取、序列建模和标签解码方面都大幅度超越了早期的模型,尤其是在处理复杂、多变的实体类型和上下文关系时更为有效。
- 还没有人留言评论。精彩留言会获得点赞!