基于层间比对的大语言模型训练和使用方法及相关装置
本技术涉及人工智能领域,更具体的说,是涉及基于层间比对的大语言模型训练和使用方法及相关装置。
背景技术:
1、大语言模型是当前人工智能领域最前沿和引人注目的一个模型,大语言模型通过专注分析大量文本数据来学习语言的复杂模式和结构。随着大数据和人工智能技术的不断发展,大语言模型在各个领域的应用日益广泛,例如,健康医疗领域,凭借其强大的知识编码和存储能力、文本理解和生成能力,以及复杂任务的推理能力,有望推动医工交叉产生新一轮科技变革,在医学知识科普与公众健康素养、循证医学与临床辅助决策、药物研发与效果评估等方面具有重要意义。
2、相关技术中大语言模型在处理复杂的任务时,可能产生不准确、偏离既定事实或完全虚构的输出,即幻觉问题。
技术实现思路
1、有鉴于此,本技术提供了一种基于层间比对的大语言模型训练和使用方法及相关装置。
2、为实现上述目的,本技术提供如下技术方案:
3、根据本公开实施例的第一方面,提供一种基于层间比对的大语言模型训练方法,包括:
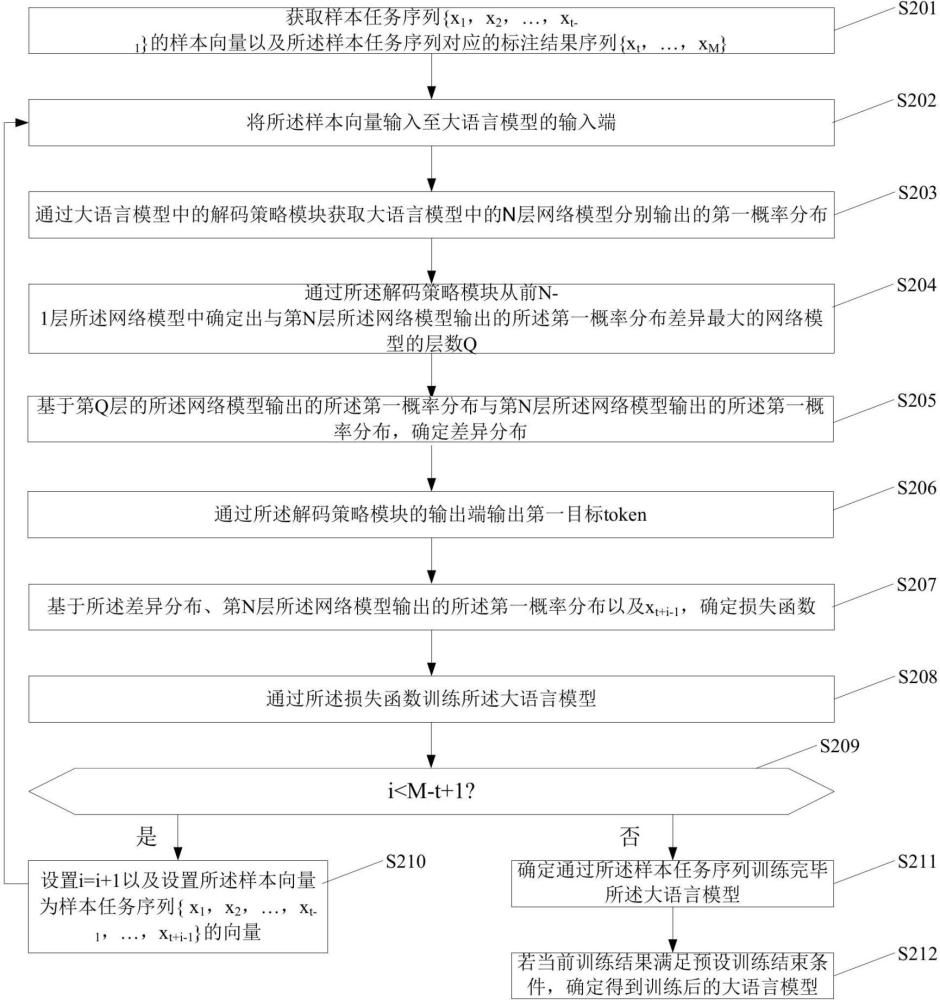
4、获取样本任务序列{}的样本向量以及所述样本任务序列对应的标注结果序列{};所述样本任务序列与所述标注结果序列中的元素为token;
5、将所述样本向量输入至大语言模型的输入端;
6、其中,所述大语言模型包括n层网络模型以及与所述n层网络模型的输出端分别相连的解码策略模块,所述解码策略模块的输出端为所述大语言模型的输出端,第j层的所述网络模型包括第j个transformer模型、与所述第j个transformer模型的第一输出端相连的全连接神经网络以及与所述全连接神经网络的输出端相连的激活函数,所述激活函数的输出端为第j层所述网络模型的输出端,所述第j个transformer模型的第二输出端与第j+1层的所述网络模型包含的第j+1个transformer模型的输入端相连,第一层所述网络模型包含的第一个transformer模型的输入端为所述大语言模型的输入端;n为大于1的整数,1≤j≤n;
7、通过所述解码策略模块获取所述n层网络模型分别输出的第一概率分布;
8、其中,第j层的所述网络模型的第一概率分布包括预设语言集合中各token分别为标注结果序列中第i个token的概率,1≤i≤m-t+1,i的初始值为1;
9、通过所述解码策略模块从前n-1层所述网络模型中确定出与第n层所述网络模型输出的所述第一概率分布差异最大的网络模型的层数q;
10、基于第q层的所述网络模型输出的所述第一概率分布与第n层所述网络模型输出的所述第一概率分布,确定差异分布;
11、通过所述解码策略模块的输出端输出第一目标token,所述第一目标token为预测得到的所述标注结果序列中的第i个token,所述第一目标token为所述差异分布中最大值对应的token;
12、基于所述差异分布、第n层所述网络模型输出的所述第一概率分布以及xt+i-1,确定损失函数;
13、通过所述损失函数训练所述大语言模型;
14、若i小于m-t+1,设置i=i+1以及设置所述样本向量为样本任务序列{}的向量,返回步骤将所述样本向量输入至大语言模型的输入端;
15、若i大于或等于m-t+1,确定通过所述样本任务序列训练完毕所述大语言模型;
16、若当前训练结果满足预设训练结束条件,确定得到训练后的大语言模型。
17、可选的,所述通过所述解码策略模块从前n-1层所述网络模型中确定出与第n层所述网络模型输出的所述第一概率分布差异最大的网络模型的层数q步骤包括:
18、通过以下公式计算得到层数q;
19、
20、其中,jsd(·∥·)为jensen-shannon散度。
21、可选的,所述基于第q层的所述网络模型输出的所述第一概率分布与第n层所述网络模型输出的所述第一概率分布,确定差异分布步骤包括:
22、确定第n层所述网络模型输出的所述第一概率分布中的最大概率为第一数值;
23、从第n层所述网络模型输出的所述第一概率分布中获取大于或等于第二数值的概率值对应的第二目标token,所述第二数值为预设数值与所述第一数值的乘积,所述预设数值为大于0小于或等于1的数值;
24、从第q层的所述网络模型输出的所述第一概率分布中获取由所述第二目标token对应的概率值组成的第二概率分布;
25、从所述第n层所述网络模型输出的所述第一概率分布中获取由所述第二目标token对应的概率值组成的第三概率分布;
26、基于所述第二概率分布与所述第三概率分布,确定所述差异分布。
27、可选的,所述基于所述第二概率分布与所述第三概率分布,确定所述差异分布步骤包括:
28、通过以下公式,计算得到差异分布f;
29、;
30、其中,为所述第三概率分布,为所述第二概率分布;gs为所述预设语言集合中的第s个token,r为所述预设语言集合包含的token的总数目;表示所述第二目标token组成的集合。
31、可选的,所述基于所述差异分布、第n层所述网络模型输出的所述第一概率分布以及xt+i-1,确定损失函数步骤包括:
32、通过以下公式确定损失函数l;
33、;
34、其中,crossentropy(·,·) 为交叉熵函数,为xt+i-1的独热编码,为第一预设值、为第二预设值,v为设定领域的实体对应的token构成的集合,为所述设定领域中多个实体之间的语义关系对应的token构成的集合;
35、其中,;
36、其中,为所述差异分布f,或者,
37、;
38、其中,cu是指第n层所述网络模型输出的所述第一概率分布中概率值为前u的token组成的集合;是指所述设定领域中的实体的token与多个实体之间的语义关系的token构成的集合。
39、可选的,所述设定领域为医学领域,所述预设语言集合包括。
40、根据本公开实施例的第二方面,提供一种基于层间比对的大语言模型的使用方法,包括:
41、获取待测任务序列对应的待测向量;
42、将所述待测向量输入至大语言模型,所述大语言模型是使用第一方面所述的基于层间比对的大语言模型训练方法训练得到的;
43、通过所述大语言模型输出所述待测任务序列对应的预测结果序列,所述预测结果序列包括多个token;
44、通过所述预测结果序列获得预测结果。
45、根据本公开实施例的第三方面,提供一种基于层间比对的大语言模型训练装置,包括:
46、第一获取模块,用于获取样本任务序列{}的样本向量以及所述样本任务序列对应的标注结果序列{};所述样本任务序列与所述标注结果序列中的元素为token;
47、第一输入模块,用于将所述样本向量输入至大语言模型的输入端;
48、其中,所述大语言模型包括n层网络模型以及与所述n层网络模型的输出端分别相连的解码策略模块,所述解码策略模块的输出端为所述大语言模型的输出端,第j层的所述网络模型包括第j个transformer模型、与所述第j个transformer模型的第一输出端相连的全连接神经网络以及与所述全连接神经网络的输出端相连的激活函数,所述激活函数的输出端为第j层所述网络模型的输出端,所述第j个transformer模型的第二输出端与第j+1层的所述网络模型包含的第j+1个transformer模型的输入端相连,第一层所述网络模型包含的第一个transformer模型的输入端为所述大语言模型的输入端;n为大于1的整数,1≤j≤n;
49、第二获取模块,用于通过所述解码策略模块获取所述n层网络模型分别输出的第一概率分布;
50、其中,第j层的所述网络模型的第一概率分布包括预设语言集合中各token分别为标注结果序列中第i个token的概率,1≤i≤m-t+1,i的初始值为1;
51、第一确定模块,用于通过所述解码策略模块从前n-1层所述网络模型中确定出与第n层所述网络模型输出的所述第一概率分布差异最大的网络模型的层数q;
