一种基于语义感知的水下图像增强方法
本发明涉及图像处理领域,具体是一种基于语义感知的水下图像增强方法。
背景技术:
1、由于水下图像中物体与相机的距离各不相同,因而导致失真程度存在差异。通常情况下,距离相机较近的物体受到散射等效应的较小影响,失真较轻;相反,距离相机较远的背景则往往伴随着更为严重的雾状效果。
2、现有的处理方法有:1.多传感器融合方法:结合多种传感器数据,如可见光、红外线和激光雷达,以提高对水下环境的感知和图像质量。通过从多个传感器获取的数据中提取一致性信息,可以降低单一传感器由于水下环境的复杂性而引入的噪音。但是:①使用多传感器系统可能增加硬件成本,包括传感器的购置、安装和维护费用;②不同传感器的视场和角度可能不同,需要进行传感器数据的准确对齐。对齐不准确可能导致融合效果降低。
3、2.基于物理模型的方法:考虑水下光传播、吸收和散射等物理特性,建立相应的数学模型进行图像修复。如考虑水下散射和吸收的物理模型,对水下图像进行校正和补偿的散射模型。基于水下图像中存在的大致恒定原理,以改善图像的对比度和清晰度的暗通道先验的方法。使用水下成像的物理特性和光学原理,使得图像增强更为科学和可解释。这使得算法更容易理解和调整。但是该种方法还存在一些局限性:①构建和使用物理模型可能需要深厚的物理学和工程知识,因此对于一般用户而言,这些方法可能较为复杂,不易使用;②物理模型的适用性可能受到水下环境的限制,特定模型可能只在特定条件下表现良好,对于其他场景可能效果较差。
4、3.基于图像变换技术的方法:根据图像处理技术,在空间域,频率域和时间域改变图像像素值到合理范围内的方法。如通过调整图像的直方图,增强图像对比度的直方图均衡化方法。使用各种滤波器进行图像平滑(模糊)或锐化的方法(高斯滤波用于平滑,锐化滤波用于增强边缘)等。该方法不需要深奥的物理模型或复杂的计算过程,因此更易于应用于实际场景。而且往往更加直观,可以通过调整一些参数来进行实时调整,适应不同的水下条件。它的局限性在于①可能在改善图像亮度和对比度的同时,导致一些细节的丢失,特别是在处理极端条件下的水下图像时;②受到输入图像质量的限制,对于极端恶劣的水下环境,可能需要额外的前处理或其他手段来提高输入图像的质量。
5、4.基于深度学习图像方法:使用深度神经网络进行端到端的水下图像增强,包括卷积神经网络(cnn)、生成对抗网络(gan)等。这些方法能够学习复杂的映射关系,提高增强效果。一些方法还对水下图像进行超分辨率处理,提高水下图像的空间分辨率。深度学习方法可以通过端到端学习从输入到输出直接进行映射,无需手工设计特征提取器,简化了整个图像增强流程。但是现有的基于深度学习的水下图像增强方法还存在一定的问题:①水下图像中不同目标以及背景的失真情况不同,统一的网络会导致局部颜色偏离正常的颜色。②目前只用语义分割先验来指导增强结果的方法未能充分运用语义知识,限制了语义感知的性能增益。
6、综上,现有的水下图像增强方法存在局部结果不自然问题,需要改进。
技术实现思路
1、本发明的目的在于提供一种基于语义感知的水下图像增强方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、一种基于语义感知的水下图像增强方法,包括以下步骤:
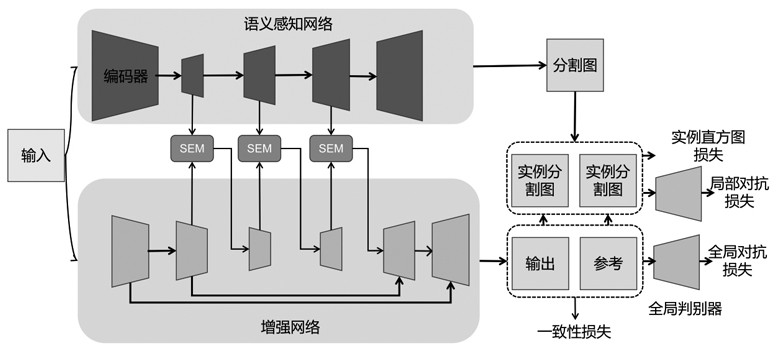
4、步骤1,在语意感知网络中,对输入的原始水下图像i∈rw×h×3结合语义分割,获取分割结果和多尺度维度的中间特征的语义先验,通过语义先验增强原始水下图像,输出给sem模块;是语义分割网络,是分割网络参数;
5、步骤2,sem模块通过跨模态相似度计算语意感知网络输出的图像特征的语义感知,并生成语义感知映射,发送给增强网络;
6、步骤3,在增强网络中,依据语义感知映射获取增强后的原始水下图像,对增强后的原始水下图像进一步增强,获取待用图像,增强包括图像输出、融合输出(第一层降采样图像输出、第二层下采样图像输出、第一层语义信息融合输出、第二层语义信息融合输出、第三层语义信息融合输出);
