基于度量学习的文字笔迹显示方法与流程
本发明涉及深度学习和计算机视觉领域,尤其涉及一种基于度量学习的文字笔迹显示方法。
背景技术:
1、笔迹恢复显示是一项旨在根据文字图像恢复出其书写时的笔迹点序列并进行显示的任务。当我们观察一段手写文字时,我们可以看到文字的形状、线条粗细等特征,这些特征由笔迹点序列所决定。而笔迹恢复的目标就是通过分析文字图像,推断出产生该图像的笔迹点序列。
2、笔迹恢复的研究价值在于提供了对手写文字的深入理解和分析能力,为文字研究、反欺诈、文字识别和手写输入等领域带来了更多的应用和改进机会。然而,现有的笔迹方法在对复杂文字,如手写中文的效果欠佳,尤其是容易把文字错误地恢复成其形近字的笔迹点序列,这大大阻碍了这个领域的发展。因此,如何提高模型对不同文字的区分能力,减少其误恢复显示的情况,是这个领域待解决的一大问题。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明公开了基于度量学习的文字笔迹显示方法。所述方法能够实现根据离线文字图像恢复出其在线的书写轨迹,相比现有方法,本方法创新性地使用度量学习的方式,使同一文字的不同图片特征靠近,使不同文字的特征远离,构建出更具判别性的特征空间,减缓了笔迹恢复显示中出现的错字现象。
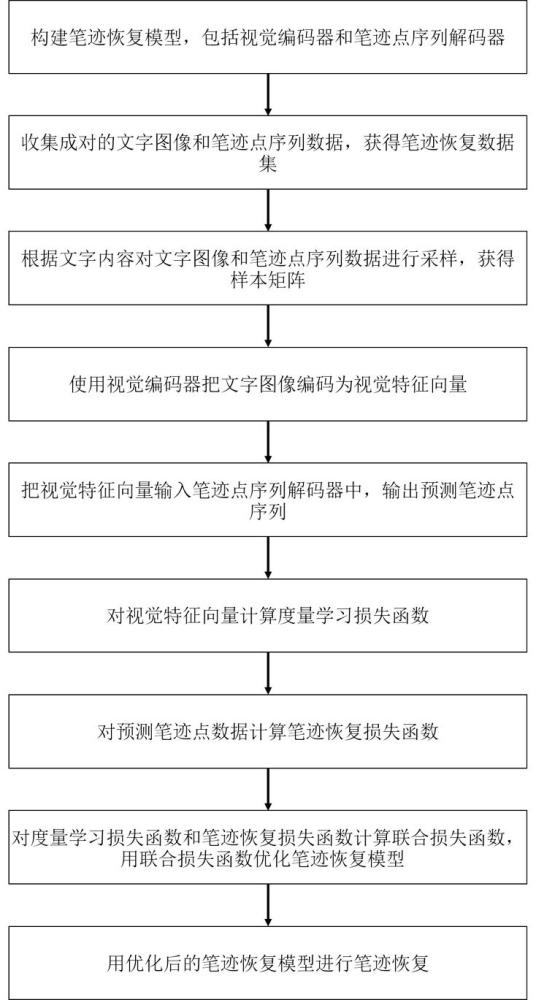
2、本发明的目的是通过如下技术方案实现的,基于度量学习的文字笔迹显示方法,所述方法包括:
3、步骤1,构建笔迹恢复模型,包括视觉编码器和笔迹点序列解码器;
4、步骤2,收集成对的文字图像和笔迹点序列数据,获得笔迹恢复数据集;
5、步骤3,根据文字内容对文字图像和笔迹点序列数据进行采样,获得样本矩阵;
6、步骤4,使用视觉编码器把文字图像编码为视觉特征向量;
7、步骤5,把视觉特征向量输入笔迹点序列解码器中,输出预测笔迹点序列;
8、步骤6,对视觉特征向量计算度量学习损失函数;
9、步骤7,对预测笔迹点数据计算笔迹恢复损失函数;
10、步骤8,对度量学习损失函数和笔迹恢复损失函数计算联合损失函数,用联合损失函数优化笔迹恢复模型;
11、步骤9,用优化后的笔迹恢复模型进行笔迹恢复,对恢复后的笔迹进行显示。
12、所述的收集成对的文字图像和笔迹点序列数据,获得笔迹恢复数据集,包括以下步骤:
13、选定汉字集,多位标注者使用数位板书写汉字集中的常用汉字,记录下每个汉字的文字图像,笔迹点序列,以及该文字的编号;
14、其中,是一个自然数,是一个灰度图,表示图片高度,表示图片宽度,笔迹点序列的数学表达式为:
15、;
16、其中,,表示笔迹点数,表示第i个笔迹点的坐标和状态,是一个五维向量,第一个元素表示第i个笔迹点的横坐标,第二个元素表示第i个笔迹点的纵坐标,后三个元素是一个三维独热向量,即三个值中有且仅有一个为1,另外两个值为0,当第i个笔迹点是笔画起始点时,,当第i个笔迹点不是笔画起始点也不是文字终止点时,,当第i个笔迹点是笔画终止点时,;
17、至此,获得有文字编号标注的,有成对文字图像和笔迹点序列的笔迹恢复数据集。
18、所述的根据文字内容对文字图像和笔迹点序列数据进行采样,获得样本矩阵,包括以下步骤:
19、步骤301,从汉字集随机挑选出k个汉字;
20、步骤302,对挑选出的每个汉字,随机从笔迹恢复数据集中挑选出m对文字图像和笔迹点序列,构成一个k行m列的样本矩阵,矩阵元素赋值的表达式为:
21、;
22、其中,表示样本矩阵,表示挑选出的第i个汉字对应的第j个成对文字图像和笔迹点序列。
23、所述的使用视觉编码器把文字图像编码为视觉特征向量,包括以下步骤:所述的使用视觉编码器把文字图像编码为视觉特征向量,包括以下步骤:
24、把所述的样本矩阵中的所有文字图像输入视觉特征提取器resnet中,获得视觉特征图,再使用自适应池化把视觉特征图池化为一维向量,数学表达式为:
25、;
26、其中,表示挑选出的第i个汉字对应的第j个文字图像,表示挑选出的第i个汉字对应的第j个文字图像的视觉特征向量,是的隐藏层维度。
27、所述的把视觉特征向量输入笔迹点序列解码器中,输出预测笔迹点序列,包括以下步骤:
28、步骤501,把所述的挑选出的第i个汉字对应的第j个文字图像的视觉特征向量输入全连接层,获得初始隐藏层特征,表达式为:
29、;
30、其中,表示初始隐藏层特征,和表示前连接层的可学习参数;
31、步骤502,获取输入笔迹点序列,把的起始插入零向量,并删除最后一个元素,获得输入笔迹点序列;
32、步骤503,把初始隐藏层特征和输入笔迹点序列输入循环神经网络gru中,获得预测笔迹点序列,表达式为:
33、;
34、其中,表示第i个汉字对应的第j个文字图像的预测笔迹点序列,表示输出隐藏层特征。
35、所述的对视觉特征向量计算度量学习损失函数,包括以下步骤:
36、步骤601,计算挑选出的样本的每类汉字的类中心特征;第i个汉字的类中心特征由第i个汉字对应的m个文字图像的视觉特征向量取均值获得,表达式为:
37、;
38、其中,表示第i个汉字的类中心特征;
39、步骤602,计算度量学习损失函数,表达式为:
40、;
41、其中,表示度量学习损失函数,表示a和b的相似度函数,表达式为:
42、;
43、其中,表示向量a,b的相似度函数,表示向量a,b的内积,表示向量a,b的模的乘积。
44、所述的对预测笔迹点数据计算笔迹恢复损失函数,包括以下步骤:
45、计算笔迹恢复损失函数,表达式为:
46、;
47、其中,表示笔迹恢复损失函数,表示所述的第i个汉字对应的第j个文字图像的预测笔迹点序列的第g行第a列的元素,表示所述的第i个汉字对应的第j个笔迹点序列的第g行第a列的元素。
48、所述的对度量学习损失函数和笔迹恢复损失函数计算联合损失函数,用联合损失函数优化笔迹恢复模型,包括以下步骤:
49、步骤801,根据所述的笔迹恢复损失函数和度量学习损失函数计算联合损失函数,数学表达式为:
50、;
51、其中,表示联合损失函数;
52、步骤802,使用adam优化器优化,训练笔迹恢复模型。
53、与现有方法相比,本发明方法的优点在于:本技术提供了,基于度量学习的文字笔迹恢复显示方法。本方法创新性地使用度量学习的方式,使同一文字的不同图片特征靠近,使不同文字的特征远离,使模型提取的文字图像特征更具区分性,减缓了笔迹恢复显示中出现的错字现象。
技术特征:
1.基于度量学习的文字笔迹显示方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于度量学习的文字笔迹显示方法,其特征在于,所述的收集成对的文字图像和笔迹点序列数据,获得笔迹恢复数据集,包括以下步骤:
3.根据权利要求2所述的基于度量学习的文字笔迹显示方法,其特征在于,所述的根据文字内容对文字图像和笔迹点序列数据进行采样,获得样本矩阵,包括以下步骤:
4.根据权利要求3所述的基于度量学习的文字笔迹显示方法,其特征在于,所述的使用视觉编码器把文字图像编码为视觉特征向量,包括以下步骤:
5.根据权利要求4所述的基于度量学习的文字笔迹显示方法,其特征在于,所述的把视觉特征向量输入笔迹点序列解码器中,输出预测笔迹点序列,包括以下步骤:
6.根据权利要求4所述的基于度量学习的文字笔迹显示方法,其特征在于,所述的对视觉特征向量计算度量学习损失函数,包括以下步骤:
7.根据权利要求5所述的基于度量学习的文字笔迹显示方法,其特征在于,所述的对预测笔迹点数据计算笔迹恢复损失函数,包括以下步骤:
8.根据权利要求7所述的基于度量学习的文字笔迹显示方法,其特征在于,所述的对度量学习损失函数和笔迹恢复损失函数计算联合损失函数,用联合损失函数优化笔迹恢复模型,包括以下步骤:
技术总结
本发明公开了基于度量学习的文字笔迹显示方法,包括:构建笔迹恢复模型,包括视觉编码器和笔迹点序列解码器;收集成对的文字图像和笔迹点序列数据,获得笔迹恢复数据集;根据文字内容对文字图像和笔迹点序列数据进行采样,获得样本矩阵;使用视觉编码器把文字图像编码为视觉特征向量;把视觉特征向量输入笔迹点序列解码器中,输出预测笔迹点序列;对视觉特征向量计算度量学习损失函数;对预测笔迹点数据计算笔迹恢复损失函数;对度量学习损失函数和笔迹恢复损失函数计算联合损失函数,用联合损失函数优化笔迹恢复模型;用优化后的笔迹恢复模型进行笔迹恢复,对恢复后的笔迹进行显示。
技术研发人员:修保新
受保护的技术使用者:湖南董因信息技术有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!