52、第二确定模块,用于基于第q层的所述网络模型输出的所述第一概率分布与第n层所述网络模型输出的所述第一概率分布,确定差异分布;
53、第一输出模块,用于通过所述解码策略模块的输出端输出第一目标token,所述第一目标token为预测得到的所述标注结果序列中的第i个token,所述第一目标token为所述差异分布中最大值对应的token;
54、第三确定模块,用于基于所述差异分布、第n层所述网络模型输出的所述第一概率分布以及xt+i-1,确定损失函数;
55、训练模块,用于通过所述损失函数训练所述大语言模型;
56、设置模块,用于若i小于m-t+1,设置i=i+1以及设置所述样本向量为样本任务序列{}的向量,触发所述第一输入模块;
57、第四确定模块,用于若i大于或等于m-t+1,确定通过所述样本任务序列训练完毕所述大语言模型;
58、第五确定模块,用于若当前训练结果满足预设训练结束条件,确定得到训练后的大语言模型。
59、根据本公开实施例的第四方面,提供一种基于层间比对的大语言模型的使用装置,包括:
60、第三获取模块,用于获取待测任务序列对应的待测向量;
61、第二输入模块,用于将所述待测向量输入至大语言模型,所述大语言模型是第三方面提供的基于层间比对的大语言模型训练装置训练得到的;
62、第二输出模块,用于通过所述大语言模型输出所述待测任务序列对应的预测结果序列,所述预测结果序列包括多个token;
63、第四获取模块,用于通过所述预测结果序列获得预测结果。
64、根据本公开实施例的第五方面,提供一种服务器,包括存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序以实现第一方面或第二方面所述方法的步骤。
65、经由上述的技术方案可知,本技术提供了一种基于层间比对的大语言模型训练方法,获取样本任务序列{}的样本向量以及样本任务序列对应的标注结果序列为{};将样本向量输入至大语言模型的输入端,该大语言模型包括n层网络模型以及与n层网络模型的输出端分别相连的解码策略模块,每一层网络模型包括transformer模型、与transformer模型相连的全连接神经网络以及与全连接神经网络相连的激活函数。通过解码策略模块获取n层网络模型分别输出的第一概率分布,第j层网络模型的第一概率分布包括预设语言集合中各token分别为标注结果序列中第i个token的概率。该大语言模型中的n层网络模型中低层级的网络模型中的transformer模型主要对样本向量的浅层信息进行分析和挖掘,n层网络模型中高层级的网络模型中的transformer模型侧重分析和挖掘样本向量的深层语义信息。也就是说,低层级的网络模型输出的第一概率分布的错误率较高,高层级的网络模型输出的第一概率分布的准确率较高。通过解码策略模块从前n-1层网络模型中确定出与第n层的网络模型输出的第一概率分布差异最大的网络模型的层数q。第n层的网络模型输出的第一概率分布的准确率较高,第q层的网络模型输出的第一概率分布的错误率较高。本技术利用不同隐藏层的网络模型之间输出的第一概率分布的差异,即利用第n层的网络模型输出的第一概率分布和第q层的网络模型输出的第一概率分布之间的差异,确定出第一目标token,所以确定出的第一目标token的准确率较高。大语言模型的输出降低了低层级的网络模型的幻觉认知,增加了高层级网络模型的事实性回答,提高了准确度。
66、基于第q层的网络模型输出的第一概率分布与第n层的网络模型输出的第一概率分布,确定差异分布,该差异分布可以表征大语言模型预测的第i个token的幻觉程度;所以基于差异分布、第n层所述网络模型输出的第一概率分布以及xt+i-1,确定的损失函数能够解决大语言模型的幻觉问题。通过该损失函数训练得到的大语言模型,大大降低了大语言模型的幻觉问题,提高了大语言模型的准确性。
- 还没有人留言评论。精彩留言会获得点赞!