7、步骤4,对水下图像增强过程中的损失进行计算,损失包括实例直方图损失lih、全局对抗损失lglo、局部对抗损失lloc、一致性损失lre,整体的损失函数由各部分加权求和,,其中和为权重系数,依据整体的损失函数对待用图像进行补偿,获取可用图像。
8、作为本发明再进一步的方案:步骤1中,给一个宽度为w、高度为h的原始水下图像i∈rw×h×3结合语义分割,包括分割结果和多尺度维度的中间特征的语义先验,表示预先训练的语义分割网络,作为语义知识库,分割网络参数被冻结在训练阶段,然后使用m作为输入得到增强后的结果ie:
9、 (1);
10、其中,fenhance表示增强网络,在训练阶段,增强网络参数θe将在m的指导下最小化目标函数,而增强网络参数θe被固定,选择hrnet作为语义知识库。
11、作为本发明再进一步的方案:步骤2中,sem模块通过跨模态相似度计算图像特征的语义感知,并生成语义感知映射,发送给增强网络;利用输出特征作为多尺度语义先验,首先应用卷积层将感知网络特征fs和增强网络特征fe变换到同一维数上,接下来采用一种转移-注意机制来计算注意图,描述如下:
12、 (2);
13、其中,和是卷积层,c是特征通道数,ab是语义感知注意图,表示f s和fe之间的相互关系,然后利用ab得到最终融合特征fo,如下:
14、 (3);
15、其中fn为前馈网络,是卷积层,fo为成为增强网络第二个上采样层的输入。
16、作为本发明再进一步的方案:步骤3中,依据语义感知映射获取增强后的原始水下图像,对于输入为的原始水下图像,第一层降采样将图像输出为大小的第一特征图,第二层下采样将图像输出的第二特征图;随后将第二特征图与语义感知网络的第一层语义信息使用sem融合,输入到增强网络的第三个下采样层得到的第三特征图,第三特征图与第二层语义信息经过融合输入到第一个上采样层中,得到的第四特征图,第四特征图经过第三次融合输入到第二层上采样中得到的第五特征图,最后第五特征图经过最后一层上采样得到大小为的增强图像,其中,上采样层采用3*3卷积+归一化+relu组成,上采样层使用3*3反卷积+归一化+relu的结构。
17、作为本发明再进一步的方案:步骤4中,实例直方图损失lih计算,首先使用语义映射将增强的结果划分为具有不同实例标签的图像补丁,每个补丁都包含一个具有相同标签的单一实例,过程如下:
18、 (4);
19、其中,ie是增强结果,是语义映射的c个通道,最后通过sigmoid函数得到每张增强后图像的实例分割图,因此每个实例直方图可由如下公式表示:
20、 (5);
21、hc是每个实例的直方图表示,α=400,是补丁中第j个像素值,因此,对于真实的水下图像y和网络增强后的图像ie,他们的实例直方图损失可由下式计算:
22、 (6)。
23、作为本发明再进一步的方案:步骤4中,全局对抗损失lglo计算,全局对抗性损失在识别假样本时实现语义感知指导,全局对抗损失公式如下:
24、 (7);
25、其中,g(i)表示原始水下图像输入到网络得到增强的图像,d是判别器。
26、作为本发明再进一步的方案:步骤4中,局部对抗损失lloc计算,对于局部对抗性损失首先使用精细的补丁组p’作为输出的候选假补丁,通过比较p’之间的图像补丁的鉴别结果,(最差的补丁最有可能是“假的”,可以选择来更新鉴别器和生成器的参数),鉴别器利用语义先验来寻找目标伪造区域pg(i),而真实的补丁py仍然是每次从真实的图像中随机裁剪出来的,局部对抗性损失函数的定义为:
27、 (8);
28、作为本发明再进一步的方案:步骤4中,一致性损失lre预测图像和目标图像的像素间损失,一致性损失定义为:
29、 (9)。
30、与现有技术相比,本发明的有益效果是:本发明使用语义感知网络引导的增强网络来细化水下图像,使不同的水下目标均有其正确的颜色,解决了局部欠增强或过增强导致的不自然问题;为了连接两个异构网络,使用sem模块(语义感知嵌入模块)来连接两个网络,使语义感知信息能更好地指导网络。
- 还没有人留言评论。精彩留言会获得点赞!